Block和SSTable的构建
我们在之前提到了SSTable和内部的各类Block的结构,也初步分析了其在源码中的类级别的组织结构,但是我们也能注意到类结构和实际写入文件的结构是存在明显差异的,所以我们现在就需要进一步了解levelDB是如何构建这些Block与SSTable的。
源码位置与说明:
table/block_builder.cc table/block_builder.h : Block构建相关
Block的构建--BlockBuilder
我们之前看到的Block的类其实只有存储的数据类型、迭代器和查询相关的东西,那么Block获取到的数据是哪里来的呢?也就是哪个类来负责把一个一个kv插入到data_中呢?其实这个类就是BlockBuilder。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class BlockBuilder { private : const Options *options_; std::string buffer_; std::vector<uint32_t > restarts_; int counter_; bool finished_; std::string last_key_; public : explicit BlockBuilder (const Options *options) BlockBuilder (const BlockBuilder &) = delete ; BlockBuilder &operator =(const BlockBuilder &) = delete ; void Reset () void Add (const Slice &key, const Slice &value) Slice Finish () ; size_t CurrentSizeEstimate () const bool empty () const return buffer_.empty (); } };
我们可以看到一个BlockBuilder的作用其实就是不断把key-value添加到缓冲区中,然后在完成构建时返回这个缓冲区。由于没有必须要为每个Block都生成一个BlockBuilder类,所以BlockBuilder类是可以复用的。
下面我们来看一下具体的实现。
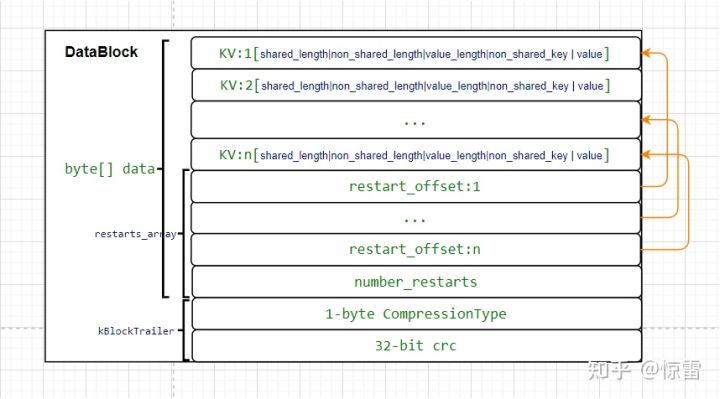
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 BlockBuilder::BlockBuilder (const Options *options) : options_ (options), restarts_ (), counter_ (0 ), finished_ (false ) { assert (options->block_restart_interval >= 1 ); restarts_.push_back (0 ); } void BlockBuilder::Reset () buffer_.clear (); restarts_.clear (); restarts_.push_back (0 ); counter_ = 0 ; finished_ = false ; last_key_.clear (); } size_t BlockBuilder::CurrentSizeEstimate () const return (buffer_.size () + restarts_.size () * sizeof (uint32_t ) + sizeof (uint32_t )); } Slice BlockBuilder::Finish () for (size_t i = 0 ; i < restarts_.size (); i++) { PutFixed32 (&buffer_, restarts_[i]); } PutFixed32 (&buffer_, restarts_.size ()); finished_ = true ; return Slice (buffer_); } void BlockBuilder::Add (const Slice &key, const Slice &value) Slice last_key_piece (last_key_) ; assert (!finished_); assert (counter_ <= options_->block_restart_interval); assert (buffer_.empty () || options_->comparator->Compare (key, last_key_piece) > 0 ); size_t shared = 0 ; if (counter_ < options_->block_restart_interval) { const size_t min_length = std::min (last_key_piece.size (), key.size ()); while ((shared < min_length) && (last_key_piece[shared] == key[shared])) { shared++; } } else { restarts_.push_back (buffer_.size ()); counter_ = 0 ; } const size_t non_shared = key.size () - shared; PutVarint32 (&buffer_, shared); PutVarint32 (&buffer_, non_shared); PutVarint32 (&buffer_, value.size ()); buffer_.append (key.data () + shared, non_shared); buffer_.append (value.data (), value.size ()); last_key_.resize (shared); last_key_.append (key.data () + shared, non_shared); assert (Slice (last_key_) == key); counter_++; }
我们可以看到,BlockBuilder还是很简单的,主要就是创建重启点、插入key-value,不过需要注意的是这个插入key-value的时候需要保证keys是有序的。
Table类
