内核线程
这篇是lab4的内容,主要就是实现一下创建内核线程,摆脱单线程运行。
0X00 环境准备
本lab基于之前所有实现的lab。
lab2和lab3完成了对内存的虚拟化,但整个控制流还是一条线串行执行。lab4将在此基础上进行CPU的虚拟化,即让ucore实现分时共享CPU,实现多条控制流能够并发执行 。从某种程度上,我们可以把控制流看作是一个内核线程。本次实验将首先接触的是内核线程的管理。内核线程是一种特殊的进程,内核线程与用户进程的区别有两个:内核线程只运行在内核态而用户进程会在在用户态和内核态交替运行;所有内核线程直接使用共同的ucore内核内存空间,不需为每个内核线程维护单独的内存空间而用户进程需要维护各自的用户内存空间。从内存空间占用情况这个角度上看,我们可以把线程看作是一种共享内存空间的轻量级进程。
为了实现内核线程,需要设计管理线程的数据结构,即进程控制块 (在这里也可叫做线程控制块)。如果要让内核线程运行,我们首先要创建内核线程对应的进程控制块,还需把这些进程控制块通过链表连在一起,便于随时进行插入,删除和查找操作等进程管理事务。这个链表就是进程控制块链表 。然后在通过调度器(scheduler)来让不同的内核线程在不同的时间段占用CPU执行 ,实现对CPU的分时共享。这就是整个lab4做的工作。
由于进程(此处是线程)是通过进程描述块来描述的,所以切换进程的运行本质上也就是更换进程描述块。下面是进程描述块的结构:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 struct proc_struct { enum proc_state state ; int pid; int runs; uintptr_t kstack; volatile bool need_resched; struct proc_struct *parent ; struct mm_struct *mm ; struct context context ; struct trapframe *tf ; uintptr_t cr3; uint32_t flags; char name[PROC_NAME_LEN + 1 ]; list_entry_t list_link; list_entry_t hash_link; };
下面内容来自指导书,解释更加详细
mm:内存管理的信息,包括内存映射列表、页表指针等。mm成员变量在lab3中用于虚存管理。但在实际OS中,内核线程常驻内存,不需要考虑swap page问题,在lab5中涉及到了用户进程,才考虑进程用户内存空间的swap page问题,mm才会发挥作用 。所以在lab4中mm对于内核线程就没有用了,这样内核线程的proc_struct的成员变量*mm=0是合理的。mm里有个很重要的项pgdir,记录的是该进程使用的一级页表的物理地址。由于*mm=NULL,所以在proc_struct数据结构中需要有一个代替pgdir项来记录页表起始地址,这就是proc_struct数据结构中的cr3成员变量。 state:进程所处的状态。 parent:用户进程的父进程(创建它的进程)。在所有进程中,只有一个进程没有父进程,就是内核创建的第一个内核线程idleproc。内核根据这个父子关系建立一个树形结构,用于维护一些特殊的操作,例如确定某个进程是否可以对另外一个进程进行某种操作等等。 context:进程的上下文,用于进程切换(参见switch.S)。在 uCore中,所有的进程在内核中也是相对独立的(例如独立的内核堆栈以及上下文等等)。使用 context 保存寄存器的目的就在于在内核态中能够进行上下文之间的切换。实际利用context进行上下文切换的函数是在kern/process/switch.S中定义switch_to。 tf:中断帧的指针,总是指向内核栈的某个位置:当进程从用户空间跳到内核空间时,中断帧记录了进程在被中断前的状态。当内核需要跳回用户空间时,需要调整中断帧以恢复让进程继续执行的各寄存器值。除此之外,uCore内核允许嵌套中断。因此为了保证嵌套中断发生时tf 总是能够指向当前的trapframe,uCore 在内核栈上维护了 tf 的链,可以参考trap.c::trap函数做进一步的了解。 cr3: cr3 保存页表的物理地址,目的就是进程切换的时候方便直接使用 lcr3实现页表切换,避免每次都根据 mm 来计算 cr3。mm数据结构是用来实现用户空间的虚存管理的,但是内核线程没有用户空间,它执行的只是内核中的一小段代码(通常是一小段函数),所以它没有mm 结构,也就是NULL。当某个进程是一个普通用户态进程的时候,PCB 中的 cr3 就是 mm 中页表(pgdir)的物理地址;而当它是内核线程的时候,cr3 等于boot_cr3。而boot_cr3指向了uCore启动时建立好的内核虚拟空间的页目录表首地址。 kstack: 每个线程都有一个内核栈,并且位于内核地址空间的不同位置。对于内核线程,该栈就是运行时的程序使用的栈;而对于普通进程,该栈是发生特权级改变的时候使保存被打断的硬件信息用的栈。uCore在创建进程时分配了 2 个连续的物理页(参见memlayout.h中KSTACKSIZE的定义)作为内核栈的空间。这个栈很小,所以内核中的代码应该尽可能的紧凑,并且避免在栈上分配大的数据结构,以免栈溢出,导致系统崩溃。kstack记录了分配给该进程/线程的内核栈的位置。主要作用有以下几点。