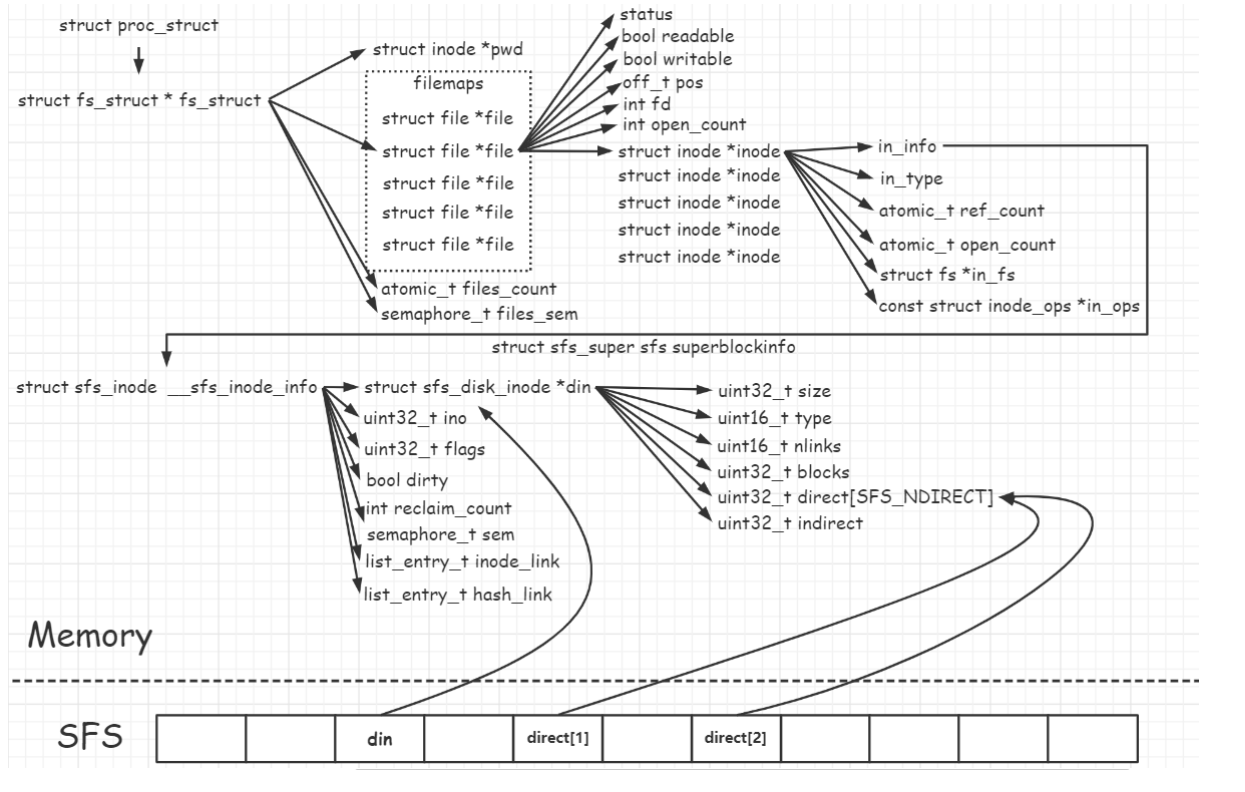
structfiles_struct { // 当前工作目录 structinode *pwd;// inode of present working directory // 文件描述符(数组) structfile *fd_array;// opened files array // 打开的文件数目 int files_count; // the number of opened files // 用于文件加锁的信号量 semaphore_t files_sem; // lock protect sem };
structfiles_struct { // 当前工作目录 structinode *pwd;// inode of present working directory // 文件描述符(数组) structfile *fd_array;// opened files array // 打开的文件数目 int files_count; // the number of opened files // 用于文件加锁的信号量 semaphore_t files_sem; // lock protect sem };
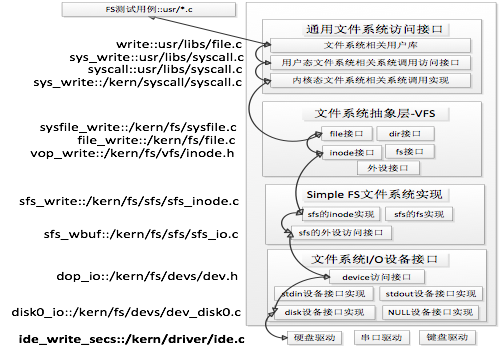
/* * Virtual File System layer functions. * * The VFS layer translates operations on abstract on-disk files or * pathnames to operations on specific files on specific filesystems. */ voidvfs_init(void); voidvfs_cleanup(void); voidvfs_devlist_init(void);
/* * VFS layer low-level operations. * See inode.h for direct operations on inodes. * See fs.h for direct operations on filesystems/devices. * * vfs_set_curdir - change current directory of current thread by inode * vfs_get_curdir - retrieve inode of current directory of current thread * vfs_get_root - get root inode for the filesystem named DEVNAME * vfs_get_devname - get mounted device name for the filesystem passed in */ intvfs_set_curdir(struct inode *dir); intvfs_get_curdir(struct inode **dir_store); intvfs_get_root(constchar *devname, struct inode **root_store); constchar *vfs_get_devname(struct fs *fs);
/* * VFS layer high-level operations on pathnames * Because namei may destroy pathnames, these all may too. * * vfs_open - Open or create a file. FLAGS/MODE per the syscall. * vfs_close - Close a inode opened with vfs_open. Does not fail. * (See vfspath.c for a discussion of why.) * vfs_link - Create a hard link to a file. * vfs_symlink - Create a symlink PATH containing contents CONTENTS. * vfs_readlink - Read contents of a symlink into a uio. * vfs_mkdir - Create a directory. MODE per the syscall. * vfs_unlink - Delete a file/directory. * vfs_rename - rename a file. * vfs_chdir - Change current directory of current thread by name. * vfs_getcwd - Retrieve name of current directory of current thread. * */ intvfs_open(char *path, uint32_t open_flags, struct inode **inode_store); intvfs_close(struct inode *node); intvfs_link(char *old_path, char *new_path); intvfs_symlink(char *old_path, char *new_path); intvfs_readlink(char *path, struct iobuf *iob); intvfs_mkdir(char *path); intvfs_unlink(char *path); intvfs_rename(char *old_path, char *new_path); intvfs_chdir(char *path); intvfs_getcwd(struct iobuf *iob);
