SSTable结构
之前我们也提到过,levelDB的存储单元是SSTable,就即Sorted String Table,是一个持久化的、有序的SortedMap,存储在磁盘上(除了一颗驻留在内存中)。
但是每次进行写操作时,不是直接写入SSTable,而是先写入WAL,即Write Ahead Log。这样做的目的是保存日志,因为可能会短时间内写入多条数据,而由于内存中的表项都是有序的,所以写每条数据之前必须找到其对应位置,且假如此时发生掉电或宕机,那么内存中的数据都没有了。而WAL写入的是硬盘,且其是日志结构,所以只需要进行磁盘的顺序写即可,这样一方面做了持久化,一方面也因为是顺序写不会产生明显的耗时。
SSTable是数据最终落盘的地方,而WAL保存了最近写入的数据,持久化到磁盘上,MemTable则是WAL里数据的内存表示,因为日志的格式不便于查询,在内存中才便于快速查询。
LevelDB的键值对都持久化到扩展名为ldb的文件中,一个ldb文件存储了一定键范围内的键值对,一个ldb文件就是我们的SSTable。
我们需要着重介绍一下这个SSTable。
SSTable的组成结构
源码位置与说明
table/format.h table/format.cc: 编解码BlockHandler,编解码Footer,根据BlockHandler读取一个键的内容
table/block_builder.h table/block_builder.cc: 不断添加键值对,逐渐构建一个Block,主要是添加键值对,然后生成Block的数据
table/block.h table/block.cc: 对一个Block进行读取相关的功能
table/filter_block.h table/filter_block.cc include/leveldb/filter_policy.h util/bloom.cc: 构建布隆过滤器数据,判断键是否存在的
include/leveldb/table.h table/table.cc:读取一个Table的内容,产生迭代器,或者根据一个键读取一个值
include/leveldb/table_builder.h table/table_builder.cc:不断添加键值对,逐渐构建一个Table
db/build.h db/build.cc:根据一个Iterator生成一个SSTable文件
SSTable由以下几部分组成:
Data Block: 存储数据。Data Block有多个,LevelDB将一个ldb文件里的键值对划分为多个Data Block进行存储,每个Data Block具有一定的大小,并且按照键的顺序进行排序,也就是后面一个Data Block的第一个键大于前面一个Data Block的最后一个键,Data Block可支持压缩。Filter Block: 用于过滤数据。也设计成为多个,目前只使用了一个,存储了布隆过滤器的二进制数据。目的是当查找一个键的时候,先查一下这个过滤器,如果不在,则去别处查,这样速度会快很多。