首先,当内核准备从一个进程切换到另一个的时候,需要根据kstack 的值正确的设置好 tss (可以回顾一下在实验一中讲述的 tss 在中断处理过程中的作用),以便在进程切换以后再发生中断时能够使用正确的栈。其次,内核栈位于内核地址空间,并且是不共享的(每个线程都拥有自己的内核栈),因此不受到 mm 的管理,当进程退出的时候,内核能够根据 kstack 的值快速定位栈的位置并进行回收。uCore 的这种内核栈的设计借鉴的是 linux 的方法(但由于内存管理实现的差异,它实现的远不如 linux 的灵活),它使得每个线程的内核栈在不同的位置,这样从某种程度上方便调试,但同时也使得内核对栈溢出变得十分不敏感,因为一旦发生溢出,它极可能污染内核中其它的数据使得内核崩溃。如果能够通过页表,将所有进程的内核栈映射到固定的地址上去,能够避免这种问题,但又会使得进程切换过程中对栈的修改变得相当繁琐。感兴趣的同学可以参考 linux kernel 的代码对此进行尝试。 为了管理系统中所有的进程控制块,uCore维护了如下全局变量(位于kern/process/proc.c):
static struct proc *current:当前占用CPU且处于“运行”状态进程控制块指针。通常这个变量是只读的,只有在进程切换的时候才进行修改,并且整个切换和修改过程需要保证操作的原子性,目前至少需要屏蔽中断。可以参考 switch_to 的实现。 static struct proc *initproc:本实验中,指向一个内核线程。本实验以后,此指针将指向第一个用户态进程。 static list_entry_t hash_list[HASH_LIST_SIZE]:所有进程控制块的哈希表,proc_struct中的成员变量hash_link将基于pid链接入这个哈希表中。 list_entry_t proc_list:所有进程控制块的双向线性列表,proc_struct中的成员变量list_link将链接入这个链表中。
0X01 分配并初始化一个进程控制块
在ucore中,当创建进程的时候,需要先申请一个进程控制块(空块,后续填入线程的内容),在init.c::kern_init函数调用了proc.c::proc_init函数。proc_init函数启动了创建内核线程的步骤。首先当前的执行上下文(从kern_init 启动至今)就可以看成是uCore内核(也可看做是内核进程)中的一个内核线程的上下文。为此,uCore通过给当前执行的上下文分配一个进程控制块以及对它进行相应初始化,将其打造成第0个内核线程 -- idleproc。即调用alloc_proc函数来通过kmalloc函数获得proc_struct结构的一块内存块-,作为第0个进程控制块。并把proc进行初步初始化(即把proc_struct中的各个成员变量清零)
我们的任务就是实现这个alloc_proc函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 static struct proc_struct *alloc_proc (void ) { struct proc_struct *proc =sizeof (struct proc_struct)); if (proc != NULL ) { proc->state = PROC_UNINIT; proc->pid = -1 ; proc->runs = 0 ; proc->kstack = 0 ; proc->need_resched = 0 ; proc->parent = NULL ; proc->mm = NULL ; memset (&(proc->context), 0 , sizeof (struct context)); proc->tf = NULL ; proc->cr3 = boot_cr3; proc->flags = 0 ; memset (proc->name, 0 , PROC_NAME_LEN); } return proc; }
几个参数含义
state 设置了进程的状态为“初始”态,这表示进程已经 “出生”了,正在获取资源茁壮成长中pid 设置了进程的pid为-1,这表示进程的“身份证号”还没有办好cr3 表明由于该内核线程在内核中运行,故采用为uCore内核已经建立的页表,即设置为在uCore内核页表的起始地址boot_cr3。后续实验中可进一步看出所有内核线程的内核虚地址空间(也包括物理地址空间)是相同的。既然内核线程共用一个映射内核空间的页表,这表示内核空间对所有内核线程都是“可见”的,所以更精确地说,这些内核线程都应该是从属于同一个唯一的“大内核进程”—uCore内核。
关于context和trapframe
proc_struct存在以上两个字段,分别保存了进程的上下文和中断帧。
context 保存了进程的上下文,其实就是当前程序执行到的汇编的位置和相关寄存器,这样从进程A切换到进程B的时候就能恢复进程B执行到的位置。trapframe 这个保存了中断帧,主要是实现进程A在中断过程中被切换至进程B,再切换到进程A后能从中断正确返回(中断函数好多都是公用的,需要中断帧来准确记录到底是哪个进程进入到当前的中断函数中)另外,我们还能体会到为什么子进程要继承父进程的资源
比如,当进程A fork 出子进程A1时,由于子进程A1继承了父进程A的上下文和中断帧(当然还有其他资源) (此时子进程A1和父进程A可以看作是两个进程,分别被调度),所以子进程能够通过中断帧在创建的时候就进行中断返回(fork是系统调用,需要进入内核态的中断函数里)
0X02 为新创建的内核线程分配资源
