迭代器的实现
源码位置与说明
include/leveldb/iterator.h:定义Iterator的接口
table/iterator.cc: 实现CleanUp的功能以及Empty Iterator
table/block.h table/block.cc: 实现了Block Iterator
db/skiplist.h: 实现了skiplist的Iterator
table/two_level_iterator.h table/two_level_iterator.cc: 实现了Two Level Iterator
table/merger.h table/merger.cc: 实现了Merger Iterator
table/iterator_wrapper.cc: 实现一个Iterator包装器,缓存valid()和key()的结果,避免虚函数调用和更好的cache locality
db/db_iter.h db/db_iter.h:实现对整个数据库的迭代器
迭代器在levelDB中,或者说在任何类型中的数据库的作用都是十分显著的。在C++的标准库中,也存在迭代器,两者在概念上是类似的,只是levelDB中的迭代器数目更多,作用也更加明确。主要有以下的作用:
- 按顺序对所有的元素进行迭代
- 处理某一范围内的元素,正序或者逆序
- 定位到某一个特定的元素进行处理。
LevelDB在以下部分使用了迭代器:
- 对MemTable进行迭代
- 对于SSTable的Block进行迭代
- 对整个SSTable进行迭代
- Level File Num Iterator,因为LevelDB的SSTable是分层的,这个Iterator对某一个版本的某一层的SSTable的文件信息进行迭代
- Concatenating Iterator,Level > 0的SSTable是有序的,Concatenating Iterator可以对这些有序的SSTable同时迭代
- 对MemTable、Immutable MemTable和所有的SSTable同时迭代
- DB Iterator对整个数据库进行迭代
以上迭代器的实现,有些是从零开始实现的,有些是组合其它迭代器实现的。为了组合其它迭代器,LevelDB实现了两种迭代器的组合方式:
- Two Level Iterator,可以组合两个迭代器A和B,其中A里面的每个元素可以产生一个迭代器B,可以迭代A,取出一个元素产生迭代器B,然后迭代B,然后再产生A的下一个元素,再产生一个迭代器B,如此往复
- Merger Iterator可以组合多个迭代器,同时对多个迭代器进行迭代,就好像对这些迭代器做了一次归并排序,产生结果
虽然有很多的迭代器(如之前Block中出现的Iter),但是这些迭代器基本上都是继承自一个虚基类--Iterator。所以重点先看一下这个虚基类。
虚基类Iterator
先来看一下其头文件。
1 |
|
Iterator被设置成了纯虚基类,定义了其他种类的迭代器的接口。需要注意的是,Iterator存在清理函数,即在Iterator被销毁时调用这些函数。清理函数需要被注册,保存在一个单项链表中,最后会被统一调用。
然后我们来看一下其具体的实现,由于大部分是纯虚函数,所以实现部分比较少。
1 |
|
迭代器由于受限于本身的逻辑,所以实现还是非常简单的。唯一需要注意的就是关于清理函数的链表结构。
空迭代器EmptyIterator
这里还有一个很有意思的东西,就是其还定义了EmptyIterator这个类,而这个类实际上位于一个匿名名称空间中,名称的作用域被限制在当前文件中,所以外部文件想要创建这个类必须通过NewEmptyIterator这个函数。
我们来具体看一下这部分代码。
1 |
|
总体而言没有啥难度。
其他继承自Iterator的迭代器
有很多迭代器都是继承自Iterator,我们下面来逐一分析。
MemTable Iterator
源码位于 db/memtable.h db/memtable.cc
这个迭代器直接继承自Iterator,用于MemTable内部的迭代,即对Skiplist进行迭代操作。
- 对于Seek操作,其实只需要调用Skiplist的查找操作即可
- 对于Next操作,因为Skiplist的最低层是一个单链表,所以只需要取这个链表的Next即可定位到下一个元素
- 对于Prev操作,稍微复杂一点,需要用查找函数找到当前元素的前一个元素
Block Iterator
源码位于 table/block.h table/block.cc
同样,这个迭代器也是继承自Iterator,用于Block内部的迭代,Block的数据部分是按照键的顺序排列的,所以Next的实现非常简单,只需要解析下一个Kv即可。
不过因为每个Kv的长度是不同的,没法直接定位到具体的某一个Kv,但是对于Seek操作,可以使用restart point来进行快速定位。之前说过restart point指向了某一个键,是一个稀疏索引。可以先对restart point进行二分搜索,找到restart point 对应的键小于等于target最大的那个restart point,如果键存在,则必在这个restart point开始的16个键中,再从这个位置开始搜索,就可以找到对应的键。
二级迭代器Two Level Iterator
源码位于 table/two_level_iterator.h table/two_level_iterator.cc
Two Level Iterator其实就是使用两个Iterator,第一个Iterator是第二个Iterator的索引。先在第一层的Iterator做迭代,每次拿出一个元素后,根据这个元素调用回调函数,生成第二层的一个Iterator,然后第二层的Iterator迭代完成后,再在第一层取下一个元素。
