针对相机模型、和位姿估计问题的一些记录
相机模型
如果仅仅从相机的角度来看
相机会把外界物体投影到相机的成像平面上,本质上可以看成是小孔成像,利用相似三角形的原理,可以很容易理解近大远小。
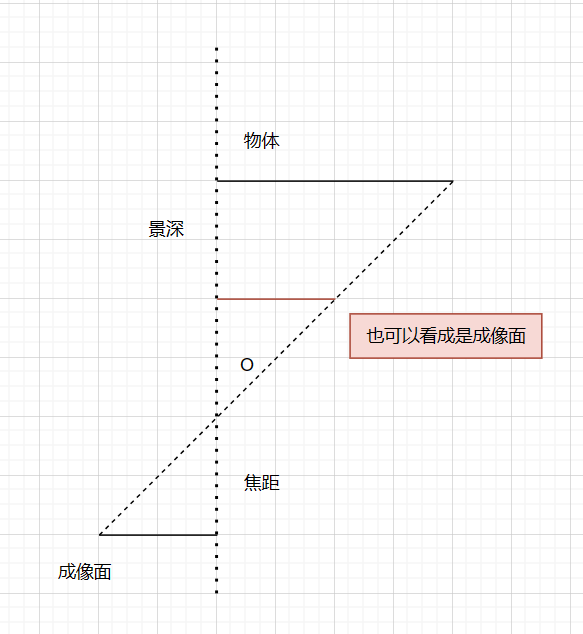
如果记焦距为
(理论上来说,右边两项应该添加负号,因为小孔成像是对称的,但是为了方便起见,可以把成像面也同样做对称处理)
也就有
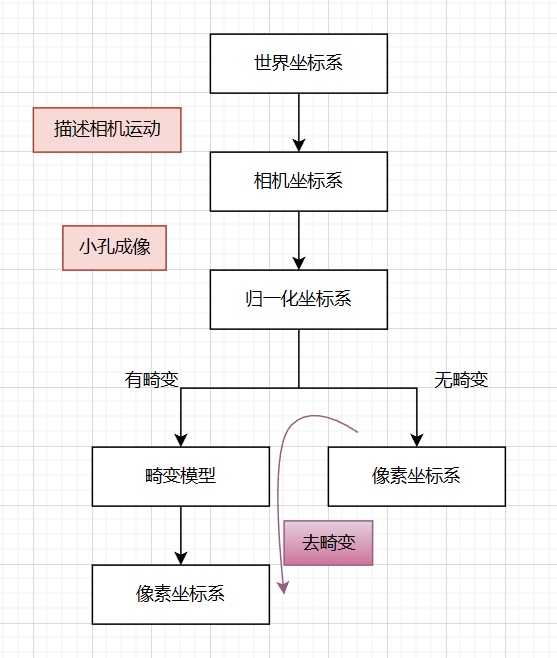
上诉内容描述的是从相机本身角度而言的成像,也就是相机坐标系到归一化坐标系的步骤,但是实际上机器人上的相机有多个坐标系,每个坐标系有不同的用途。
世界坐标系
世界坐标系指的就是物体在真实世界中的坐标,这个坐标系的用途就是描述位姿,由于相机在运动,对于世界坐标系中的一个固定点
通过世界坐标系和相机坐标系的变换,就可以可以得到相机坐标系下的坐标。
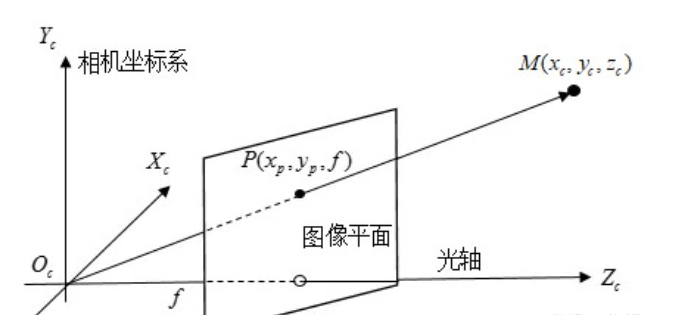
相机坐标系
相机坐标系就是以相机的光心为原点,以相机自身为参考系。这个坐标系的作用就是用于描述成像,之前已经得到了
下面这个变换描述的是相机坐标系向归一化坐标系的变化公式。
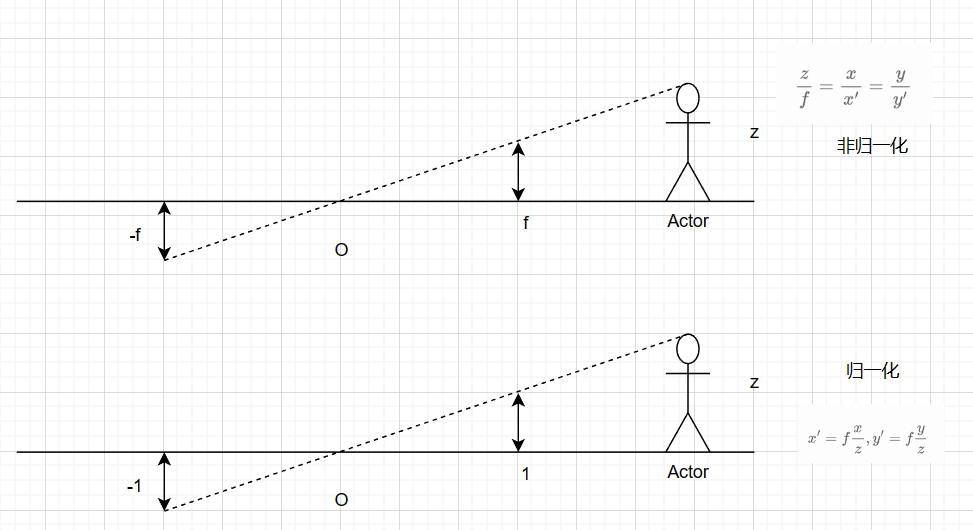
归一化坐标系
本质上,归一化坐标平面就是一个二维的平面,也就是小孔成像的平面,这个平面的作用就是用于描述相机坐标系下的成像,至于为什么叫做归一化坐标系,是因为在
在归一化坐标系中,物体的深度信息被全部丢失,可以看成是物体所有坐标同时除以z,无法通过归一化坐标系来复原出物体的深度信息了。
但是归一化坐标系的原点是中心,而一般我们在描述图像的坐标时候,都是以左上角为原点,向右为x轴,向下为y轴,且两者的单位基底一般是不一样的,所以这里面存在一个平移和放缩的步骤,这就引出了归一化坐标系向像素坐标系的变化公式。
如果认为x轴放缩α倍,y轴放缩β倍,平移量为
像素坐标系
像素坐标系其实就是我们最终得到的图像,如果我们直接使用相机坐标系来表示,那么有如下形式
其中
相机畸变
相机畸变有两种:径向畸变和切向畸变,其中径向畸变又分为桶形畸变和枕形畸变。
如果把归一化平面中的像素用极坐标来表示,那么沿着径向发生的畸变就是径向畸变,沿着切向发生的畸变就是切向畸变。
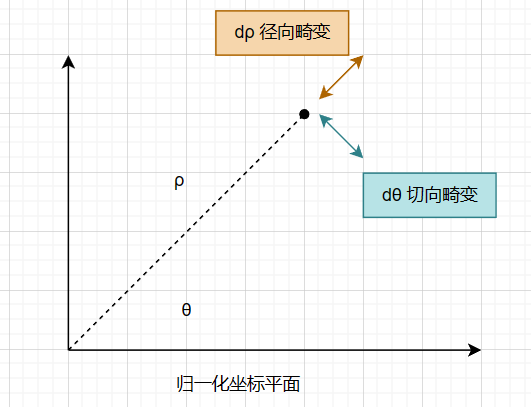
其中径向畸变是因为透镜本身不够理想,而切向畸变则是因为透镜安装方向与平面不平行。