在之前我们讲述SSTable的时候,我们其实是没有提到Table这个类的,因为前面的内容有点多,下面我们就来具体看一下这个类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 class LEVELDB_EXPORT Table{ private : friend class TableCache ; struct Rep ; static Iterator *BlockReader (void *, const ReadOptions &, const Slice &) explicit Table (Rep *rep) : rep_(rep) { Status InternalGet (const ReadOptions &, const Slice &key, void *arg, void (*handle_result)(void *arg, const Slice &k, const Slice &v)) void ReadMeta (const Footer &footer) void ReadFilter (const Slice &filter_handle_value) Rep *const rep_; public : static Status Open (const Options &options, RandomAccessFile *file, uint64_t file_size, Table **table) Table (const Table &) = delete ; Table &operator =(const Table &) = delete ; ~Table (); Iterator *NewIterator (const ReadOptions &) const ; uint64_t ApproximateOffsetOf (const Slice &key) const };
头文件中定义了缓存用的友元类、迭代器这些,说明Table类其实也没有定义怎么构建SSTable,而主要的目的是从文件中读取一个SSTable出来。
由于这其中涉及到了迭代器和缓存类,所以具体的实现我们就先略过,等到后面再详细看。
Table的构建--TableBuilder
Block的构建是通过BlockBuilder类来完成的,而Table的构建则是通过TableBuilder类来完成的。我们先来看一下其头文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 class LEVELDB_EXPORT TableBuilder{ private : bool ok () const return status ().ok (); } void WriteBlock (BlockBuilder *block, BlockHandle *handle) void WriteRawBlock (const Slice &data, CompressionType, BlockHandle *handle) struct Rep ; Rep *rep_; public : TableBuilder (const Options &options, WritableFile *file); TableBuilder (const TableBuilder &) = delete ; TableBuilder &operator =(const TableBuilder &) = delete ; ~TableBuilder (); Status ChangeOptions (const Options &options) ; void Add (const Slice &key, const Slice &value) void Flush () Status status () const ; Status Finish () ; void Abandon () uint64_t NumEntries () const uint64_t FileSize () const };
我们可以看到TableBuilder的头文件中定义了将Key写入文件的部分。以及,虽然这个类中也存在一个类型为Req的东西,但是和Table类中的不是同一个东西,我们看一下其定义。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 struct TableBuilder ::Rep{ Rep (const Options &opt, WritableFile *f) : options (opt), index_block_options (opt), file (f), offset (0 ), data_block (&options), index_block (&index_block_options), num_entries (0 ), closed (false ), filter_block (opt.filter_policy == nullptr ? nullptr : new FilterBlockBuilder (opt.filter_policy)), pending_index_entry (false ) { index_block_options.block_restart_interval = 1 ; } Options options; Options index_block_options; WritableFile *file; uint64_t offset; Status status; BlockBuilder data_block; BlockBuilder index_block; std::string last_key; int64_t num_entries; bool closed; FilterBlockBuilder *filter_block; bool pending_index_entry; BlockHandle pending_handle; std::string compressed_output; };
这个结构体中定义了table中包含的各个部分,这些部分没有直接在Table类中定义,是因为那样就会让Table类十分冗长,使用类内的一个结构体会清晰很多。实际上,TableBuilder类在进行构建的时候也是直接处理这个结构体的。