Meta Index Block: 存储了指向Filter Block的指针,根据这个指针可以找到某个Filter Block开始的位置,以及其所占用的空间,这个指针的键是Meta Block的名称,值是一个BlockHandler,是一个文件指针。Index Block: 存储了指向每一个Data Block的指针的数组,这个指针的键大于等于对应的Data Block的最后一个键,并且小于下一个Data Block的第一个键,通过Index Block可以实现二分搜索,快速定位键属于哪个Data Block,而不需要扫描所有的Data Block。Footer: 因为Meta Index Block和Index Block的大小是不固定的,没法直接定位到这两个Block,所以最后有一个大小固定的Footer,保存两个BlockHandler,分别指向Meta Index Block和Index Block。
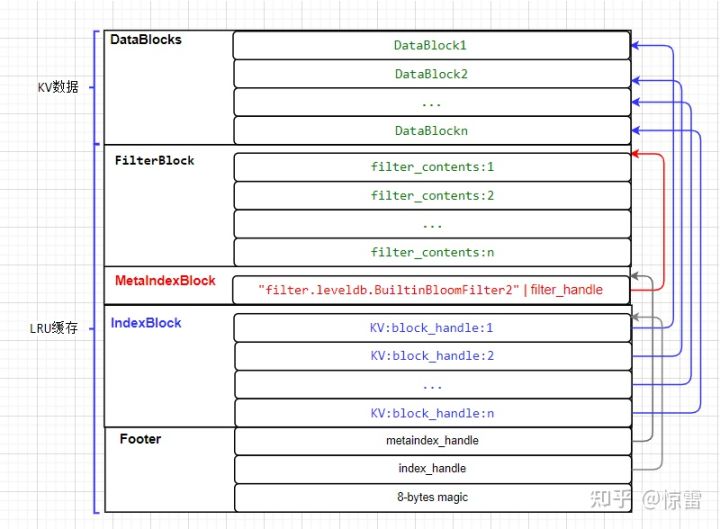
下面我们就来分别介绍每一个组件。
Footer
源码位置 : table/format.h table/format.cc
Footer的位置是固定的,在一个SSTable的结尾。但是由于Footer中使用了一些变长整数,为了确定Footer的位置,因此需要把Footer的大小固定下来,也就是对其做一些填充。所以Footer的格式如下所示

最后最后还存在一个Magic number,这个魔数的作用是用于校验,生成的方法如下所示
1 |
|
但是需要注意的是,这个只是文件中的存储格式,我们在Footer类中是看不到填充和魔数的
我们接下来看一下Footer类的源码,由于Footer类中出现了BlockHandle,我们顺便把BlockHandle的类也看一下。
1 |
|
我们可以看到,这个BlockHandle类其中就只有两个私有成员: offset_和size_,其中offset_表示当前的这个Block位于的位置,而size_则说明了这个块的长度,即通过起始位置+长度这两个坐标就指明了一个Block。
而Footer这个类,其私有成员只有两个BlockHandle,分别指向了metaindex block和index block这两个block。但是我们之前说过在文件中的Footer部分是存在填充和魔数的,可我们在类的成员中并没有看到,这是因为填充和魔数是在将类编码到文件时才会被引入,其实就是Footer::EncodeTo和Footer::DecodeFrom这两个函数。
1 |
|
通过上述代码,我们就能很清晰地看到Footer和BlcokHandle是如何处理的了。
Blcok
其实其余的所有部分都可以看成是Block,其中BlockHandler可以看成是指向Block的指针,可以用其来读取出Blcok的内容。之前也阐述过BlockHandler的结构了,下面我们来看以下Block的结构。
1 |
|
我们发现这个Block的类内部还是十分简洁的,不过还是要关于其私有成员做一些说明。
