基本块布局、热点代码对齐,内存预取,循环优化
之前给阳关电源做项目的时候,他们提出要对代码进行优化,所以学习了一些优化方法,现在正好来记录一下。虽然最后并没用到多少下述方法...
性能分析工具
C/C++代码分析
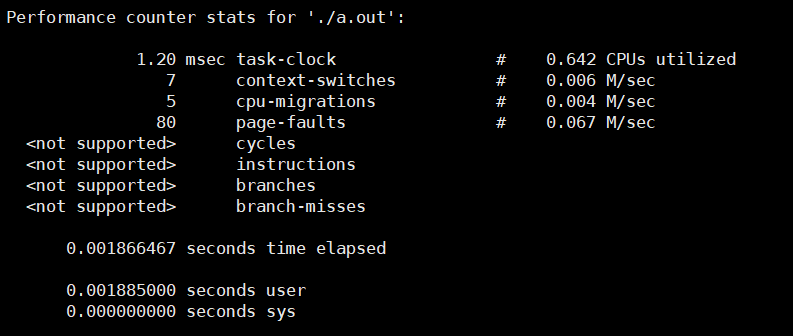
因为这部分代码需要部署在服务器上,所以正好有perf工具可以使用。顺便top也是不错的工具,用来大致看一下load还是不错的。
perf工具我也只是掌握了基本的功能,深入的功能还有待后续学习,此处就不展开了。
比较常用的几个命令:
perf top:实时显示系统/进程的性能统计信息perf stat:分析系统/进程的整体性能概况perf record:记录一段时间内系统/进程的性能时间perf report:读取perf record生成的数据文件,并显示分析数据
python代码分析
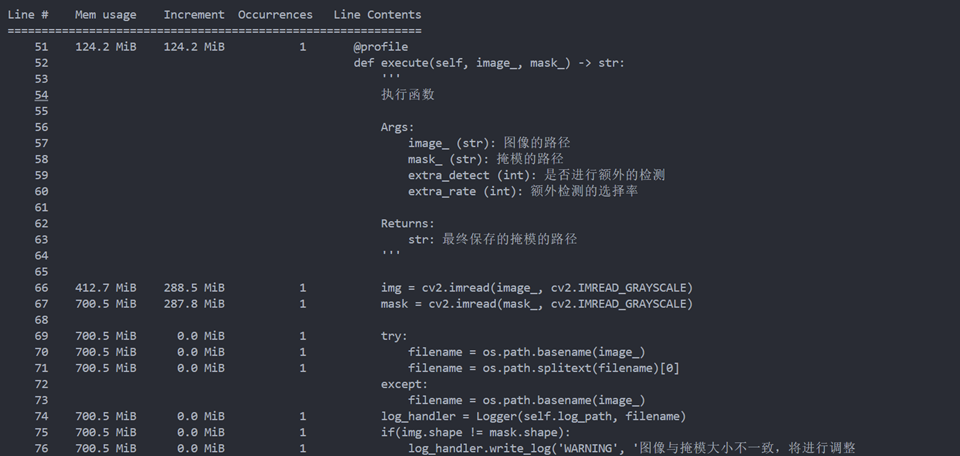
memory_profiler
这个工具可以用于分析代码的内存开销,使用方法也很简单
1 |
|
把装饰器挂在待分析的函数上,直接执行就可以了。
每一行代码执行前后的开销都会被记录下来
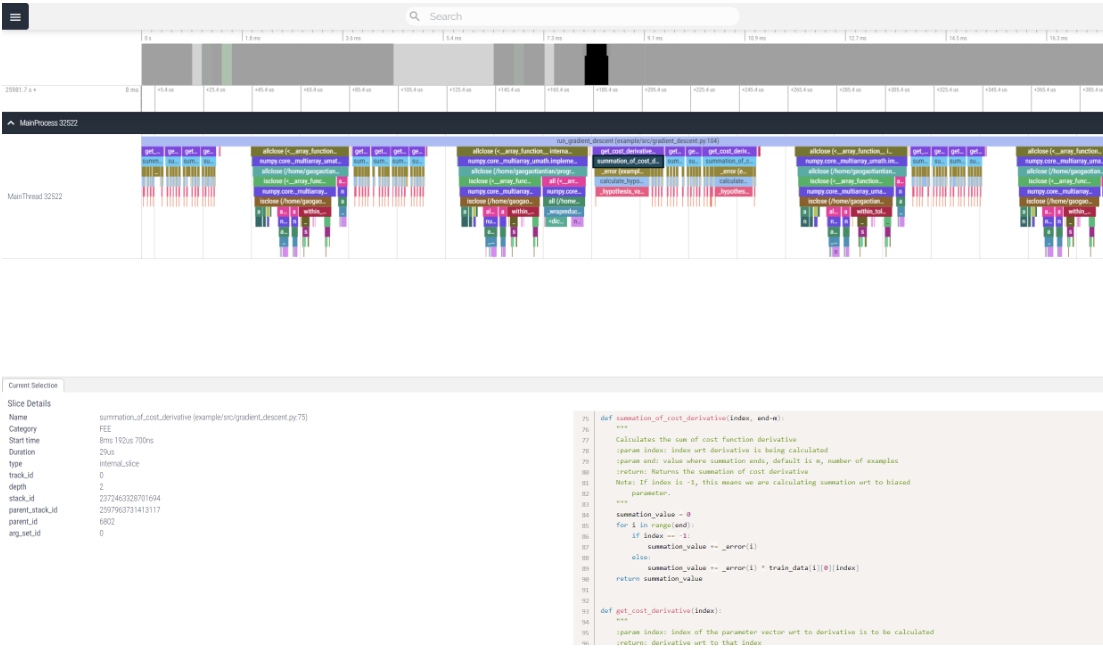
viztracer
这个工具可以用于记录函数的调用栈和时间,不过目前发现它对numpy这类库支持效果不是很好,有些调用过程无法记录到。
看了一下issue,是因为numpy的函数都被优化成了纯C函数,而不是PYCFunction,所以没法触发hook导致无法被记录。不过这种基本运算也不是很需要被追踪...
viztracer的作者就是前一段时间锤wjk假唱的那位大佬(清华毕业,加州微软工作,年收入七位数,实在是太牛了)
还有一个小小的问题,如果windows下用户名是中文的话,需要修改Temp目录才行。
这个工具当时画出来的图我看的不是很明白,所以没敢往PPT上放
代码布局优化
代码中经常被执行到的区域定义为热路径,剩余的区域定义为冷路径。