创建一个内核线程需要分配和设置好很多资源。kernel_thread函数通过调用do_fork函数完成具体内核线程的创建工作。do_kernel函数会调用alloc_proc函数来分配并初始化一个进程控制块,但alloc_proc只是找到了一小块内存用以记录进程的必要信息,并没有实际分配这些资源 。ucore一般通过do_fork实际创建新的内核线程。do_fork的作用是,创建当前内核线程的一个副本,它们的执行上下文、代码、数据都一样,但是存储位置不同。 在这个过程中,需要给新内核线程分配资源,并且复制原进程的状态。需要完成在kern/process/proc.c中的do_fork函数中的处理过程。它的大致执行步骤包括:
调用alloc_proc,首先获得一块用户信息块。
为进程分配一个内核栈。
复制原进程的内存管理信息到新进程(但内核线程不必做此事)
复制原进程上下文到新进程
将新进程添加到进程列表
唤醒新进程
返回新进程号
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 int do_fork (uint32_t clone_flags, uintptr_t stack , struct trapframe *tf) { int ret = -E_NO_FREE_PROC; struct proc_struct *proc ; if (nr_process >= MAX_PROCESS) { goto fork_out; } ret = -E_NO_MEM; proc = alloc_proc(); if (proc == NULL ) goto fork_out; proc->parent = current; if (setup_kstack(proc) != 0 ) goto bad_fork_cleanup_proc; if (copy_mm(clone_flags, proc) != 0 ) goto bad_fork_cleanup_kstack; copy_thread(proc, stack , tf); bool intr_flag; local_intr_save(intr_flag); { proc->pid = get_pid(); hash_proc(proc); list_add(&proc_list, &(proc->list_link)); nr_process++; } local_intr_restore(intr_flag); wakeup_proc(proc); ret = proc->pid; fork_out: return ret; bad_fork_cleanup_kstack: put_kstack(proc); bad_fork_cleanup_proc: kfree(proc); goto fork_out; }
接下来看一下do_fork函数中调用的几个函数。
setup_kstack : 分配2个页面,然后将其的虚拟地址作为进程内核态页面
copy_mm : 复制内存空间,但是由于是写时复制,所以这个函数什么都不做
copy_thread : 会把父进程的trapframe复制到子进程的内核栈中,然后设置子进程的内核栈指针和内核入口地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 static void copy_thread (struct proc_struct *proc, uintptr_t esp, struct trapframe *tf) { proc->tf = (struct trapframe *)(proc->kstack + KSTACKSIZE) - 1 ; *(proc->tf) = *tf; proc->tf->tf_regs.reg_eax = 0 ; proc->tf->tf_esp = esp; proc->tf->tf_eflags |= FL_IF; proc->context.eip = (uintptr_t )forkret; proc->context.esp = (uintptr_t )(proc->tf); }
fork函数与copy_thread
从copy_thread中,我们能看出,子进程和父进程的返回值不同的原因是因为修改了返回值寄存器,子进程返回值就变成了0
同时,还要设置子进程的下一条指令为执行forkret函数,这个函数的传入参数是中断帧,目的是中断返回
当子进程被调度的时候,就会从这个函数中完成中断返回。
1 2 3 4 5 6 7 8 9 10 static void forkret (void ) { forkrets(current->tf); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 .globl __trapret __trapret: # restore registers from stack popal # restore %ds, %es, %fs and %gs popl %gs popl %fs popl %es popl %ds # get rid of the trap number and error code addl $0x8, %esp iret .globl forkrets forkrets: # set stack to this new process's trapframe movl 4(%esp), %esp jmp __trapret
但是中断返回到哪里?