首先是owned_这个成员,之前我们说过,levelDB的内存管理是由Arena来管理的,当数据小于1kb时直接放入Arena分配的内存块中,否则就自己new一个内存出来存放。这里的owned_成员其实就说明了data中存放的数据是自己new出来的还是Arena分配出来的,如果是自己new出来的,则需要自己进行内存管理。
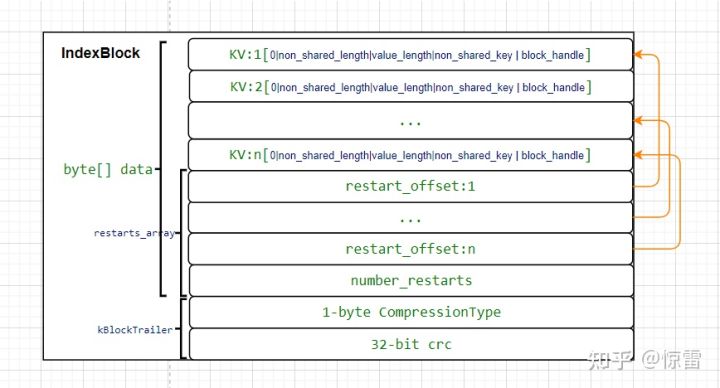
然后还有一个restart_offset_成员,我们先不说这个成员是干什么的,我们先来看一下Block内部的存储结构(此处说的不是Data Block)。首先,所有的有效数据都存放在data_中,但是一个data_肯定存放不止一个数据,而且这些数据大小也未必相同,所以为了能够准确找到这些数据,我们还额外需要记录每条数据的头部的位置,或者成为每条数据头部距离起始位置的偏移,但是数据总数不知道,所以偏移的总数也不知道,因此还需要记录偏移的总数目。就构成了下图所示的结构。
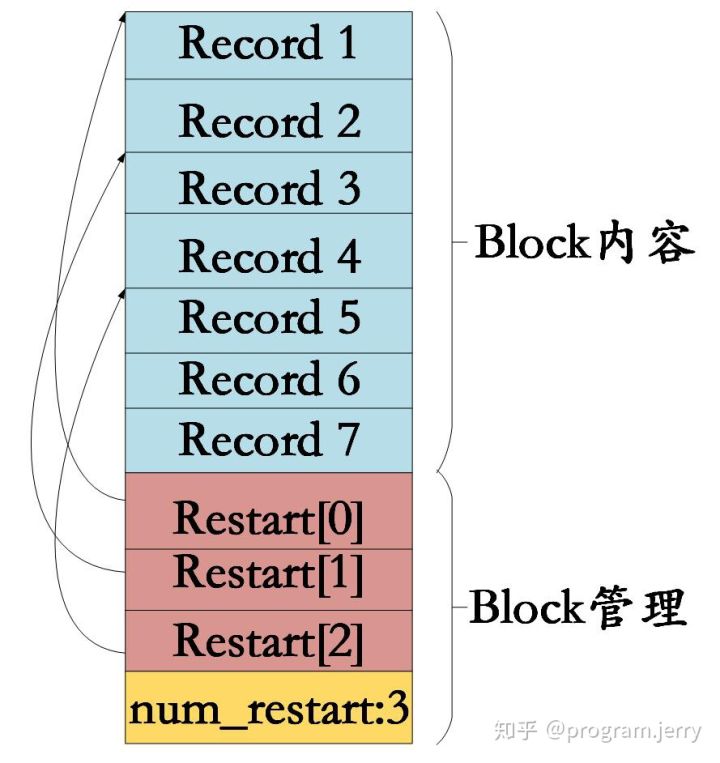
上图可以看成是data_成员的结构(这是Block内部成员的关系,跟xxxhandler无关),前面一部分是数据区,存放了各种数据;往下是偏移区,这部分分别指向了数据,但是我们实际上存放的有序的数据,所以没必要指向所有的数据区的内容(这里后面对Data Block继续详细说明),最后一个是偏移区大小也称为NumRestarts。
由于其他的xxx Block都是一个Block结构,所以都具有Block的成员,所以关于Block的具体实现我们放在后面。
Data Block
我们先来看看Data Block中的数据存放。Data Block的默认大小是4K,但这不是固定的,有可能会超过4K,每次插入一个键值对时都会判断是否超过了4KB,如果插入一个大一点的键值对,就会超过4KB,不过一个键值对只会保存在一个Data Block里面,不会横跨两个Data Block。
由于相邻的键有可能存在相同的前缀,考虑到这一点,LevelDB设置了前缀压缩法,也就是后面的键只需要记录与前一个键不同的部分,以及跟前一个键相同部分的长度,这样通过前一个键就可以还原出后一个键的完整Key,为何要这么设计呢?之所以这样设计是为了节省存储空间,因为Keys之间有相同部分的概率是存在的(这也是之前compare类中的两个用于压缩的方法的用武之地)。
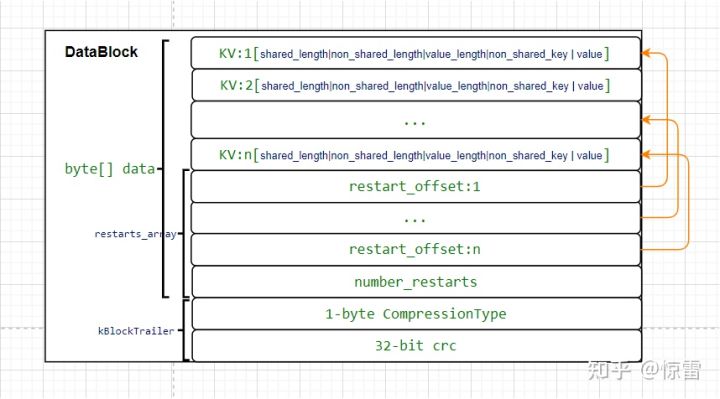
一个KV的格式如下:共享key的长度+非共享key的长度+值value的长度+非共享key的内容+值value。
1 |
|
通过shared_length和前一个键可以得到当前键的前缀,然后根据这个KV里面的后缀non_shared_contents,便可以拼接得到这个完整的键Key。通过这种前缀压缩的方式将多个KV连续存放在Data Block里,但是这样会有一个问题,无论想查找哪一个键Key的值,都需要从Block的第一个键Key开始遍历,依次构造拼接出最终想要的key,那么搜索一个键Key就需要遍历整个Block,这样显然效率会比较低。那怎么办呢?怎么去优化?