由于指令本身也参与缓存,所以热路径的代码执行效率会比冷路径高很多。
另外,由于缓存(页表)的限制,热路径占用的空间也大,则页表项也多,被置换出去的概率就越大。
因此,代码布局优化的目的就是将热路径的代码放在一起,并让其尽可能小,这样可以提升缓存利用率,提高代码的执行效率。
基本块布局
考虑以下代码布局
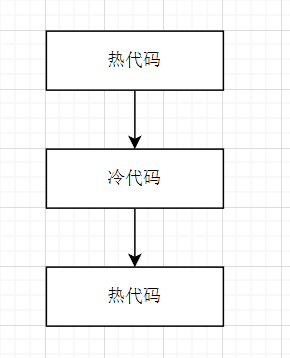
由于两个热路径之间插入了冷路径,其表现为热路径和冷路径代码位于相同的页表缓存项中,增大了缓存空间,不利于缓存。
这种代码布局常见于错误处理,如
1 |
|
如果不做优化,那么产生的汇编的布局应该是这样的
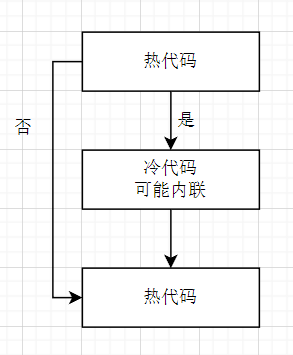
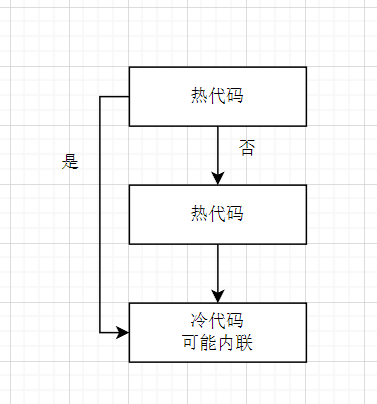
可以使用__builtin_expect函数来优化这种代码布局
1 |
|
__builtin_expect(cond, value)即表示cond的值为value的概率更大。
这样会有利于编译器生成更好的布局,如
可以定义成宏使用,更加方便
1 |
|
也可以用于switch
1 |
|
利用该注解,编译器可以微调代码,从而提高性能。
冷代码拆分
冷代码拆分和基本块布局类似,都是为了减少冷路径代码占用的缓存空间。
上述代码布局中,是将冷代码移到热代码后面,这样可以减少冷路径代码占用的缓存空间。但是如果有些时候,热路径贯穿始终,而冷路径基本都是些错误处理函数,这样移动到最后就有些不合适了(因为某个热路径可能需要保证错误被正确处理)
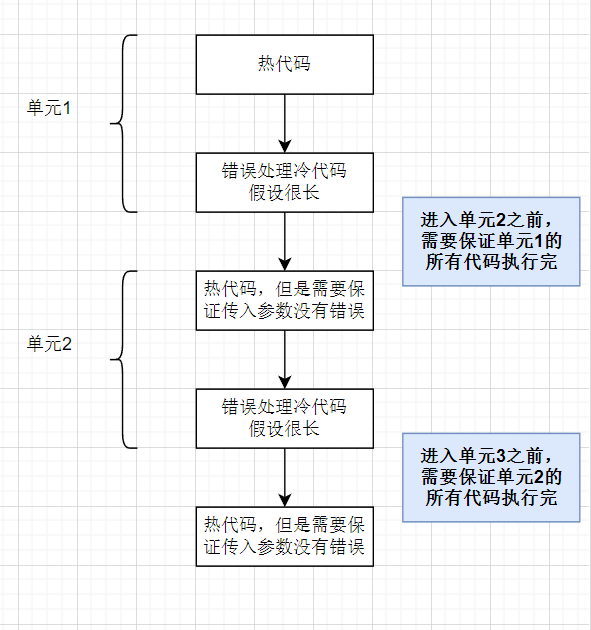
由于冷代码可能会被内联,这时候缓存页就会变大导致效率低下。
为了提升利用率,需要静止内联冷代码,这时候可以使用noinline属性来告知编译器不要内联该冷函数。
1 |
|
这个时候,cold1函数将被置于.text段以外,而原.text段将被一条call指令替代,这样就保证了缓存利用率。