这个返回的位置其实在kernel_thread中被设置,我们来看一下这个函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 int kernel_thread (int (*fn)(void *), void *arg, uint32_t clone_flags) { struct trapframe tf ; memset (&tf, 0 , sizeof (struct trapframe)); tf.tf_cs = KERNEL_CS; tf.tf_ds = tf.tf_es = tf.tf_ss = KERNEL_DS; tf.tf_regs.reg_ebx = (uint32_t )fn; tf.tf_regs.reg_edx = (uint32_t )arg; tf.tf_eip = (uint32_t )kernel_thread_entry; return do_fork(clone_flags | CLONE_VM, 0 , &tf); }
可以看到中断返回到kernel_thread_entry,这个函数的作用先是调用fn函数,然后调用do_exit退出
1 2 3 4 5 6 7 8 9 10 kernel_thread_entry: # void kernel_thread(void) pushl %edx # push arg call *%ebx # call fn pushl %eax # save the return value of fn(arg) call do_exit # call do_exit to terminate current thread
因此,内核线程调度是这样的:
调用kernel_thread 函数,创建一个内核线程,需要执行的函数是fn,对应的参数是arg。kernel_thread函数会先创建中断帧,中断帧的返回函数是kernel_thread_entry 然后kernel_thread函数会调用do_fork 函数,创建一个内核线程,这个函数会把中断帧复制到子进程的内核栈中,然后设置子进程的内核栈指针和上下文的入口地址为forkret(这是由copy_thread函数完成的) 调度发生时,会先通过上下文入口地址进入forkret 函数,这个函数(实际上这个是包装函数)会完成中断返回,返回到kernel_thread_entry函数 kernel_thread_entry 函数会调用fn函数,然后调用do_exit函数退出
get_proc_id : 分配一个进程id,这个提供一个比较高性能的快速分配唯一pid的算法
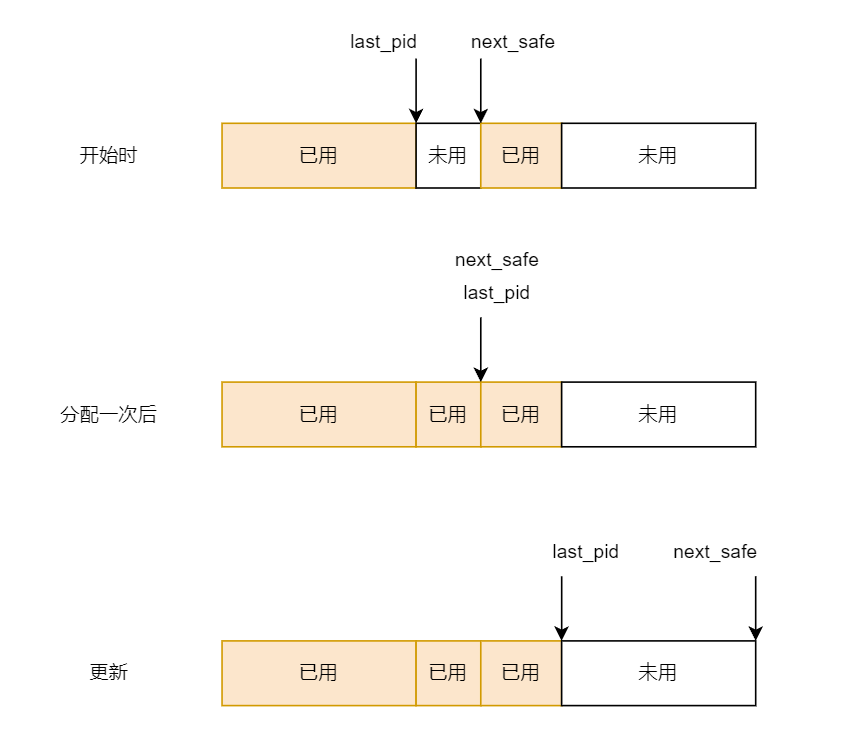
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 static int get_pid (void ) { static_assert (MAX_PID > MAX_PROCESS); struct proc_struct *proc ; list_entry_t *list = &proc_list, *le; static int next_safe = MAX_PID, last_pid = MAX_PID; if (++last_pid >= MAX_PID) { last_pid = 1 ; goto inside; } if (last_pid >= next_safe) { inside: next_safe = MAX_PID; repeat: le = list ; while ((le = list_next(le)) != list ) { proc = le2proc(le, list_link); if (proc->pid == last_pid) { if (++last_pid >= next_safe) { if (last_pid >= MAX_PID) { last_pid = 1 ; } next_safe = MAX_PID; goto repeat; } } else if (proc->pid > last_pid && next_safe > proc->pid) { next_safe = proc->pid; } } } return last_pid; }
wakeup_proc : 把进程的状态设置为就绪
hash_proc : 把进程加入到hash表中
0X02 进程切换
首先,schedule函数会遍历proc_list,找到一个就绪的进程,然后调用proc_run函数进行进程切换
