// A DB is a persistent ordered map from keys to values. // A DB is safe for concurrent access from multiple threads without // any external synchronization. classLEVELDB_EXPORT DB { public: // 打开一个数据库,把其保存在一个堆分配的指针上,并返回状态 // 这个指针需要用户手动管理 static Status Open(const Options &options, const std::string &name, DB **dbptr);
// 构造析构函数等 DB() = default; DB(const DB &) = delete; DB &operator=(const DB &) = delete; virtual ~DB();
// DB implementations can export properties about their state // via this method. If "property" is a valid property understood by this // DB implementation, fills "*value" with its current value and returns // true. Otherwise returns false. // 通过这个函数,数据库能向外传递他们自身的状态信息 // 前提是给定的属性(propertiy)是合法的 // 有以下合法的property // "leveldb.num-files-at-level<N>" - return the number of files at level <N>, // where <N> is an ASCII representation of a level number (e.g. "0"). // "leveldb.stats" - returns a multi-line string that describes statistics // about the internal operation of the DB. // "leveldb.sstables" - returns a multi-line string that describes all // of the sstables that make up the db contents. // "leveldb.approximate-memory-usage" - returns the approximate number of // bytes of memory in use by the DB. virtualboolGetProperty(const Slice &property, std::string *value)= 0;
// 获取大小估计,其中range是key的范围 // 即获取某个范围内的key-value占用系统的空间 virtualvoidGetApproximateSizes(const Range *range, int n, uint64_t *sizes)= 0;
// Compact the underlying storage for the key range [*begin,*end]. // In particular, deleted and overwritten versions are discarded, // and the data is rearranged to reduce the cost of operations // needed to access the data. This operation should typically only // be invoked by users who understand the underlying implementation. // // begin==nullptr is treated as a key before all keys in the database. // end==nullptr is treated as a key after all keys in the database. // Therefore the following call will compact the entire database: // db->CompactRange(nullptr, nullptr); // 将某个范围内的数据压缩,如果不是很清楚底层是怎么实现的,就不要管它 virtualvoidCompactRange(const Slice *begin, const Slice *end)= 0; };
// Destroy the contents of the specified database. // Be very careful using this method. // // Note: For backwards compatibility, if DestroyDB is unable to list the // database files, Status::OK() will still be returned masking this failure. // 删除一个db LEVELDB_EXPORT Status DestroyDB(const std::string &name, const Options &options);
// If a DB cannot be opened, you may attempt to call this method to // resurrect as much of the contents of the database as possible. // Some data may be lost, so be careful when calling this function // on a database that contains important information. // 尝试修复一个db,有些数据可能会丢失 LEVELDB_EXPORT Status RepairDB(const std::string &dbname, const Options &options);