/* * VFS layer mid-level operations. * * vfs_lookup - Like VOP_LOOKUP, but takes a full device:path name, * or a name relative to the current directory, and * goes to the correct filesystem. * vfs_lookparent - Likewise, for VOP_LOOKPARENT. * * Both of these may destroy the path passed in. */ intvfs_lookup(char *path, struct inode **node_store); intvfs_lookup_parent(char *path, struct inode **node_store, char **endp);
/* * Misc * * vfs_set_bootfs - Set the filesystem that paths beginning with a * slash are sent to. If not set, these paths fail * with ENOENT. The argument should be the device * name or volume name for the filesystem (such as * "lhd0:") but need not have the trailing colon. * * vfs_get_bootfs - return the inode of the bootfs filesystem. * * vfs_add_fs - Add a hardwired filesystem to the VFS named device * list. It will be accessible as "devname:". This is * intended for filesystem-devices like emufs, and * gizmos like Linux procfs or BSD kernfs, not for * mounting filesystems on disk devices. * * vfs_add_dev - Add a device to the VFS named device list. If * MOUNTABLE is zero, the device will be accessible * as "DEVNAME:". If the mountable flag is set, the * device will be accessible as "DEVNAMEraw:" and * mountable under the name "DEVNAME". Thus, the * console, added with MOUNTABLE not set, would be * accessed by pathname as "con:", and lhd0, added * with mountable set, would be accessed by * pathname as "lhd0raw:" and mounted by passing * "lhd0" to vfs_mount. * * vfs_mount - Attempt to mount a filesystem on a device. The * device named by DEVNAME will be looked up and * passed, along with DATA, to the supplied function * MOUNTFUNC, which should create a struct fs and * return it in RESULT. * * vfs_unmount - Unmount the filesystem presently mounted on the * specified device. * * vfs_unmountall - Unmount all mounted filesystems. */ intvfs_set_bootfs(char *fsname); intvfs_get_bootfs(struct inode **node_store);
/* * Abstract filesystem. (Or device accessible as a file.) * * Information: * fs_info : filesystem-specific data (sfs_fs) * fs_type : filesystem type * Operations: * * fs_sync - Flush all dirty buffers to disk. * fs_get_root - Return root inode of filesystem. * fs_unmount - Attempt unmount of filesystem. * fs_cleanup - Cleanup of filesystem.??? * * * fs_get_root should increment the refcount of the inode returned. * It should not ever return NULL. * * If fs_unmount returns an error, the filesystem stays mounted, and * consequently the struct fs instance should remain valid. On success, * however, the filesystem object and all storage associated