既然KV的格式已经定了(压缩共享key),要搜索一个Key就需要拼接,那能不能拼接不要无限长,把key一组一组的划分,同一组内key是可以共享的,每一组的第一个key作为起始key就不要共享,该组内后续的key与第一个key共享key,这样key的拼接就是有限次的,查找一个key不需要遍历整个Block,只需要遍历有限个Key,这样效率不会受影响。于是就引入一个叫restart point的概念,记录每个分组的第一个KV的位置,这个位置的KV的shared_length为0,non_shared_length就是整个Key的长度,non_shared_contents就是完整的Key。这个restart point其实就是之前的偏移区中的东西,这也是为什么上图中没有每个数据都被偏移区的指针指到;而我们之前说的data_中数据区,其中就是存放的多个kv。可以参考下面这张图,这里面还有一些crc校验和压缩类型之类的,我们先略过。
下面我们来看一下Block类的一些实现。
1 |
|
这里面的辅助函数就是用于辅助读取每个kv的key和value的,可以解析出shared、non_shared、value_length。
我们来看一下Block与Data Block的关系
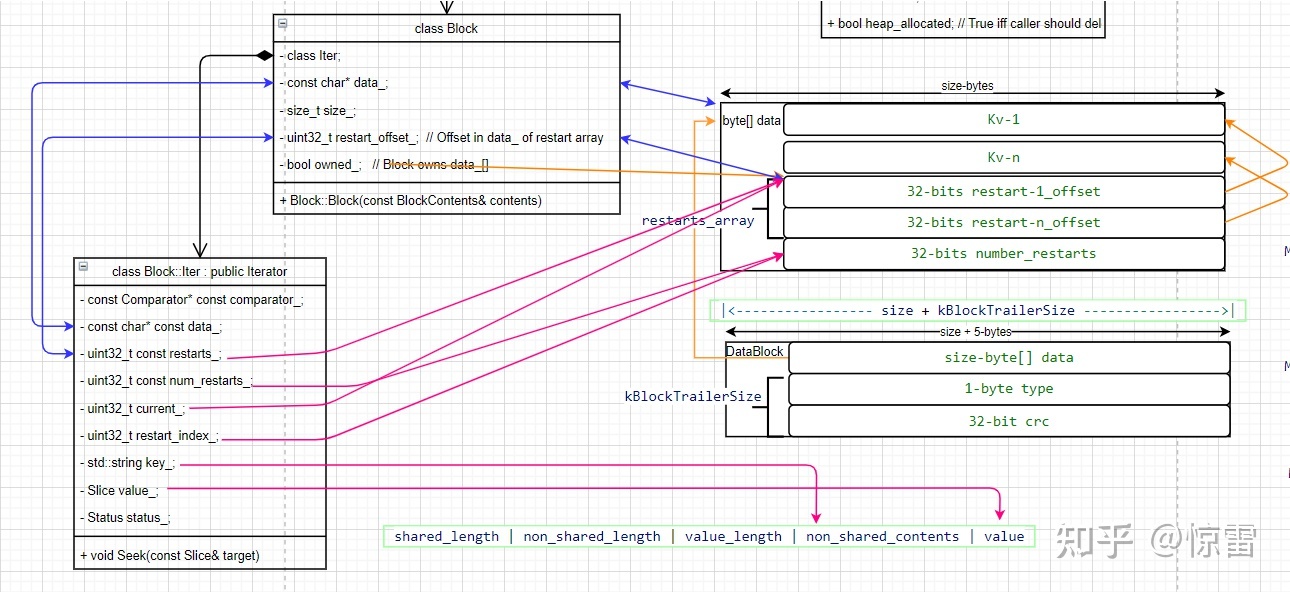
Block中还定义了自己的迭代器类,不过这个东西与Data Block结构无关,主要适用于遍历和构建的,我们后面再说他。
另外需要注意的是,Block本身不涉及kv的插入与删除,其只涉及到Bolck的存储、查找。
从Block的构造函数我们可以看到Block的构建来自于结构体BlockContents,这部分我们后面再说。
1 |
|
Index Block
知道Data Block的结构后,Index Block就非常简单了,它其实就是存储了一个Kv数组,每一个Kv对应一个Data Block,其中键大于等于对应的Data Block中最后一个键,值为一个BlockHandler,可以定位到一个Data Block。Index Block就是Data Block的索引,搜索时可以对Index Block二分搜索,找到键对应的Data Block。
Index Block里面每一个Kv都是一个restart point,也就是没有采用前缀压缩,相当于restart point是一个稠密索引,每一个Kv都有一个restart point对应。
Meta Index Block
和Index Block指向Data Block一样,Meta Index Block指向Filter Block,是Filter Block的索引。不过目前只有一个Filter Block,也就是里面只有一个Kv。键是Filter Block的名字,而值是一个BlockHandler,指向对应的Filter Block。
对于目前存在的Bloom Filter而言,键是filter.leveldb.BuiltinBloomFilter2。

Filter Block
Filter Block就是Meta Index Block中记录的布隆过滤器了。
为什么要在SSTable文件中放置一个布隆过滤器?
