classLEVELDB_EXPORT Cache { public: // 构造析构函数... Cache() = default; Cache(const Cache &) = delete; Cache &operator=(const Cache &) = delete; // Destroys all existing entries by calling the "deleter" // function that was passed to the constructor. // 析构函数需要调用deleter函数来销毁所有的entries virtual ~Cache();
// cache中的entry的句柄。 structHandle { };
// Insert a mapping from key->value into the cache and assign it // the specified charge against the total cache capacity. // // Returns a handle that corresponds to the mapping. The caller // must call this->Release(handle) when the returned mapping is no // longer needed. // // When the inserted entry is no longer needed, the key and // value will be passed to "deleter". // Insert将一个键值对映射插入到cache中,并赋予相应的“费用”charge. // Insert返回该映射对应的handle.调用者不再使用时必须调用Release(handle)方法。 // 当不再需要此entry时,键值对会被传到deleter. virtual Handle *Insert(const Slice &key, void *value, size_t charge, void (*deleter)(const Slice &key, void *value))= 0;
// If the cache has no mapping for "key", returns nullptr. // // Else return a handle that corresponds to the mapping. The caller // must call this->Release(handle) when the returned mapping is no // longer needed. // Lookup返回对应key的handle,如果没有则返回nullptr. // 调用者不再使用时必须调用Release(handle)方法。 virtual Handle *Lookup(const Slice &key)= 0;
// Release a mapping returned by a previous Lookup(). // REQUIRES: handle must not have been released yet. // REQUIRES: handle must have been returned by a method on *this. // Release释放一个mapping. virtualvoidRelease(Handle *handle)= 0;
// Return a new numeric id. May be used by multiple clients who are // sharing the same cache to partition the key space. Typically the // client will allocate a new id at startup and prepend the id to // its cache keys. // 返回一个ID,可能被多个共用相同缓存的客户端同时使用 // 他们共享同一个cache来划分key space. // 通常client会在启动时分配一个新的id,并将其id放到缓存的键里。 virtualuint64_tNewId()= 0;
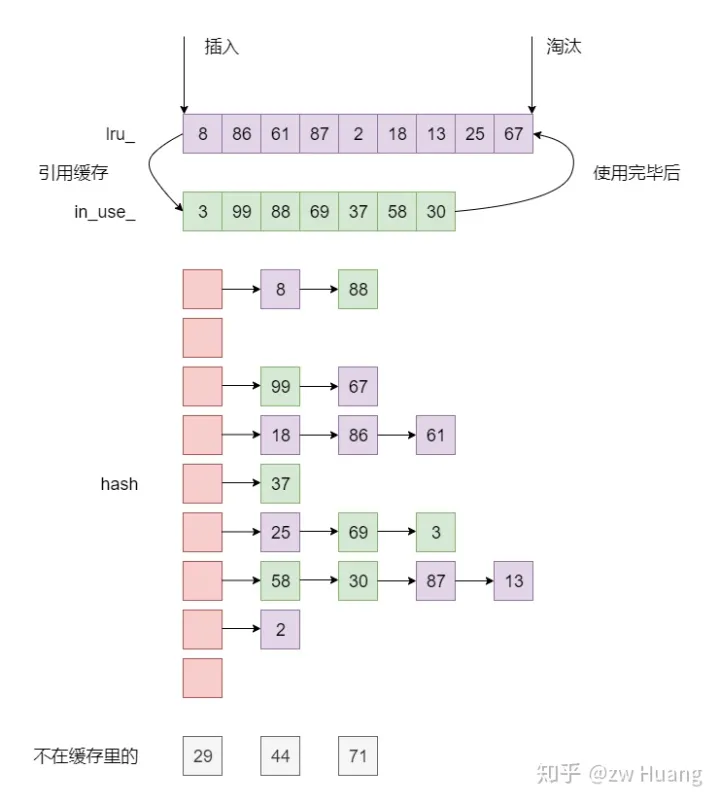
namespace// 位于一个匿名名称空间中 { // LRU cache implementation // // Cache entries have an "in_cache" boolean indicating whether the cache has a // reference on the entry. The only ways that this can become false without the // entry being passed to its "deleter" are via Erase(), via Insert() when // an element with a duplicate key is inserted, or on destruction of the cache. // // The cache keeps two linked lists of items in the cache. All items in the // cache are in one list or the other, and never both. Items still referenced // by clients but erased from the cache are in neither list. The lists are: // - in-use: contains the items currently referenced by clients, in no // particular order. (This list is used for invariant checking. If we // removed the check, elements that would otherwise be on this list could be // left as disconnected singleton lists.) // - LRU: contains the items not currently referenced by clients, in LRU order // Elements are moved between these lists by the Ref() and Unref() methods, // when they detect an element in the cache acquiring or losing its only // external reference.