with the * filesystem should have been discarded/released. * */ structfs { union { structsfs_fs __sfs_info; } fs_info; // filesystem-specific data enum { fs_type_sfs_info, } fs_type; // filesystem type int (*fs_sync)(struct fs *fs); // Flush all dirty buffers to disk structinode *(*fs_get_root)(structfs *fs);// Return root inode of filesystem. int (*fs_unmount)(struct fs *fs); // Attempt unmount of filesystem. void (*fs_cleanup)(struct fs *fs); // Cleanup of filesystem.??? };
/* filesystem for sfs */ structsfs_fs { structsfs_supersuper;/* on-disk superblock */ structdevice *dev;/* device mounted on */ structbitmap *freemap;/* blocks in use are mared 0 */ bool super_dirty; /* true if super/freemap modified */ void *sfs_buffer; /* buffer for non-block aligned io */ semaphore_t fs_sem; /* semaphore for fs */ semaphore_t io_sem; /* semaphore for io */ semaphore_t mutex_sem; /* semaphore for link/unlink and rename */ list_entry_t inode_list; /* inode linked-list */ list_entry_t *hash_list; /* inode hash linked-list */ };
/* inode for sfs */ structsfs_inode { structsfs_disk_inode *din;/* on-disk inode */ uint32_t ino; /* inode number */ bool dirty; /* true if inode modified */ int reclaim_count; /* kill inode if it hits zero */ semaphore_t sem; /* semaphore for din */ list_entry_t inode_link; /* entry for linked-list in sfs_fs */ list_entry_t hash_link; /* entry for hash linked-list in sfs_fs */ };
/* * sfs_io_nolock - Rd/Wr a file contentfrom offset position to offset+ length disk blocks<-->buffer (in memroy) * @sfs: sfs file system * @sin: sfs inode in memory * @buf: the buffer Rd/Wr * @offset: the offset of file * @alenp: the length need to read (is a pointer). and will RETURN the really Rd/Wr lenght * @write: BOOL, 0 read, 1 write */ staticintsfs_io_nolock(struct sfs_fs *sfs, struct sfs_inode *sin, void *buf, off_t offset, size_t *alenp, bool write) { structsfs_disk_inode *din =sin->din; assert(din->type != SFS_TYPE_DIR);
off_t endpos = offset + *alenp, blkoff; *alenp = 0; // calculate the Rd/Wr end position // 计算缓冲区读取/写入的终止位置 if (offset < 0 || offset >= SFS_MAX_FILE_SIZE || offset > endpos) { return -E_INVAL; } // 如果偏移与终止位置相同,即欲读取/写入0字节的数据则直接返回 if (offset == endpos) { return0; } if (endpos > SFS_MAX_FILE_SIZE) { endpos = SFS_MAX_FILE_SIZE; } if (!write) { // 如果是读取数据,且缓冲区中剩余的数据超出一个硬盘节点的数据大小就直接返回 if (offset >= din->size) { return0; } if (endpos > din->size) { endpos = din->size; } }
int ret = 0; size_t size, alen = 0; uint32_t ino; uint32_t blkno = offset / SFS_BLKSIZE; // The NO. of Rd/Wr begin block uint32_t nblks = endpos / SFS_BLKSIZE - blkno; // The size of Rd/Wr blocks