Status DB::Open(const Options &options, const std::string &dbname, DB **dbptr) { *dbptr = nullptr;
// DBImpl是真正的数据库类,继承自DB DBImpl *impl = newDBImpl(options, dbname); // 先获取锁 impl->mutex_.Lock(); VersionEdit edit; // Recover handles create_if_missing, error_if_exists bool save_manifest = false; // 调用DBImpl::Recover完成MANIFEST的加载和故障恢复 Status s = impl->Recover(&edit, &save_manifest); // 创建日志和相应的MemTable if (s.ok() && impl->mem_ == nullptr) { // Create new log and a corresponding memtable. uint64_t new_log_number = impl->versions_->NewFileNumber(); WritableFile *lfile; s = options.env->NewWritableFile(LogFileName(dbname, new_log_number), &lfile); if (s.ok()) { edit.SetLogNumber(new_log_number); impl->logfile_ = lfile; impl->logfile_number_ = new_log_number; impl->log_ = new log::Writer(lfile); impl->mem_ = newMemTable(impl->internal_comparator_); impl->mem_->Ref(); } } // 如果需要重写MANIFEST文件,那么做一个版本变更,这里面会创建一个新的MANIFEST // 将当前的版本信息写入,然后将edit的内容写入。 if (s.ok() && save_manifest) { edit.SetPrevLogNumber(0); // No older logs needed after recovery. edit.SetLogNumber(impl->logfile_number_); s = impl->versions_->LogAndApply(&edit, &impl->mutex_); } if (s.ok()) { impl->RemoveObsoleteFiles(); impl->MaybeScheduleCompaction(); } // 解锁 impl->mutex_.Unlock(); if (s.ok()) { assert(impl->mem_ != nullptr); *dbptr = impl; } else { delete impl; } return s; }
Status DestroyDB(const std::string &dbname, const Options &options) { Env *env = options.env; std::vector<std::string> filenames; Status result = env->GetChildren(dbname, &filenames); if (!result.ok()) { // Ignore error in case directory does not exist return Status::OK(); }
FileLock *lock; const std::string lockname = LockFileName(dbname); result = env->LockFile(lockname, &lock); if (result.ok()) { uint64_t number; FileType type; for (size_t i = 0; i < filenames.size(); i++) { if (ParseFileName(filenames[i], &number, &type) && type != kDBLockFile) { // Lock file will be deleted at end Status del = env->RemoveFile(dbname + "/" + filenames[i]); if (result.ok() && !del.ok()) { result = del; } } } env->UnlockFile(lock); // Ignore error since state is already gone env->RemoveFile(lockname); env->RemoveDir(dbname); // Ignore error in case dir contains other files } return result; }
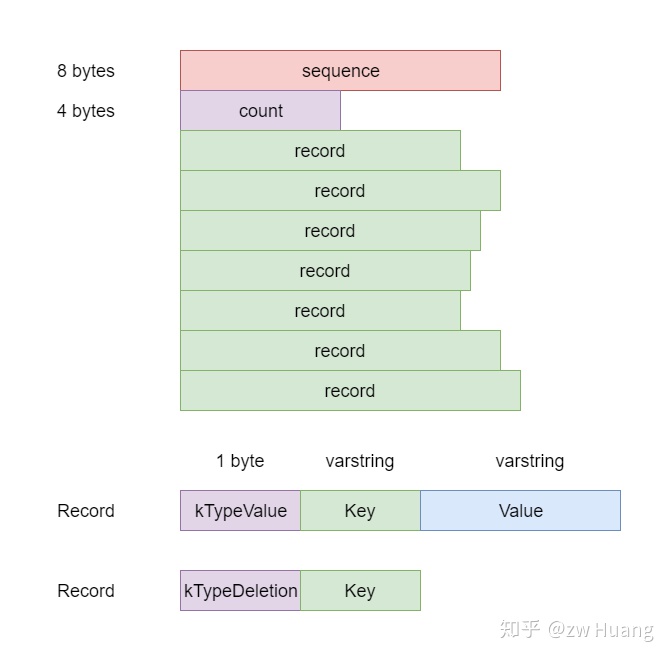
// Copies the operations in "source" to this batch. // // This runs in O(source size) time. However, the constant factor is better // than calling Iterate() over the source batch with a Handler that replicates // the operations into this batch. // 把另一个WriteBatch添加到自身中 voidAppend(const WriteBatch &source);
// Support for iterating over the contents of a batch. // 对每个元素进行解码然后执行对应的删除与插入操作 // 这个是用于批量执行时的接口 Status Iterate(Handler *handler)const;