我们知道布隆过滤器是一种概率型的数据结构,特点是高效的插入和查询,它的作用是为了快速判定一个Key是否存在。这不是精确判断:如果一个Key判定存在,实际不一定存在;但是,如果判定一个Key不存在,那就一定不存在,其结果是假阳性的。利用这个特性,可以快速的判定一个Key是否存在,如果不存在,就不需要再去查找了,直接返回错误;如果判定存在,则需要进一步查到确定Key是否存在。
在一个SSTable文件中,正常的查找流程如下:
- 对Index Block进行二分搜索,查到键所属的Data Block;
- 读取Data Block,对restart point进行二分搜索,查找对应的键所属的restart point;
- 定位到restart point处,再遍历16个Keys进行键的查找。
理想情况下,Index Block可以缓存在内存中,但是Data Block数据量太大,可能不会缓存在内存中,这样就需要一次磁盘IO,查询效率必然不高。
如何避免磁盘IO呢?怎么才能放到内存中来查找呢?布隆过滤器可以解决这个问题。布隆过滤器比较小,可以缓存在内存中,这样就可以通过布隆过滤器快速判断对应的键有没有在这个SSTable里。如果判断键在SSTable,那也只有很小的概率是键不在这个SSTable里。这是典型的用空间换时间的思想,选择布隆过滤器是因为布隆过滤器的空间占用非常小,可以加载到内存中,进行快速判定。
LevelDB采用了多个布隆过滤器,默认情况下,每2KB的数据开启一个布隆过滤器(如下定义),因此,布隆过滤器也必然组成一个数组结构,last_word就是偏移数组的位置,数组的每个值指向一个布隆过滤器的位置。
由于布隆过滤器不是重点,此处只给出头文件,实现就暂且略过了。
1 |
|
读取一个键的步骤
过上面对SSTable的介绍,来总结一下在SSTable读取一个键的步骤。
要读取一个SSTable,首先需要打开这个SSTable,打开会有以下步骤:
- 读取Footer,根据里面的读取Meta Index Block和Index Block,将Index Block的内容缓存到内存中;
- 根据Meta Index Block读取布隆过滤器的数据,缓存到内存中。
至于具体的读取函数和构建函数我们后面会详细阐述。
读取一个键的步骤如下:
- 根据键对Index Block的restart point进行二分搜索,找到这个键对应的Data Block的BlockHandler;
- 根据BlockHandler的偏移计算出布隆过滤器的编号,读取相应的布隆过滤器;
- 通过布隆过滤器的数据判断键是否存在,不存在就结束,否则读取对应的Data Block;
- 对Data Block里的restart point进行二分搜索,找到搜索键对应的restart point;
- 对这个restart point对应的键进行搜索,最多搜索16个键,找到键或者找不到键。
通过以上步骤可以看到Index Block和布隆过滤器的内容都是缓存在内存里的,所以当一个键在SSTable不存在时,99%的概率是不需要磁盘IO的。
总结
SSTable的实现还是相当复杂的,而且这部分涉及到了很多个类,这部分的技巧主要在数据结构上。SSTable和B+树的思想很像,就好像一个3层的B+树,Footer是根节点,定位到Index Block,Index Block是第二层,可以定位到Data Block。
SSTable的文件布局比较紧凑,查询效率也比较高,不需要像B+树这样复杂,因为SSTable只会整体生成,而不会增量修改,也就是SSTable是只读,这个结构就是利用了这个特性。