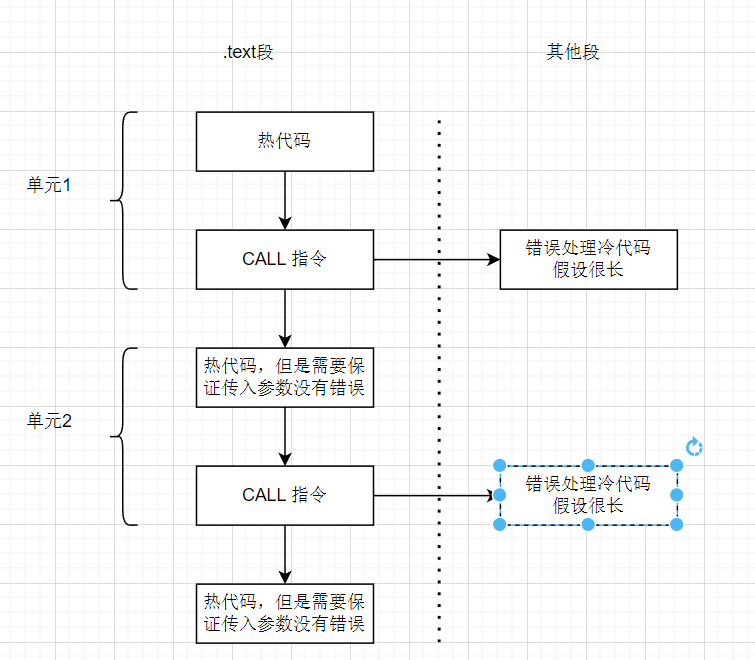
数据优化
数据优化一方面是要写出数据友好型的程序,另一方面也要保证CPU流水线尽可能少停摆。
数据友好型程序还是针对缓存而言的,主要就是对齐和预取。
CPU流水线不停摆就相对比较麻烦,这与CPU内部执行单元的数目和流水线深度高度依赖。这点在CSAPP中有比较详细的描述。
内存对齐
内存对齐这是一个老生常谈的问题,主要就是针对结构体,整倍数内存访问会更快,也更利于缓存(缓存都是内存对齐的,如果数据不对齐,会出现需要访问两次缓存的情况)
可以使用alignas()来指定对齐,一般的规则是:
- N B的数据对齐于能被N整除的地址 if N <= 8
- 对齐于能被16整除的地址 else
1 |
|
内存预取至缓存
缓存预取是为了解决循环处理数据时的缓存性能下降
类似这种情况
1 |
|
上述情况中,由于i和j相差很大,缓存很可能不会预先保存x[j]的缓存项,但是cond发生概率又很大,就会导致性能下降。
这个时候,需要对x[j]进行预取,提前将其缓存。可以使用__builtin_prefetch来完成。
1 |
|
该内置函数原型为void __builtin_prefetch (const void *addr, ...)。还有两个可选参数:
rw: 是个编译时的常数,或 1 或 0 。1 时表示写(w),0 时表示读(r)locality: 必须是编译时的常数,也称为“时间局部性”(temporal locality) 。时间局部性是指,如果程序中某一条指令一旦执行,则不久之后该指令可能再被执行;如果某数据被访问,则不久之后该数据会被再次访问。该值的范围在 0 - 3 之间。为 0 时表示,它没有时间局部性,也就是说,要访问的数据或地址被访问之后的不长的时间里不会再被访问;为 3 时表示,被访问的数据或地址具有高 时间局部性,也就是说,在被访问不久之后非常有可能再次访问;对于值 1 和 2,则分别表示具有低 时间局部性 和中等 时间局部性。该值默认为 3 。