下面我们来看一下TableBuiler类的具体实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 TableBuilder::TableBuilder (const Options &options, WritableFile *file) : rep_ (new Rep (options, file)) { if (rep_->filter_block != nullptr ) { rep_->filter_block->StartBlock (0 ); } } TableBuilder::~TableBuilder () { assert (rep_->closed); delete rep_->filter_block; delete rep_; } Status TableBuilder::ChangeOptions (const Options &options) if (options.comparator != rep_->options.comparator) { return Status::InvalidArgument ("changing comparator while building table" ); } rep_->options = options; rep_->index_block_options = options; rep_->index_block_options.block_restart_interval = 1 ; return Status::OK (); } void TableBuilder::Add (const Slice &key, const Slice &value) Rep *r = rep_; assert (!r->closed); if (!ok ()) return ; if (r->num_entries > 0 ) { assert (r->options.comparator->Compare (key, Slice (r->last_key)) > 0 ); } if (r->pending_index_entry) { assert (r->data_block.empty ()); r->options.comparator->FindShortestSeparator (&r->last_key, key); std::string handle_encoding; r->pending_handle.EncodeTo (&handle_encoding); r->index_block.Add (r->last_key, Slice (handle_encoding)); r->pending_index_entry = false ; } if (r->filter_block != nullptr ) { r->filter_block->AddKey (key); } r->last_key.assign (key.data (), key.size ()); r->num_entries++; r->data_block.Add (key, value); const size_t estimated_block_size = r->data_block.CurrentSizeEstimate (); if (estimated_block_size >= r->options.block_size) { Flush (); } } void TableBuilder::Flush () Rep *r = rep_; assert (!r->closed); if (!ok ()) return ; if (r->data_block.empty ()) return ; assert (!r->pending_index_entry); WriteBlock (&r->data_block, &r->pending_handle); if (ok ()) { r->pending_index_entry = true ; r->status = r->file->Flush (); } if (r->filter_block != nullptr ) { r->filter_block->StartBlock (r->offset); } } void TableBuilder::WriteBlock (BlockBuilder *block, BlockHandle *handle) assert (ok ()); Rep *r = rep_; Slice raw = block->Finish (); Slice block_contents; CompressionType type = r->options.compression; switch (type) { case kNoCompression: block_contents = raw; break ; case kSnappyCompression: { std::string *compressed = &r->compressed_output; if (port::Snappy_Compress (raw.data (), raw.size (), compressed) && compressed->size () < raw.size () - (raw.size () / 8u )) { block_contents = *compressed; } else { block_contents = raw; type = kNoCompression; } break ; } } WriteRawBlock (block_contents, type, handle); r->compressed_output.clear (); block->Reset (); } void TableBuilder::WriteRawBlock (const Slice &block_contents, CompressionType type, BlockHandle *handle) Rep *r = rep_; handle->set_offset (r->offset); handle->set_size (block_contents.size ()); r->status = r->file->Append (block_contents); if (r->status.ok ()) { char trailer[kBlockTrailerSize]; trailer[0 ] = type; uint32_t crc = crc32c::Value (block_contents.data (), block_contents.size ()); crc = crc32c::Extend (crc, trailer, 1 ); EncodeFixed32 (trailer + 1 , crc32c::Mask (crc)); r->status = r->file->Append (Slice (trailer, kBlockTrailerSize)); if (r->status.ok ()) { r->offset += block_contents.size () + kBlockTrailerSize; } } } Status TableBuilder::status () const { return rep_->status; }Status TableBuilder::Finish () Rep *r = rep_; Flush (); assert (!r->closed); r->closed = true ; BlockHandle filter_block_handle, metaindex_block_handle, index_block_handle; if (ok () && r->filter_block != nullptr ) { WriteRawBlock (r->filter_block->Finish (), kNoCompression, &filter_block_handle); } if (ok ()) { BlockBuilder meta_index_block (&r->options) ; if (r->filter_block != nullptr ) { std::string key = "filter." ; key.append (r->options.filter_policy->Name ()); std::string handle_encoding; filter_block_handle.EncodeTo (&handle_encoding); meta_index_block.Add (key, handle_encoding); } WriteBlock (&meta_index_block, &metaindex_block_handle); } if (ok ()) { if (r->pending_index_entry) { r->options.comparator->FindShortSuccessor (&r->last_key); std::string handle_encoding; r->pending_handle.EncodeTo (&handle_encoding); r->index_block.Add (r->last_key, Slice (handle_encoding)); r->pending_index_entry = false ; } WriteBlock (&r->index_block, &index_block_handle); } if (ok ()) { Footer footer; footer.set_metaindex_handle (metaindex_block_handle); footer.set_index_handle (index_block_handle); std::string footer_encoding; footer.EncodeTo (&footer_encoding); r->status = r->file->Append (footer_encoding); if (r->status.ok ()) { r->offset += footer_encoding.size (); } } return r->status; } void TableBuilder::Abandon () Rep *r = rep_; assert (!r->closed); r->closed = true ; } uint64_t TableBuilder::NumEntries () const return rep_->num_entries; }uint64_t TableBuilder::FileSize () const return rep_->offset; }
通过这个TableBuilder类,我们就可以很清晰地看出一个Table是怎么构建的了。下面给出构建一个Table的流程。
TableBuilder类首先在类内创建出各类BlockBuilder,包括dataBlock,metadataBlock,filterBlock等等。
然后当每次需要插入一个key时就会调用TableBuilder的add方法,这个方法会自动负责处理index_block、重启点、filter_block以及对每个key进行长度压缩(这个压缩不是共享key,而是调用comparator中的FindShortestSeparator方法)。另外TableBuilder类插入key-value会首先写入内存中,只有当内存部分的大小超过一定长度才会写持久化到硬盘。
Flush函数负责将目前的数据区追加写到磁盘中,它会调用WriteBlock函数,注意Flush不会把非data_block的block持久化。
WriteBlock函数是对WriteRawBlock函数的封装。它主要是处理了数据压缩的部分,然后把压缩后的数据和压缩类型以及数据的crc校验码传递给WriteRawBlock函数。
WriteRawBlock函数是真正写入数据的函数,每个Block都由数据区和偏置区、压缩类型以及crc校验组成。
当一个table完成构建时就会调用finish函数,这个函数会负责追加写filter_block、metaindex_block、index_block和Footer。其中写入每个Block时会调用对应handler的encode函数来将每个block编码成字符串。
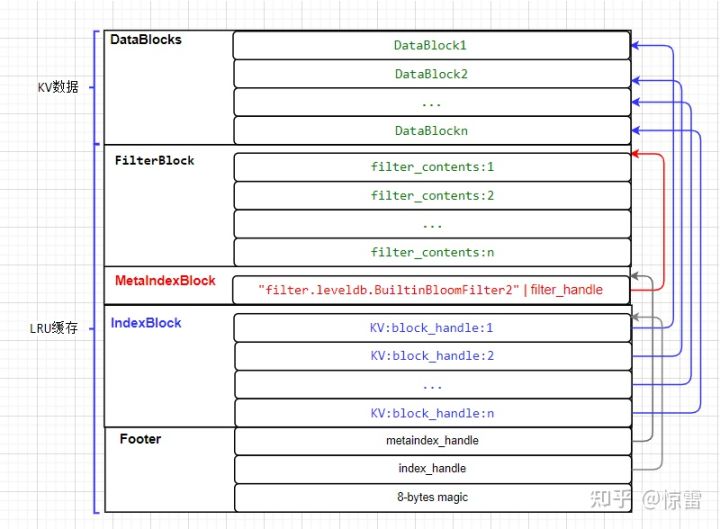
我们继续来审视一下SSTable和Block的结构图,这样我们会更加清楚其结构。
总结
不得不说,Block的统一的设计还是非常的巧妙,所有的Block结构都是一样的,只是提供了统一的接口(Add),内部设计包含了key的前缀压缩、偏置区、重启点等等优化设计。而filterBlock和IndexBlock等等也是包含这些偏置区和重启点的,可能会感觉有些奇怪,因为这些存储的都是过滤器或者是索引。但是由于我们不需要关心这些内部的细节,所以可以看成是数据结构内部优化即可。