典型特征点与匹配求解位姿的方法
特征点
在SLAM里,特征点法是很常用的构建视觉里程计的方法,特征点就是能够描述图像的一些点,在选出特征点后,还需要进一步计算这些特征点的描述子,这样就能将其用于匹配。
特征点有很多,比如最基本的角点,但是一般更常用的是带有尺度、旋转不变性的SIFT、SURF、ORB。
解决尺度不变性的方法是:对图像进行多次降采样,构成尺度金字塔,并在每一层上进行计算特征点
解决旋转不变性的方法是:找出一种即使图像旋转,也能稳定计算特征点的方向的算法,这样就能就能保证对特征点的描述包含旋转信息
SIFT
SIFT论文第一版是在1999年发布的,但是后来作者又在2004年整理了一篇更好的论文。(图像取自原文)
https://www.cs.ubc.ca/~lowe/papers/ijcv04.pdf
SIFT主要分为四个步骤:
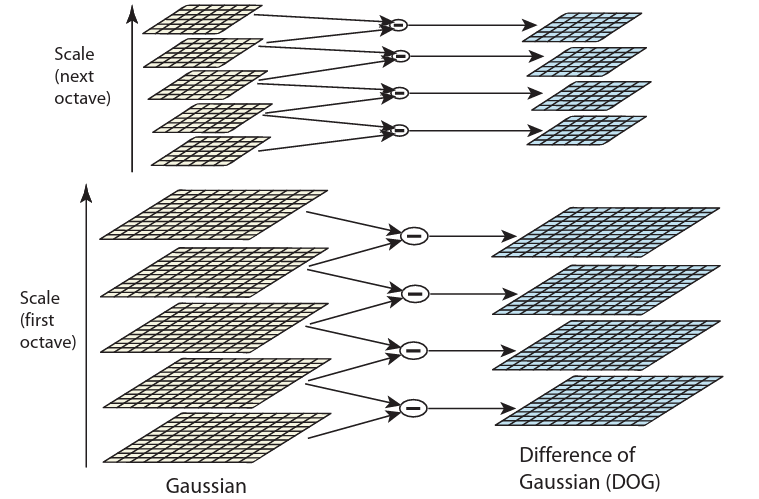
1. 高斯差分金字塔
首先,把图像进行降采样,得到图像尺度金字塔,然后对于每一层图像,使用不同大小的高斯核来进行滤波,然后两两做差得到高斯差分金字塔。
计算高斯差分金字塔的目的是为了等效高斯-拉普拉斯金字塔,这样做能减少计算量。
为了提取特征点,肯定需要计算导数,所以拉普拉斯算子是必须需要的。但是拉普拉斯算子对于噪声非常敏感,所以在做拉普拉斯算子之前,还需要使用高斯函数进行图像滤波,这样先高斯滤波--再拉普拉斯算子就能得到高斯-拉普拉斯金字塔。
但是拉普拉斯算子是卷积操作,所以计算量相对而言比较大,而同时注意到使用不同高斯核得到的高斯金字塔做差分后可以很好的去等效拉普拉斯金字塔,所以就有了高斯差分金字塔。(毕竟做差仅仅只是对应元素减法操作,而卷积则存在非常大量的乘法)
可以简单理解成,不同的边缘在不同的高斯滤波作用下平滑程度不一致,所以做差后就能凸显边缘
但是用高斯-拉普拉斯金字塔去等效的时候,高斯核必须要比构建的高斯-拉普拉斯金字塔层数多两个(因为顶层和最底层没法做差了)
2. 特征点
然后需要在高斯差分金字塔中寻找特征点,主要包括检测、定位、筛选。
然后需要在3个相邻层中,也就是26个点中去寻找最大的特征点,因为在3层中计算特征点时的可重复性最高。这样做其实就是计算不同尺度的下的特征
在得到特征后,接下来还需要进行非极大抑制和亚像素级别的特征点检测。