private: friendclassWriteBatchInternal; // 友元类
// 所有的记录都会存储在这里 std::string rep_; // See comment in write_batch.cc for the format of rep_ };
// DB类的接口 Status Put(const WriteOptions &, const Slice &key, const Slice &value)override; Status Delete(const WriteOptions &, const Slice &key)override; Status Write(const WriteOptions &options, WriteBatch *updates)override; Status Get(const ReadOptions &options, const Slice &key, std::string *value)override; Iterator *NewIterator(const ReadOptions &)override; const Snapshot *GetSnapshot()override; voidReleaseSnapshot(const Snapshot *snapshot)override; boolGetProperty(const Slice &property, std::string *value)override; voidGetApproximateSizes(const Range *range, int n, uint64_t *sizes)override; voidCompactRange(const Slice *begin, const Slice *end)override;
// 其他的功能,用于测试,我们就不管这些了 // Compact any files in the named level that overlap [*begin,*end] voidTEST_CompactRange(int level, const Slice *begin, const Slice *end); // Force current memtable contents to be compacted. Status TEST_CompactMemTable(); // Return an internal iterator over the current state of the database. // The keys of this iterator are internal keys (see format.h). // The returned iterator should be deleted when no longer needed. Iterator *TEST_NewInternalIterator(); // Return the maximum overlapping data (in bytes) at next level for any // file at a level >= 1. int64_tTEST_MaxNextLevelOverlappingBytes(); // Record a sample of bytes read at the specified internal key. // Samples are taken approximately once every config::kReadBytesPeriod // bytes. voidRecordReadSample(Slice key);
// 提供手动压缩时的信息 structManualCompaction { int level; bool done; const InternalKey *begin; // null means beginning of key range const InternalKey *end; // null means end of key range InternalKey tmp_storage; // Used to keep track of compaction progress };
// Per level compaction stats. stats_[level] stores the stats for // compactions that produced data for the specified "level". // 每一层的压缩状态,stats_[level]存储对应层的压缩信息 structCompactionStats { CompactionStats() : micros(0), bytes_read(0), bytes_written(0) {}
// 创建一个新DB对象 // 由于这个方法是私有方法,也不是静态方法,它的作用是被this->Recover调用 // 调用的条件是需要恢复的数据库不存在(所以创建一个新的) Status NewDB();
// Recover the descriptor from persistent storage. May do a significant // amount of work to recover recently logged updates. Any changes to // be made to the descriptor are added to *edit. // 恢复一个数据库,会尝试各种方式 // 实际上这个函数被DB::Open调用 Status Recover(VersionEdit *edit, bool *save_manifest) EXCLUSIVE_LOCKS_REQUIRED(mutex_);
// Compact the in-memory write buffer to disk. Switches to a new // log-file/memtable and writes a new descriptor iff successful. // Errors are recorded in bg_error_. // 合并内存中的memtable并持久化到磁盘中,同时创建一个新的memtable // 被this->DoCompactionWork和this->BackgroundCompaction调用 voidCompactMemTable()EXCLUSIVE_LOCKS_REQUIRED(mutex_);
