使用yield将一个递归保持形式不变下转换成非递归
递归函数的可读性高,但是效率不高;非递归函数的效率高,但是可读性会略逊一筹。不过在python中借助yield这个工具我们可以做到鱼和熊掌得兼。
yield的一些技巧
函数内有yield的函数将被作为生成器,当函数执行到yield这里时会将生成器挂起,直到下一次调用。
yield当然还有其他的很多用处和技巧,可以说是python中最重要的概念之一。我们此处用到的技巧主要还是send()方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def a (): yield 1 x = yield yield x b = a() print (next (b)) print (next (b)) print (b.send(2 )) def c (): yield 1 x = yield 2 yield x d = c() print (next (d)) print (next (d)) print (d.send(3 )) print (d.send(4 ))
send()函数可以向生成器中发送数据,但是在调用send前需要保证生成器处于yield的位置上(即保证在send前调用next,当然send本身也是会有一次next调用的,因此send也会返回值 )
关于send的细节此处就不展开了。
在上面代码中的
等效于
其中x = yield为send的接受点,即send进生成器中的数据会被发送给x。
一个递归函数
此处我们就以一个树的访问者模式遍历为例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Node : def __init__ (self, data, left = None , right = None ): self.left = left self.right = right self.data = data class Visitor : def __init__ (self ): ... def visit (self, node ): if node.left is not None : self.visit(node.left) if node.right is not None : self.visit(node.right) print (node.data) t5 = Node(5 ) t4 = Node(4 ) t3 = Node(3 , t4, t5) t2 = Node(2 , t3) t1 = Node(1 ) t0 = Node(0 , t1, t2) v = Visitor v.visit(t0)
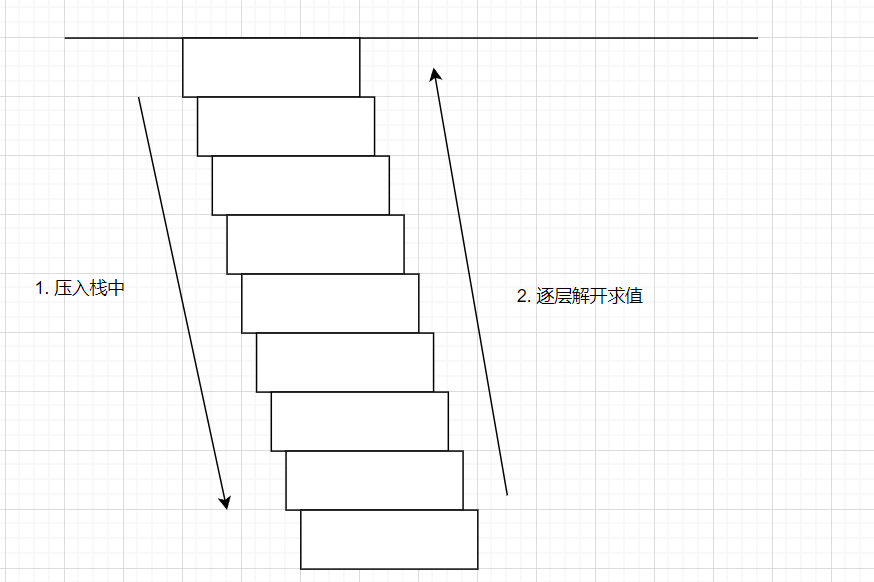
此时的前序遍历是一个递归的操作,但是递归效率不高且会爆栈。递归爆栈的原因也很简单,即它会不断保留当前的状态,直到进入到递归的最内层,并逐层向外解开求值。
每次压入栈中时会把函数涉及到的变量一起压入,这就导致了内存占用过高而爆栈。假如存在一个栈,把结果(数据、起始结点甚至是生成器)全部压进去,然后每次从中pop一个出来根据类型处理,这样就能解决爆栈问题。
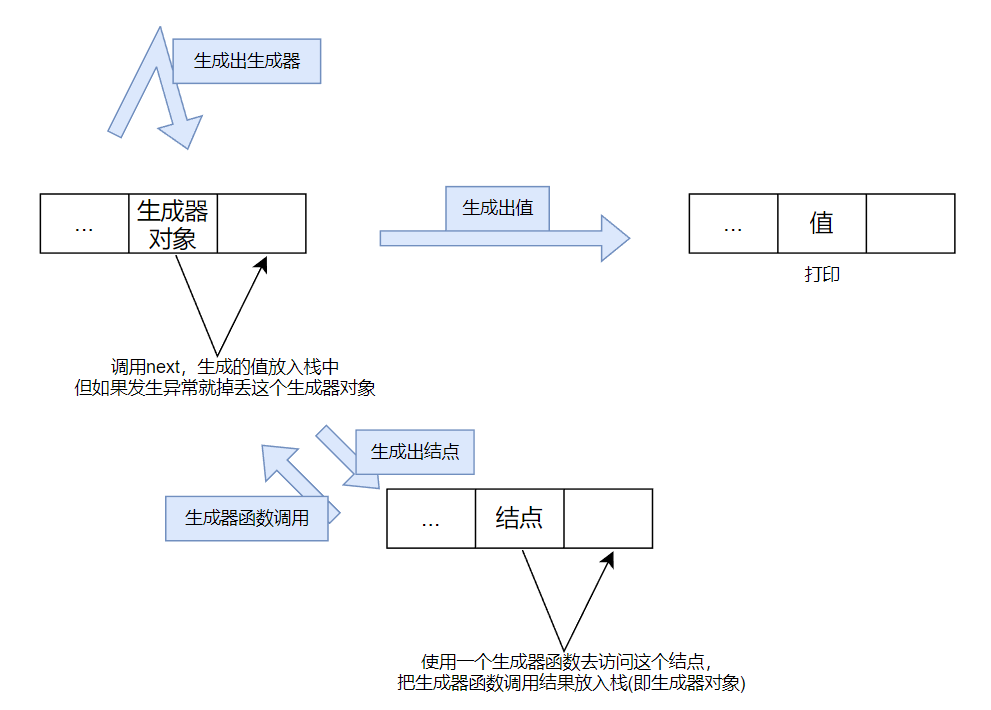
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 from types import GeneratorTypeclass Visitor : def __init__ (self ): ... def visit (self, node ): stack = [node] while stack: try : last = stack[-1 ] if isinstance (last, GeneratorType): stack.append(next (last)) elif isinstance (last, Node): stack.append(self._visit(stack.pop())) else : print (stack.pop()) except StopIteration as e: stack.pop() def _visit (self, node ): if node.left is not None : yield self._visit(node.left) if node.right is not None : yield self._visit(node.right) yield node.data