这个预取指令不要提前插入以免污染缓存,也不要插入的太迟,导致没有生效。而且对于不同缓存大小的机器优化程度也不一样(甚至负优化)。
循环优化
循环优化非常多,也非常常见。
好的循环需要让缓存最大利用且流水线不停摆,有很多优化方法。
大部分循环优化都会被编译器自动完成,感觉除非万不得已,不需要手动优化循环。
常值外提
很简单,下面给出示例:
1 |
|
劣于
1 |
|
当然,这些其实不需要手动来优化,编译器优化等级开高会自动完成。
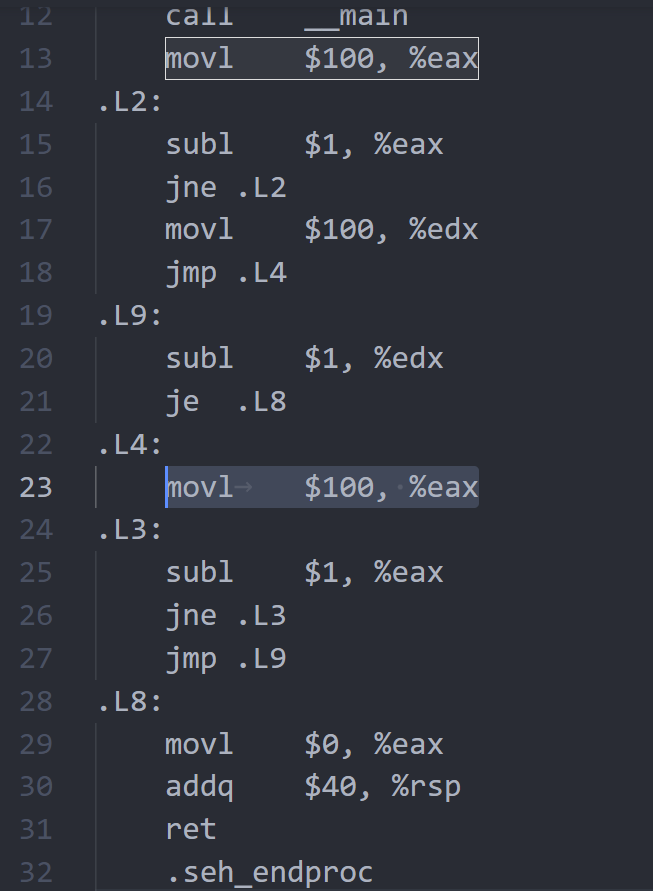
循环展开
循环展开也是经常提到的,它有利于流水线,但是编译器非常擅长循环展开,所以不需要手动展开(除非刷题时不给开优化,不过一般都是给开的吧)
而且处理器都是乱序执行+分支预测,肯定比盲目手动展开效果好。
如果想要手动控制编译器循环展开,可以使用#pragma unroll(4)这种指令来命令编译器进行展开。
减弱循环内开销
可以在循环中利用更多开销小的指令来取缔一个开销大的指令。
比如CPU有4个加法运算单元,但是只有1个乘法运算单元,这个时候就要减少循环中的乘法运算。
1 |
|
更改为
1 |
|
实际测试中,编译器会自动执行优化。
但是如果是函数操作的话,那么手动优化还是必要的。
循环判断分离
如果循环内的分支判断是固定的,可以移动到循环外。
1 |
|
可以优化成
1 |
|
这样,虽然代码翻倍,但是每个循环都可以被单独优化。
实际测试,编译器还是会自动优化。但是如果条件复杂,处理的内容较多时,优化能力下降。
循环分块
就是矩阵运算的那个缓存友好型方法,比较繁琐,实际中也不好写。而且实测,编译器会自动优化,不谈了。
向量化指令
在优化的时候,我也尝试了一些SIMD指令。但是效果不好,感觉都是无优化或者负优化,这部分还是依赖编译器的自动向量化吧。
总结
不得不说,编译器还是太牛了,我做代码优化的时候,上面提到的这些优化很少有实际有用的,最后还是对算法架构动刀,重构了关键代码才勉强有了提升。
在我单独测试的时候,很多循环的优化和缓存上的优化都被自动完成了,根本不需要手动来完成。