// 把imm持久化到第0层 // 被this->CompactMemTable和this->RecoverLogFile调用 Status WriteLevel0Table(MemTable *mem, VersionEdit *edit, Version *base) EXCLUSIVE_LOCKS_REQUIRED(mutex_);
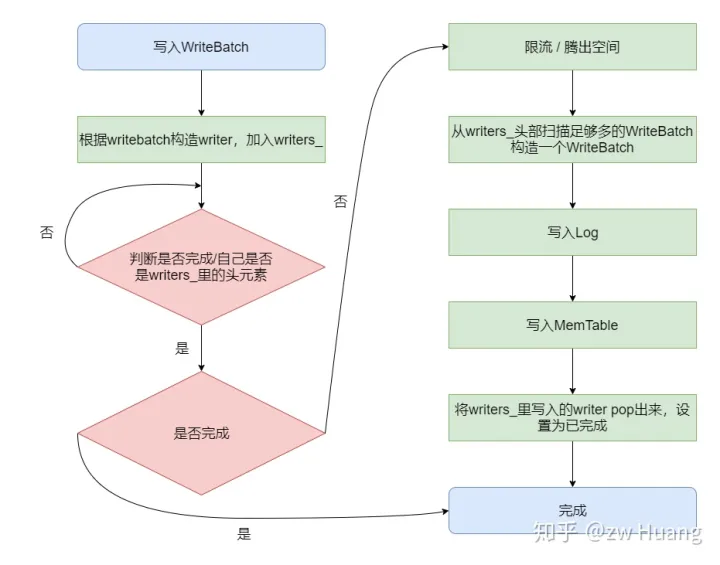
// 确保mem_有空间可以写入(memtable默认4mb就要被持久化了) // 被this->Write调用,保证在写入之前有足够的空间 Status MakeRoomForWrite(bool force /* compact even if there is room? */) EXCLUSIVE_LOCKS_REQUIRED(mutex_); // 这个函数目的是将多个线程写入转化成单个线程写入时用到的(后面具体讲) // 会将多个writebatch拼接成一个writebatch // 被this->Write调用 WriteBatch *BuildBatchGroup(Writer **last_writer) EXCLUSIVE_LOCKS_REQUIRED(mutex_);
// 唤醒所有的线程报错 voidRecordBackgroundError(const Status &s);
// 也是压缩相关的,涉及到打开压缩文件、完成压缩过程、应用压缩到versionEdit Status OpenCompactionOutputFile(CompactionState *compact); Status FinishCompactionOutputFile(CompactionState *compact, Iterator *input); Status InstallCompactionResults(CompactionState *compact) EXCLUSIVE_LOCKS_REQUIRED(mutex_);
// 先检查一下memtable中是否有足够的空间 // 同时获取到最新的序列号 // 注意MakeRoomForWrite函数中如果发现写入太快,会进行休眠限流 Status status = MakeRoomForWrite(updates == nullptr); uint64_t last_sequence = versions_->LastSequence(); Writer *last_writer = &w; // 已经完成写入的准备工作 if (status.ok() && updates != nullptr) { // nullptr batch is for compactions // 调用这个函数来将队列中的多个batch组合成一个batch // 并为这个batch设置好序列号 WriteBatch *write_batch = BuildBatchGroup(&last_writer); WriteBatchInternal::SetSequence(write_batch, last_sequence + 1); last_sequence += WriteBatchInternal::Count(write_batch);
// 下面是正式的写入,会写入log和memtable // { // 注意这一步解锁,很关键,因为接下来的写入可能是一个费时的过程 // 解锁后,其它线程可以Get,其它线程也可以继续将writer // 插入到writers_里面,但是插入后,因为不是头元素,会等待,所以不会冲突 mutex_.Unlock(); status = log_->AddRecord(WriteBatchInternal::Contents(write_batch)); bool sync_error = false; if (status.ok() && options.sync) { status = logfile_->Sync(); if (!status.ok()) { sync_error = true; } } // 然后写入到memtable中 if (status.ok()) { status = WriteBatchInternal::InsertInto(write_batch, mem_); }
// 加锁需要修改全局的SequenceNumber以及writers_ mutex_.Lock(); if (sync_error) { // The state of the log file is indeterminate: the log record we // just added may or may not show up when the DB is re-opened. // So we force the DB into a mode where all future writes fail. // RecordBackgroundError会将错误记录到 bg_error_ 字段中 // 并唤醒 background_work_finished_signal_ 用于向后台任务周知此错误 // 想说明的是:刚才写入到log中的数据在下一次db重新打开时可能不会出现 // 所以让数据库所有的后续写入都失败 RecordBackgroundError(status); } } // 正常情况下tmp_batch_就是write_batch // 因为BuildBatchGroup中tmp_batch_被设置成result,同时返回值也是result(这是指针) if (write_batch == tmp_batch_) tmp_batch_->Clear();
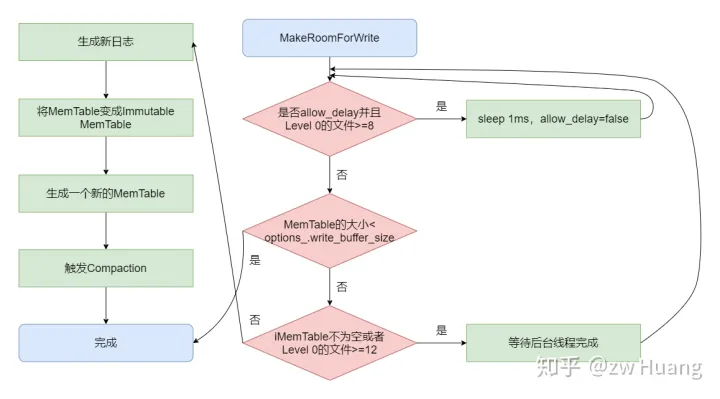
