CUDA基础知识
并行计算与串行计算
对于计算密集型任务,当我们有很多计算核心时,每次只调用其中的一个核心进行一次计算任务,这时很浪费的,而这恰恰正式上一节中编写的程序的工作模式。而为了提高计算单元的效率,我们需要将串行工作模式改成并行计算模式,而这就需要用到CUDA和其API接口。
CUDA的基本概念
由于GPU存在成千上万个廉价的计算单元,如果我们能将一个计算任务分解成多个子任务,这样就可以用GPU来完成并行计算,下面来介绍一下在并行计算中的规划方法。
CUDA引用了单指令多线程的并行模式(即每个线程执行相同的数据计算,然后使用一条指令控制从而减少控制器数目和系统复杂度--设想成千上万的线程各自做不同的事情,如果再有线程间通讯/同步,将会是怎样的梦魇),GPU中包含大量的基础计算单元,称为核,每个核都包含了一个逻辑计算单元和一个浮点计算单元,多个核集成在一起被称为流多处理器。
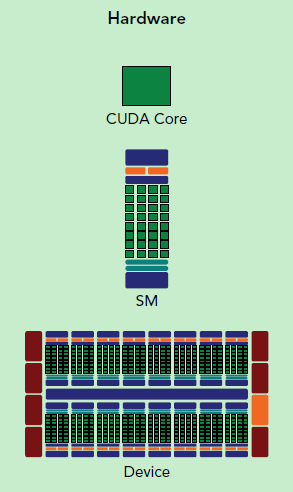
而将每个计算任务分解成多个子任务,称为线程,多个线程被组织成线程块,线程块被分解成大小与一个SM中核数量相同的线程束(大小为32),每个线程束由一个SM负责执行,这些多流处理器的控制单元指挥其他所有核同时在一个线程束的每个线程中执行同一个指令,这是单指令多线程的来源。
GPU与CPU对比
众所周知,CPU也是可以执行并行计算的,那两者有什么区别呢?
首先,CPU是通用计算单元,其核心数目比较少,但是具备处理能力较强,同时其芯片上大部分空间是被设计成用于加速IO的高速缓存。而GPU拥有大量的能力稍弱的核,且每次都是使用一堆核做相同的计算(并不是做一摸一样的计算,而是做类型一样的计算,比如都是加法这样,这是更大的计算任务中的一小部分),与CPU另一个不同之处在于GPU倾向于延迟隐藏,由于GPU上没有很多高速缓存,因此当一个线程束需要的数据不可达时,SM会转向去处理另一个线程束(挂起)。
CUDA计算任务流程
GPU计算中的关键结构是核函数,其产生大量组织成可以分配给SM的计算线程。
因此在计算时,需要加载核函数来创建一个由多个线程块组成的线程网格,同一个网格上的线程共享相同的全局内存空间,每个网格内有很多线程块,而每个线程块由多个线程组成。
一个线程块只会由一个SM来调度,但是一个SM可以调度多个线程块。另外由于SM的资源是有限的,所以其调用线程是由上限的。
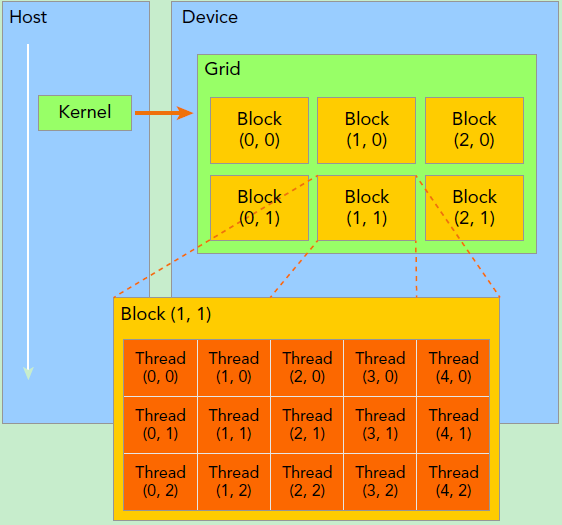
核函数
上面说了核函数是计算的关键函数,下面就来了解一下核函数怎么写。
核函数的声明与标识符
由于GPU是一个外部设备,因此每个函数都需要指明这个函数是在主机上调用(CPU)还是在外部设备上调用(GPU),并根据调用来编译出不同的代码。
为了告知编译器在哪个设备上编译,就需要额外引入标识符,有以下三种标识符
__global__:在CPU调用父函数,子函数在GPU执行(异步)。用__global__修饰的一般就是内核(kernel)函数。
__device__:在GPU调用父函数,子函数在GPU执行。 由__device__修饰的函数可以被由__global__和__device__修饰的函数调用,这种情况是动态并行。
__host__:在CPU调用父函数,子函数在CPU执行(这是默认的标识符)。
一般来说,我们只需要2个修饰词就够了,但是cuda却提供了3个——2个执行位置为GPU。这儿要引入一个“函数执行环境标识符”的概念。父函数调用子函数时,父函数可能运行于CPU或者GPU,相应的子函数也可能运行于CPU或者GPU,但是这绝不是一个2*2的组合关系。因为GPU作为CPU的计算组件,不可以调度CPU去做事,所以不存在父函数运行于GPU,而子函数运行于CPU的情况。
另外,核函数不能带有返回值,因此返回类型通常为void,以及在GPU上的核函数是不能访问主机端CPU可以访问的内存数据。
给出一个声明实例__global__ void run_on_gpu()
核函数的调用
核函数是一种特殊的函数,调用核函数从一个函数名开始,然后以一个包含逗号分割的参数列表,其中网格维度核线程块维度被放在参数列表中(三个尖括号,这是编译器扩展后的)。
形如aKernal <<<2, 2 >>> ();
一个示例
1 |
|