非极大抑制很好理解,就是通过阈值来消除特征点。亚像素定位是因为图像经过多次降采样、高斯滤波后特征点很可能已经移位,所以需要定位特征点原来的位置,通过泰勒展开和曲线拟合来完成。
3. 方向检测
接下来需要对特征点进行方向上的检测。
在特征点周围选择一个领域(是对应层的3δ范围)。然后统计这个邻域内的各个点的方向,并按照每10度一个bin加权统计出一个直方图,然后找出直方图中最大的值,作为特征点的主方向。
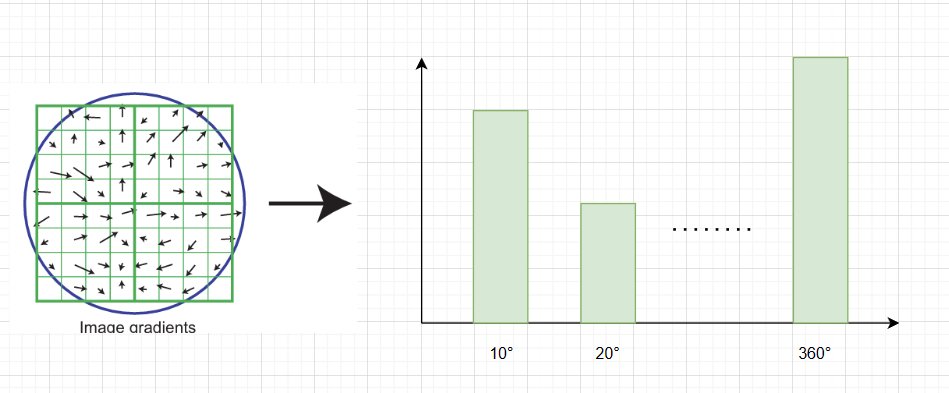
除了主方向外,还需要为幅值大于0.8主方向的的方向分配辅方向,这样就能保证特征点的旋转不变性。这样就为特征点计算了方向信息,每个特征点可能不止一个方向(一个主方向和若干个辅方向)。
4. 特征描述
最后一步是完成对特征点的描述,描述子是用于后续的匹配工作。
首先我们已经计算出了特征点的方向(有多个方向的特征点每个方向都要作为一个新的特征点),下一步需要把特征点和其邻域的像素进行旋转,把所有特征点的方向都旋转到一个方向,这样就能很好的保证旋转不变性。
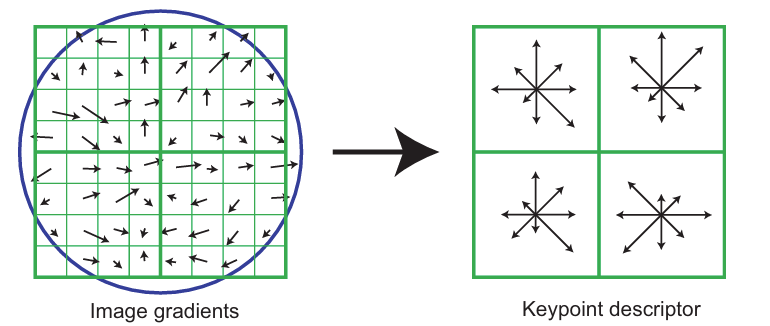
可以把邻域划分成4x4、8x8、16x16的小块,每四个小块划分成一个大块,然后每个大块有8个方向,一般使用16x16的划分,这样就有4x4x8=128维的描述子。
SURF算法
SURF可以理解成对SIFT的改进,他减小了描述子维度,同时加快了计算速度。
1. 构建尺度空间
为了提取特征点,SIFT算法使用高斯差分金字塔来代替高斯拉普拉斯金字塔从而减少计算量,但是高斯滤波本身计算量还是很大,所以SURF算法使用了盒式滤波代替高斯滤波,这样就能大大减少计算量。(也可以看成是使用盒式滤波器来代替高斯拉普拉斯算法,其实是一个二阶导hessian矩阵等效)。
使用此方法同样也能构建出一个类似高斯-拉普拉斯金字塔的尺度空间

2. 特征点
特征点的计算沿用SIFT的那一系列方法,跟SIFT无本质上的差异。
3. 方向检测
SURF在方向检测上与SIFT有较大差异,SURF算法是统计特征点邻域内的haar小波特征,并以60度一个扇区统计x和y方向上的小波特征,并进行高斯加权累加,以15度作为一个步长,旋转这个60度的扇区,将数值最大的那个扇区对应的方向作为主方向
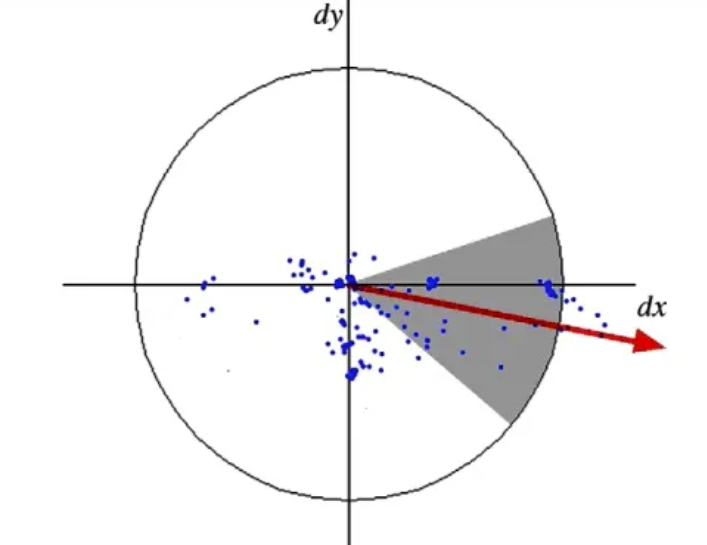
