CUDA内存组织与使用
CUDA的内存组织结构
与CPU的内存结构相似,GPU也是存在类似L1、L2之类的高速缓存的东西,而且CUDA为程序员提供更多的控制权,下面列出CUDA的内存模型。
| 内存类型 | 物理位置 | 访问权限 | 可见范围 | 生命周期 |
|---|---|---|---|---|
| 全局内存 | 芯片外 | R/W | 所有线程和主机端 | 主机分配和释放 |
| 常量内存 | 芯片外 | R | 所有线程和主机端 | 主机分配和释放 |
| 纹理和表面内存 | 芯片外 | R | 所有线程和主机端 | 主机分配和释放 |
| 寄存器内存 | 芯片内 | R/W | 单个线程 | 所在线程 |
| 局部内存 | 芯片外 | R/W | 单个线程 | 所在线程 |
| 共享内存 | 芯片内 | R/W | 单个线程块 | 所在线程块 |
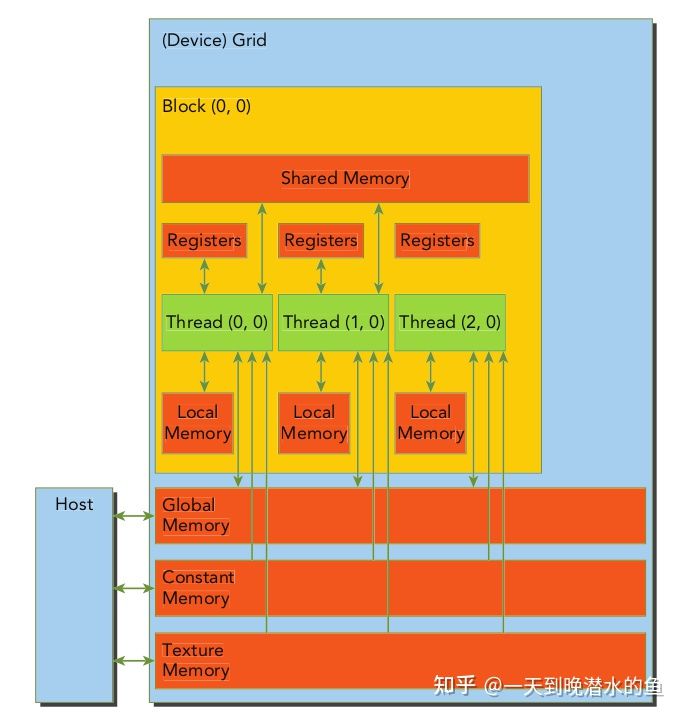
下面对这些内存逐一阐述
全局内存
全局内存是指核函数中所有线程都访问的内存,与C语言中的全局内存概念上存在差异。其容量是最大的,基本上就是显存容量。当然,其访问速度也是相对比较低的。
全局内存的主要目的就是为核函数提供数据、在主机与设备和在设备与设备之间传递数据。
全局内存对所有线程可见,且其是完全由主机端来进行分配和回收的,另外,全局内存是线性排列的。
我们通过使用cudaMalloc()函数可以动态地在全局内存中分配,但是我们也可以在全局内存上分配静态内存,这样的全局的静态全局内存变量必须在所有函数外部定义,即类似与C语言中的全局变量的定义,同样是所有线程可访问,且大小在编译时确定。
定义方法如下所示
1 |
|
在核函数内可以对这些全局的静态全局内存变量进行访问,而不需要显示传递,但是这些变量对主机端不可见。
要想让主机端访问这些变量,或者在主机端和设备之间传递这些数据,需要用到cudaMemcpyToSymbol(symbol:设备符号, src:主机符号, count:长度, offset:设备偏移量, Flag:方向)和cudaMemcpyFromSymbol(dst:主机, symbol:设备, count:长度, offset:设备偏移量,Flag:方向)来进行传递。
常量内存
常量内存是有常量缓存的内存,数量有限,只有64K,其可见范围与生存周期与全局内存一样。不过常量内存仅可读,不可写。但是由于其存在缓存,所以速度会高很多。如果想得到高速的访问速度,需要保证线程束中的线程(线程块中相邻的32个线程)读取相同的常量内存(这样高速缓存才会命中),(每个线程束由一个SM负责处理)。
定义常量内存的方式是使用__constant__关键字来修饰变量,并使用cudaMemcpyToSymbol()来将数据复制到设备端。一般来说,给核函数按指传递的数据就放在常量内存中,但给核函数传递的参数最多在核函数内使用4KB常量内存。
纹理内存与表面内存
纹理内存与表面内存类似与常量内存,有相同的可见范围与生命周期,但是其容量更大,使用方式也略微有些区别。
对比较新的架构,对全局只读内存使用__ldg(*addr)函数可以通过全局只读缓存读取,这样速度会快一些。
寄存器
核函数中定义的不加任何修饰符的变量就位于寄存器,gridDim这些也位于特殊的寄存器,所以访问的很快。在核函数中定义的数组有可能放在寄存器中,这取决于数组大小。
寄存器变量位于芯片中,是访问速度最高的,且与所属线程生命周期一样长。
局部内存
局部内存是全局内存的一部分,所以延迟很高,但是其使用方式跟寄存器内存一致。即在核函数内定义的不加修饰的变量或数组,存的下的位于寄存器,存不下的位于局部内存。
每个线程最多使用512k的局部内存,但是使用过多会降低性能。
共享内存
共享内存位于芯片上,读写速度仅次于寄存器,不过其声明周期是与线程块一样长。线程块内的所有线程都可以访问共享内存。
缓存
一般来说,高速缓存是不能被编程的,其执行过程是自动的,但是其对优化程序速度非常大。
GPU的缓存有L1缓存(SM层次)、L2缓存(设备层次),但是从硬件角度看L1缓存、纹理缓存和共享内存使用的相同的物理结构。
此处仅考虑图灵架构,因为图灵架构是最新的架构。
因此,共享内存其实就可以看成是可以编程的缓存。
SM中的资源数目
一个GPU是由多个SM组成的,一个SM包含以下资源:
- 一定数量的寄存器
- 一定数量的共享内存
- 常量内存缓存
- 纹理和表面内存缓存
- L1缓存
- 线程束调度器,用于对就绪线程发出执行命令
- 执行核心
- 若干整型运算核心INT32
- 若干单精度浮点数运算核心FP32
- 若干双精度浮点数运算核心FP64
- 若干单精度浮点数超越函数的函数单元SFUs
- 若干混合精度的张量核心tensor core
因为一个SM的资源是有限的,所以有些情况下SM中驻留的线程数可能达不到理想的最大值,也就是SM的占有率不足100%。
一般来说,让SM占有率保持在一个值(25%)以上,才可能获得高性能计算。
另外,在图灵架构中,一个SM最多拥有16个线程块,且一个SM中最多有1024个线程(注意一个线程块中最多线程数目也是1024,而一个线程束大小为32)
运行时API查询设备
通过一些运行时API来查询设备资源,可以用于编写针对不同架构的的显卡的程序。
下面给出一个代码示例:
1 |
|