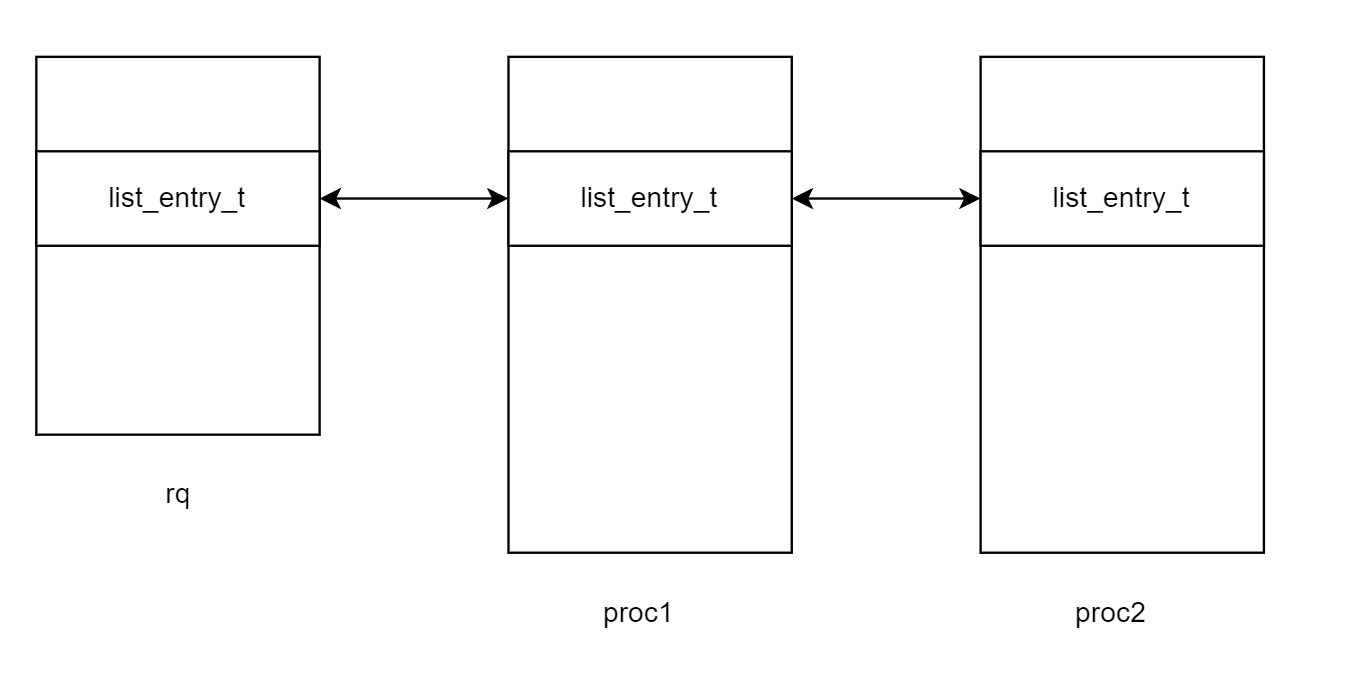
structproc_struct { enumproc_statestate;// Process state int pid; // Process ID int runs; // the running times of Proces uintptr_t kstack; // Process kernel stack volatilebool need_resched; // bool value: need to be rescheduled to release CPU? structproc_struct *parent;// the parent process structmm_struct *mm;// Process's memory management field structcontextcontext;// Switch here to run process structtrapframe *tf;// Trap frame for current interrupt uintptr_t cr3; // CR3 register: the base addr of Page Directroy Table(PDT) uint32_t flags; // Process flag char name[PROC_NAME_LEN + 1]; // Process name list_entry_t list_link; // Process link list list_entry_t hash_link; // Process hash list int exit_code; // exit code (be sent to parent proc) uint32_t wait_state; // waiting state structproc_struct *cptr, *yptr, *optr;// relations between processes
/*以下为新增*/
// 包含该线程的就绪队列(多级多列调度时,系统中存在多个就绪队列) structrun_queue *rq;// running queue contains Process // 就绪队列节点 list_entry_t run_link; // the entry linked in run queue // 时间片 int time_slice; // time slice for occupying the CPU // lab6中支持stride算法的斜堆节点 skew_heap_entry_t lab6_run_pool; // FOR LAB6 ONLY: the entry in the run pool // lab6中支持stride算法的当前线程stride步长 uint32_t lab6_stride; // FOR LAB6 ONLY: the current stride of the process // 优先级 uint32_t lab6_priority; // FOR LAB6 ONLY: the priority of process, set by lab6_set_priority(uint32_t) };
/* * * trap - handles or dispatches an exception/interrupt. if and when trap() returns, * the code in kern/trap/trapentry.S restores the old CPU state saved in the * trapframe and then uses the iret instruction to return from the exception. * */ voidtrap(struct trapframe *tf) { // dispatch based on what type of trap occurred // used for previous projects if (current == NULL) { trap_dispatch(tf); } else { // keep a trapframe chain in stack // 保持中断链 struct trapframe *otf = current->tf; current->tf = tf; bool in_kernel = trap_in_kernel(tf); trap_dispatch(tf); current->tf = otf; if (!in_kernel) { if (current->flags & PF_EXITING) { do_exit(-E_KILLED); } if (current->need_resched) { // 调度发生 schedule(); } } } }