// LAB8:EXERCISE1 YOUR CODE HINT: call sfs_bmap_load_nolock, sfs_rbuf, sfs_rblock,etc. read different kind of blocks in file /* * (1) If offset isn't aligned with the first block, Rd/Wr some content from offset to the end of the first block * NOTICE: useful function: sfs_bmap_load_nolock, sfs_buf_op * Rd/Wr size = (nblks != 0) ? (SFS_BLKSIZE - blkoff) : (endpos - offset) * (2) Rd/Wr aligned blocks * NOTICE: useful function: sfs_bmap_load_nolock, sfs_block_op * (3) If end position isn't aligned with the last block, Rd/Wr some content from begin to the (endpos % SFS_BLKSIZE) of the last block * NOTICE: useful function: sfs_bmap_load_nolock, sfs_buf_op */ // 对齐偏移。如果偏移没有对齐第一个基础块,则多读取/写入第一个基础块的末尾数据 if ((blkoff = offset % SFS_BLKSIZE) != 0) { size = (nblks != 0) ? (SFS_BLKSIZE - blkoff) : (endpos - offset); // 获取第一个基础块所对应的block的编号ino if ((ret = sfs_bmap_load_nolock(sfs, sin, blkno, &ino)) != 0) { goto out; }
// load_icode - called by sys_exec-->do_execve staticintload_icode(int fd, int argc, char **kargv) { /* LAB8:EXERCISE2 YOUR CODE HINT:how to load the file with handler fd in to process's memory? how to setup argc/argv? * MACROs or Functions: * mm_create - create a mm * setup_pgdir - setup pgdir in mm * load_icode_read - read raw data content of program file * mm_map - build new vma * pgdir_alloc_page - allocate new memory for TEXT/DATA/BSS/stack parts * lcr3 - update Page Directory Addr Register -- CR3 */ /* (1) create a new mm for current process * (2) create a new PDT, and mm->pgdir= kernel virtual addr of PDT * (3) copy TEXT/DATA/BSS parts in binary to memory space of process * (3.1) read raw data content in file and resolve elfhdr * (3.2) read raw data content in file and resolve proghdr based on info in elfhdr * (3.3) call mm_map to build vma related to TEXT/DATA * (3.4) callpgdir_alloc_page to allocate page for TEXT/DATA, read contents in file * and copy them into the new allocated pages * (3.5) callpgdir_alloc_page to allocate pages for BSS, memset zero in these pages * (4) call mm_map to setup user stack, and put parameters into user stack * (5) setup current process's mm, cr3, reset pgidr (using lcr3 MARCO) * (6) setup uargc and uargv in user stacks * (7) setup trapframe for user environment * (8) if up steps failed, you should cleanup the env. */ assert(argc >= 0 && argc <= EXEC_MAX_ARG_NUM);
if (current->mm != NULL) { panic("load_icode: current->mm must be empty.\n"); }
int ret = -E_NO_MEM; // 创建proc的内存管理结构 structmm_struct *mm; if ((mm = mm_create()) == NULL) { goto bad_mm; } if (setup_pgdir(mm) != 0) { goto bad_pgdir_cleanup_mm; }