// An entry is a variable length heap-allocated structure. Entries // are kept in a circular doubly linked list ordered by access time. // 每一个缓存项都保存在一个LRUHandler里 // 即每个资源都是一个handler // 每个handler是变长的堆分配内存 // handlers会被放置在两个双向循环链表中
// Return a pointer to slot that points to a cache entry that // matches key/hash. If there is no such cache entry, return a // pointer to the trailing slot in the corresponding linked list. // 通过hash和key来查找handler,因为hash冲突存在,必须要保留key用于验证 // 如果key不存在,则返回对应的hashtable表项中的最后一个 // 但是我感觉返回的是null,即超尾元素 LRUHandle **FindPointer(const Slice &key, uint32_t hash) { LRUHandle **ptr = &list_[hash & (length_ - 1)]; while (*ptr != nullptr && ((*ptr)->hash != hash || key != (*ptr)->key())) { ptr = &(*ptr)->next_hash; } return ptr; }
// mutex_ protects the following state. mutable port::Mutex mutex_; size_t usage_ GUARDED_BY(mutex_); // 缓存项已占用的容量
// Dummy head of LRU list. // lru.prev is newest entry, lru.next is oldest entry. // Entries have refs==1 and in_cache==true. LRUHandle lru_ GUARDED_BY(mutex_); // 在LRUCache中但未被引用的缓存项链表头哑结点
// Dummy head of in-use list. // Entries are in use by clients, and have refs >= 2 and in_cache==true. LRUHandle in_use_ GUARDED_BY(mutex_); // 正在被使用的缓存项链表链表头哑结点
// 从TableCache中查找Table缓存的函数 Status TableCache::FindTable(uint64_t file_number, uint64_t file_size, Cache::Handle **handle) { Status s; char buf[sizeof(file_number)]; EncodeFixed64(buf, file_number); Slice key(buf, sizeof(buf)); // 查找时的key为filenumber的编码 *handle = cache_->Lookup(key); if (*handle == nullptr) { std::string fname = TableFileName(dbname_, file_number); RandomAccessFile *file = nullptr; Table *table = nullptr; s = env_->NewRandomAccessFile(fname, &file); if (!s.ok()) { std::string old_fname = SSTTableFileName(dbname_, file_number); if (env_->NewRandomAccessFile(old_fname, &file).ok()) { s = Status::OK(); } } if (s.ok()) { s = Table::Open(options_, file, file_size, &table); }
if (!s.ok()) { assert(table == nullptr); delete file; // We do not cache error results so that if the error is transient, // or somebody repairs the file, we recover automatically. } else { TableAndFile *tf = new TableAndFile; tf->file = file; tf->table = table; *handle = cache_->Insert(key, tf, 1, &DeleteEntry); } } return s; }
// Convert an index iterator value (i.e., an encoded BlockHandle) // into an iterator over the contents of the corresponding block. Iterator *Table::BlockReader(void *arg, const ReadOptions &options, const Slice &index_value) { Table *table = reinterpret_cast<Table *>(arg); Cache *block_cache = table->rep_->options.block_cache; Block *block = nullptr; Cache::Handle *cache_handle = nullptr;
BlockHandle handle; Slice input = index_value; Status s = handle.DecodeFrom(&input); // We intentionally allow extra stuff in index_value so that we // can add more features in the future.