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 void schedule (void ) { bool intr_flag; list_entry_t *le, *last; struct proc_struct *next =NULL ; local_intr_save(intr_flag); { current->need_resched = 0 ; last = (current == idleproc) ? &proc_list : &(current->list_link); le = last; do { if ((le = list_next(le)) != &proc_list) { next = le2proc(le, list_link); if (next->state == PROC_RUNNABLE) { break ; } } } while (le != last); if (next == NULL || next->state != PROC_RUNNABLE) { next = idleproc; } next->runs++; if (next != current) { proc_run(next); } } local_intr_restore(intr_flag); }
在proc_run函数中,会调用switch_to函数进行进程切换
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 void proc_run (struct proc_struct *proc) { if (proc != current) { bool intr_flag; struct proc_struct *prev = local_intr_save(intr_flag); { current = proc; load_esp0(next->kstack + KSTACKSIZE); lcr3(next->cr3); switch_to(&(prev->context), &(next->context)); } local_intr_restore(intr_flag); } }
在switch_to函数中,会调用汇编函数__switch_to进行进程切换,主要是切换到对应的上下文中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 .text .globl switch_to switch_to: # switch_to(from, to) # save from's registers movl 4(%esp), %eax # 获取当前进程的context结构地址 popl 0(%eax) # 将eip保存至当前进程的context结构 movl %esp, 4(%eax) # 将esp保存至当前进程的context结构 movl %ebx, 8(%eax) # 将ebx保存至当前进程的context结构 movl %ecx, 12(%eax) # 将ecx保存至当前进程的context结构 movl %edx, 16(%eax) # 将edx保存至当前进程的context结构 movl %esi, 20(%eax) # 将esi保存至当前进程的context结构 movl %edi, 24(%eax) # 将edi保存至当前进程的context结构 movl %ebp, 28(%eax) # 将ebp保存至当前进程的context结构 # restore to's registers movl 4(%esp), %eax # 获取下一个进程的context结构地址 # 需要注意的是,其地址不是8(%esp),因为之前已经pop过一次栈。 movl 28(%eax), %ebp # 恢复ebp至下一个进程的context结构 movl 24(%eax), %edi # 恢复edi至下一个进程的context结构 movl 20(%eax), %esi # 恢复esi至下一个进程的context结构 movl 16(%eax), %edx # 恢复edx至下一个进程的context结构 movl 12(%eax), %ecx # 恢复ecx至下一个进程的context结构 movl 8(%eax), %ebx # 恢复ebx至下一个进程的context结构 movl 4(%eax), %esp # 恢复esp至下一个进程的context结构 pushl 0(%eax) # 插入下一个进程的eip,以便于ret到下个进程的代码位置。 ret
至此,目标程序的上下文已经切换完成,可以开始执行对应的进程了。
0X03 总结
通过这个lab4,我们学习了以下内容:
使用进程描述符来对进程的上下文和其他信息进行描述,方便调度
在fork系统调用时,通过创建中断帧和上下文信息来实现中断返回,并分析了为什么子进程和父进程返回值不同
get_pid算法,快速分配不重数
进程切换的方法