由于径向畸变的程度与距离原点的距离有关,且一般为一个非线性函数,如果对其进行泰勒展开,就能得到一个关于
而对于切向畸变,由于透镜安装方向与平面不平行,所以会导致x和y方向上的畸变不一样,所以有
这样就可以通过5个参数来描述相机的畸变情况了。
引入畸变后的成像模型
相机的畸变作用在相机坐标系到归一化坐标系之间,所以我们可以得到相机的成像步骤为:
- 世界坐标系下的一点
- 由于相机在运动,通过世界坐标系和相机坐标系的变换,得到相机坐标系下的坐标
- 这时得到的
有三个分量 ,将其作用在归一化坐标系上为 - 然后在归一化坐标系中,由于相机的畸变,得到畸变后的坐标
- 最后将畸变后的坐标作用在像素坐标系上,得到最终的像素坐标
畸变矫正
由于畸变的存在,会导致相机成像的结果与真实情况有偏差,所以需要对图像进行畸变矫正,也就是将畸变后的图像变回畸变前的样子。
假设我们标定出来了相机的畸变参数,那么我们自然希望对图像进行校正。
由于畸变是一个非线性过程,对其求逆相当困难,所以不是从畸变后的图像中计算每个像素点的原来位置,而是从一个空白图像开始,计算每个像素畸变后应该位于哪个位置,并用畸变后的图像中的像素值填充。
状态估计
SLAM的模型由一个运动方程和一个观测方程组成,运动方程描述的是机器人的运动,观测方程描述的是机器人的观测。
第一个方程为运动方程,表示新的状态为上一个状态加上运动的增量,其中
如果通过概率的方式来进行位置求解,那么本质是在求已知输入数据和观测数据下的位置最优估计
利用贝叶斯公式展开有
换句话说,我们需要求解出通过在当前位置时机器人的运动和观测的概率以及此位置机器人出现的概率,就能完成对机器人位姿的估计了。
如果我们把
下面需要来对这个最大似然估计进行求解。
结合最大似然估计的性质和已知观测噪声为高斯噪声,自然想到通过最小二乘法来求解最优状态(也可以通过对对高斯噪声进行取负对数,但是个人感觉注意到通过最大似然可以求解位姿后,很容易想到使用最小二乘法来减弱噪声干扰。但显然前者在数学上更加严谨)
另外,对最小二乘法进行求解时,需要求解其导数,结合之前说的李代数可以使用加法来求导,而旋转矩阵(李群)对加法没有良好的定义,所以求解最小二乘时需要把李群转换成李代数来求解。
还记得扰动模型和导数模型嘛
优化算法
如果优化目标为
深度学习中经常使用梯度下降法来优化目标,除了梯度下降法,还有如牛顿法和拟牛顿法等方法。
梯度下降法和牛顿法类似,就是将目标函数
逆牛顿法则不是对目标函数进行泰勒展开,而是对构成目标函数的函数