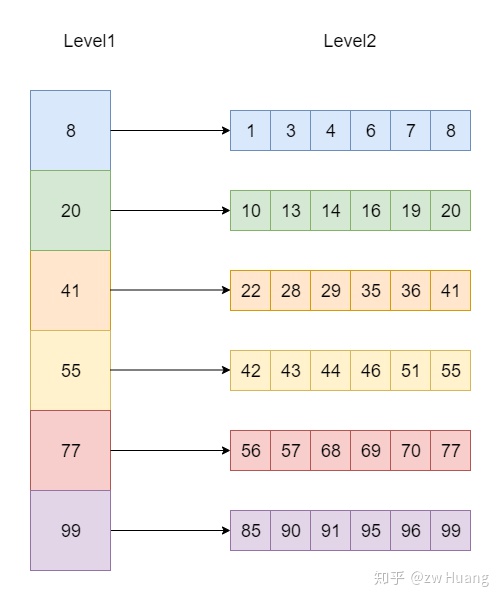
对使用Two Level Iterator有两个要求: 第一层的Iterator的元素是有序排序的; 根据第一层的Iterator生成的第二层的Iterator也是全局有序的,也就是第一层第n个元素生成的第二层Iterator的最大元素小于第一层第n + 1个元素生成的第二层Iterator的最小元素,并且第二层的每个Iterator内部也是有序的。
这个两级Iterator在设计的时候,是设计得非常通用的。但是本质上来说,却是只为Table::Iterator服务。
这个是由于Table的SST文件的格式带来的。因为SST文件关于key/value的内容分为两部分:
- data block
- data block index
前者data block里面存放了所有的数据,而data block index里面存放了检索信息。
所以,data block index是作为第一级iterator,而data block里面的key/value作为第二级iterator。
实际上Two Level Iterator也是继承自Iterator,但是由于其形式特殊,所以单独拿出来说
另外,由于篇幅原因,就不详细剖析其源码了。
其他使用Two Level Iterator的迭代器
SSTable Iterator
源码位于 include/leveldb/table.h table/table.cc
很明显Two Level Iterator就是为SSTable这种结构设计的。
生成迭代器用的这句
1 |
|
Concatenating Iterator
源码位置: db/version_set.cc
除了Table的迭代,Two Level Iterator还用在Concatenating Iterator,这个迭代器可以对某一层(除了level 0)的SSTable进行迭代。第一层是一个Level File Num Iterator,可以返回这一层的SSTable文件信息,而第二层则是SSTable Iterator,使用GetFileIterator可以获取第二层的SSTable Iterator。这样就可以对这一层的所有SSTable里的键从小到大迭代。
合并迭代器Merging Iterator
源码位置: table/merger.h table/merger.cc
Merger Iterator可以用来组合多个Iterator,只需要保证每一个Iterator内部是有序,而不需要每一个Iterator都是全局有序的。Merger Iterator会对所有Iterator进行迭代,就好像归并排序一样。找到每个Iterator头部最小的元素,next时,将最小的元素所在的Iterator next,然后再次找到最小的元素。
看成一个用于归并的迭代器即可
由于这个和归并的过程很类似,也不详细叙述了。当然这个迭代器也是继承自Iterator的,毕竟接口都是一样的嘛。
Iteator整体结构概览
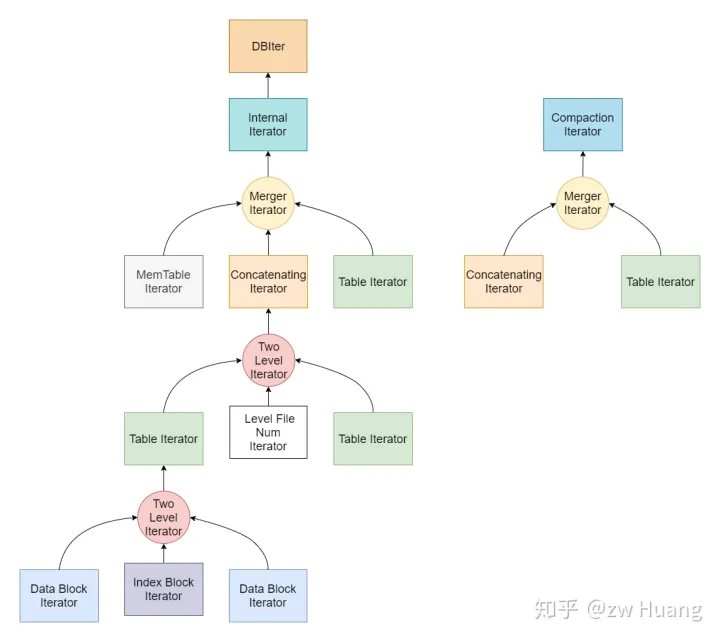
从上图可以看到:
- Two Level Iterator可以将Index Block Iterator和Data Block Iterator组合成一个Table Iterator
- Two Level Iterator可以将Level File Num Iterator和Table Iterator组合成一个Concatenating Iterator,这个Iterator迭代某一Level(Level > 0)的所有SSTable
- Merger Iteator可以组成一个Internal Iterator,对整个数据库里的数据进行迭代,包括MemTable Iterator、Table Iterator(Level 0)和Concatenating Iterator(Level > 0),注意这个Iterator是不会区分版本的,所有版本的数据都能看到
- Internal Iterator做一定的处理后可以生成DBIter迭代整个数据库
- Merger Iterator也可以组成一个Compaction Iterator,包括Table Iterator(Level 0)和Concatenating Iterator(Level > 0),这主要是Compaction时使用。
Internal Iterator是会看到所有数据的,比如一个键覆盖了之前的值,这两个键值对都会看到。所以LevelDB里面还有一个DBIter,封装了对Internal Iterator的访问,根据当前的SequenceNumber,只会看到可见的那个键。DBIter会对Internal Iterator作封装,查找一个Key时会找到可见的SequenceNumber最大的那个Key,Next的话,会跳过所有User Key相同的Internal Key直到一个User Key不同的并且可见的Internal Key,这样迭代整个数据库不会出现重复的User Key。
这里面有些迭代器之前没有涉及到,不过看名字就指导是干什么的了。
总结
- 当想要在一个类中设置析构时的回调函数,可以使用函数指针并设置一个注册函数。
using CleanupFunction = void (*)(void *arg1, void *arg2);这种别名的方式也很有效。且如果需要注册多个回调函数时,可以用单向链表来存储。 - 使用匿名名称空间来对外部文件隐藏类。