// REQUIRES: mutex_ is held // REQUIRES: this thread is currently at the front of the writer queue // 需要保证锁住,且此函数需要被write_中第一个结点对用的线程调用 // 作用是为写入提供准备,包括限流等策略 Status DBImpl::MakeRoomForWrite(bool force) { mutex_.AssertHeld(); assert(!writers_.empty()); bool allow_delay = !force; Status s; while (true) { if (!bg_error_.ok()) { // Yield previous error s = bg_error_; break; } elseif (allow_delay && versions_->NumLevelFiles(0) >= config::kL0_SlowdownWritesTrigger) { // We are getting close to hitting a hard limit on the number of // L0 files. Rather than delaying a single write by several // seconds when we hit the hard limit, start delaying each // individual write by 1ms to reduce latency variance. Also, // this delay hands over some CPU to the compaction thread in // case it is sharing the same core as the writer. // 如果第0层数目超过限制(默认8),就会sleep 1ms,并在此期间解开锁 // 这有助于压缩线程工作 // 并且此限流策略只会执行一次 mutex_.Unlock(); env_->SleepForMicroseconds(1000); allow_delay = false; // Do not delay a single write more than once mutex_.Lock(); } elseif (!force && (mem_->ApproximateMemoryUsage() <= options_.write_buffer_size)) { // There is room in current memtable // 如果memtable有空间,就直接返回,此时保证了memtable有空间可以写入 break; } elseif (imm_ != nullptr) { // We have filled up the current memtable, but the previous // one is still being compacted, so we wait. // 如果memtable没有空间,且immemtable存在 // 即之前转换的immemtable存在,就一直等,直到上一次的immemtable被持久化 Log(options_.info_log, "Current memtable full; waiting...\n"); background_work_finished_signal_.Wait(); } elseif (versions_->NumLevelFiles(0) >= config::kL0_StopWritesTrigger) { // There are too many level-0 files. // 如果第0层数目太多(默认12),就一直等待,直到满足条件 Log(options_.info_log, "Too many L0 files; waiting...\n"); background_work_finished_signal_.Wait(); } else { // 否则就尝试将一个memtable转换成immemtable来写入 // 同时还需要创建一个新的memtable // 还要触发压缩线程 // Attempt to switch to a new memtable and trigger compaction of old assert(versions_->PrevLogNumber() == 0); uint64_t new_log_number = versions_->NewFileNumber(); WritableFile *lfile = nullptr; s = env_->NewWritableFile(LogFileName(dbname_, new_log_number), &lfile); if (!s.ok()) { // Avoid chewing through file number space in a tight loop. versions_->ReuseFileNumber(new_log_number); break; } delete log_; delete logfile_; logfile_ = lfile; logfile_number_ = new_log_number; log_ = new log::Writer(lfile); imm_ = mem_; has_imm_.store(true, std::memory_order_release); mem_ = newMemTable(internal_comparator_); mem_->Ref(); force = false; // Do not force another compaction if have room MaybeScheduleCompaction(); } } return s; }
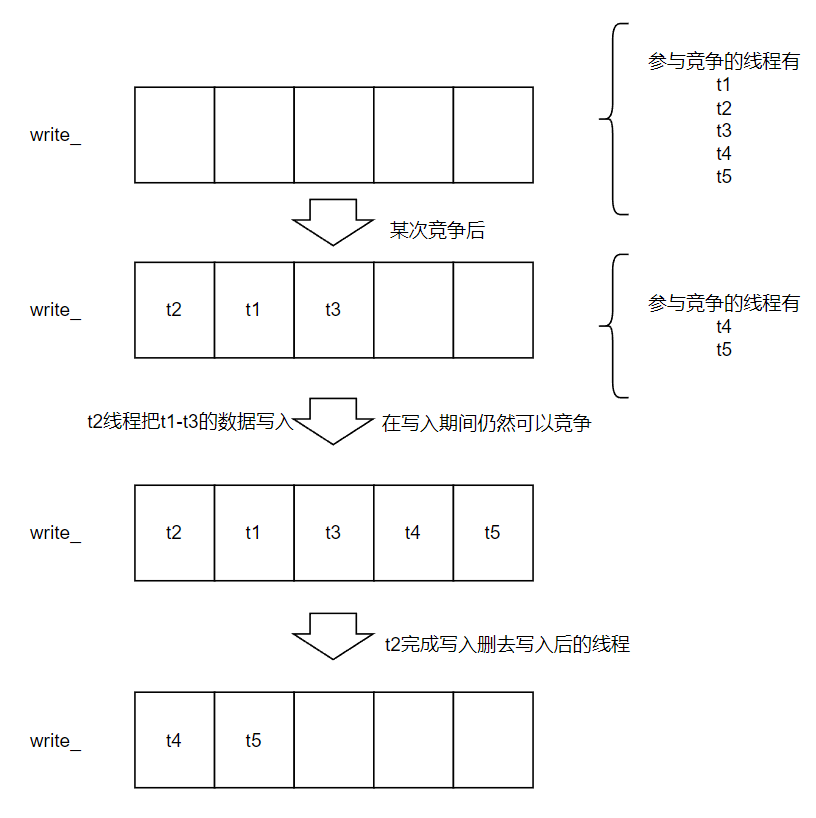
// REQUIRES: Writer list must be non-empty // REQUIRES: First writer must have a non-null batch // 需要保证write_队列非空,且队列中第一个batch也是非空的 WriteBatch *DBImpl::BuildBatchGroup(Writer **last_writer) { mutex_.AssertHeld(); assert(!writers_.empty()); Writer *first = writers_.front(); WriteBatch *result = first->batch; assert(result != nullptr);