可以看到,关键的部分还是保持了递归的形式(即自身函数调用自身),但是由于生成器函数并不会直接执行函数内部代码,所以给了可以操作的空间。
可以看成是一个状态机。
一个更高级的例子
当然,上面的例子比较简单,简单的原因是:每个生成器之间不涉及到数据交换,是独立的 。我们接下来看一下需要交换数据的例子,此处我们改写一下斐波那契。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 from types import GeneratorTypeclass Number : def __init__ (self, n ): self.n = n def dec (self, x=1 ): return Number(self.n-x) class Fib : def fib (self, number ): stack = [number] last_result = None while stack: try : last = stack[-1 ] if isinstance (last, GeneratorType): t = last.send(last_result) stack.append(t) last_result = None elif isinstance (last, Number): stack.append(self._fib(stack.pop())) else : last_result = stack.pop() except StopAsyncIteration as e: stack.pop() return last_result def _fib (self, n ): if n.n == 1 or n.n == 2 : yield 1 else : yield (yield self._fib(n.dec())) + (yield self._fib(n.dec(2 ))) def fib_raw (self, n ): if n == 1 or n == 2 : return 1 else : return self.fib_raw(n-1 ) + self.fib_raw(n-2 ) f = Fib() print (f.fib(Number(6 )))print (f.fib_raw(6 ))
每次遇到生成器后都要把last_result设置为None,需要注意last_result的作用有两个:
如果生成出来的还是生成器的话,表示递归继续,此时就send(None)让新生成的迭代器进入send位置
如果生成出来的是值,那么下次循环会把这个值设置成last_result,这个值会被send进最近的一个生成器中,这就完成了递归产生数据的注入
不过这种方式似乎需要保证中间过程值与结果输出值类型不一致呢。
其中
1 2 3 yield (yield n.dec()) + (yield n.dec(2 ))
等效于
1 2 3 4 5 x = yield n.dec() y = yield n.dec(2 ) yield x + y
注意,这种方式本质上只改善了递归的爆栈问题,它的实际运行过程跟递归是一样的。(即,不能当作递归-->非递归的优化方法)
其实就是把递归的整个过程用yield和一个栈来全部模拟一遍啦,且在模拟的时候不改变递归函数形式(即仍然是自身调用自身,但是用生成器惰性求值+挂起的特性来防止不断申请栈空间)