// Allow the group to grow up to a maximum size, but if the // original write is small, limit the growth so we do not slow // down the small write too much. size_t max_size = 1 << 20; if (size <= (128 << 10)) { max_size = size + (128 << 10); }
// 然后开始扫描writers_数组,直到满足WriterBatch超过max_size // 或者碰到一个与当前batch的sync不匹配的就结束 *last_writer = first; std::deque<Writer *>::iterator iter = writers_.begin(); ++iter; // Advance past "first" for (; iter != writers_.end(); ++iter) { Writer *w = *iter; if (w->sync && !first->sync) { // Do not include a sync write into a batch handled by a non-sync write. break; }
if (w->batch != nullptr) { size += WriteBatchInternal::ByteSize(w->batch); if (size > max_size) { // Do not make batch too big break; }
// Append to *result if (result == first->batch) { // Switch to temporary batch instead of disturbing caller's batch result = tmp_batch_; assert(WriteBatchInternal::Count(result) == 0); WriteBatchInternal::Append(result, first->batch); } WriteBatchInternal::Append(result, w->batch); } *last_writer = w; } return result; }
// 这个函数的作用是在第level层的f中查找key staticboolMatch(void *arg, int level, FileMetaData *f) { State *state = reinterpret_cast<State *>(arg);
if (state->stats->seek_file == nullptr && state->last_file_read != nullptr) { // We have had more than one seek for this read. Charge the 1st file. state->stats->seek_file = state->last_file_read; state->stats->seek_file_level = state->last_file_read_level; }
// 从TableCache中查找Table缓存的函数 Status TableCache::FindTable(uint64_t file_number, uint64_t file_size, Cache::Handle **handle) { Status s; char buf[sizeof(file_number)]; EncodeFixed64(buf, file_number); Slice key(buf, sizeof(buf)); // 查找时的key为filenumber的编码 *handle = cache_->Lookup(key); if (*handle == nullptr) { std::string fname = TableFileName(dbname_, file_number); RandomAccessFile *file = nullptr; Table *table = nullptr; s = env_->NewRandomAccessFile(fname, &file); if (!s.ok()) { std::string old_fname = SSTTableFileName(dbname_, file_number); if (env_->NewRandomAccessFile(old_fname, &file).ok()) { s = Status::OK(); } } if (s.ok()) { s = Table::Open(options_, file, file_size, &table); }
if (!s.ok()) { assert(table == nullptr); delete file; // We do not cache error results so that if the error is transient, // or somebody repairs the file, we recover automatically. } else { // 找不到就新打开它 TableAndFile *tf = new TableAndFile; tf->file = file; tf->table = table; *handle = cache_->Insert(key, tf, 1, &DeleteEntry); } } return s; }
BlockHandle handle; Slice input = index_value; Status s = handle.DecodeFrom(&input); // We intentionally allow extra stuff in index_value so that we // can add more features in the future.