4. 特征描述
每个特征点在得到方向后,把加权的窗口(窗口大小20x20,而SIFT的领域大小是根据层来定的)按照方向进行旋转(SIFT是旋转邻域像素),然后划分成4x4的区块,每个区块有5x5的像素,统计出每个区块的水平和垂直方向的haar小波特征和绝对值之和,然后组成一个64维(每个区块4个描述,4x4个区块)的描述子。
ORB算法
因为SIFT和SURF的开销都很高,所以ORB算法应该是用在SLAM中最多的算法了吧,ORB基于Fast角点,但是在Fast角点的基础上加入了旋转不变性和尺度不变性,然后使用BRIEF作为特征描述子,在速度上很快,而且精度还不错。
1. 构建尺度空间
ORB构建尺度空间的方法很简单,就是直接降采样,然后把所有降采样后的图像拼接成一个大图,剩下的操作就在这个大图上进行。
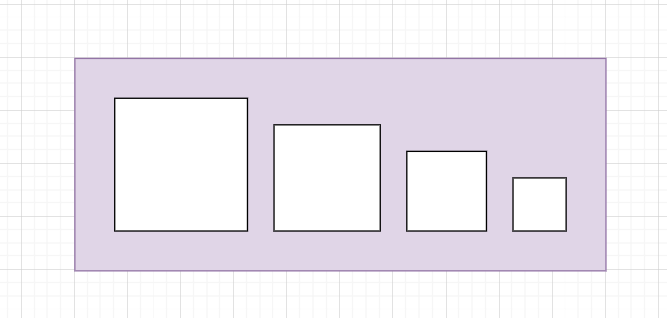
2. 特征点
ORB算法使用Fast角点作为特征,Fast角点的检测方法很简单,就是在一个圆上选取16个点,然后判断这16个点是否都大于或者小于中心点的像素值,如果都大于或者小于,那么这个点就是角点。当然还有一些别的方法,比如Fast-9、Fast-10、Fast-12等,就是在圆上选取9、10、12个点,然后判断是否都大于或者小于中心点的像素值。
3. 方向检测
上述选出的特征点是没有方向的,所以下一步就是为Fast角点添加方向,也就变成了oFast角点。
方法是,计算特征点周围像素的质心,然后计算质心和特征点的连线,然后计算连线的方向,这样就能得到特征点的方向。
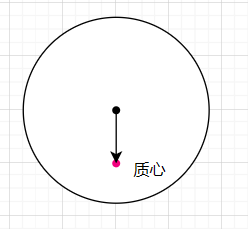
4. 特征描述
ORB算法使用BRIEF作为特征描述子,BRIEF是一个二进制描述子,它的计算方法是,随机选取一些像素点对,然后比较这些像素点对的像素值,如果第一个像素点的像素值大于第二个像素点的像素值,那么就把这个像素点对的二进制值设为1,否则设为0。
当然,这个随机选择也可以指定随机方式,有很多选择。一共生成256对这样的点,这样就能得到一个256位的描述子,每位只有0或者1,可以用4字节存储。
当然,为了考虑旋转不变性,所以选择时需要按照特征点的方向进行旋转,这样就能保证旋转不变性。(也叫做rBRIEF)
相机运动与位姿求解
视觉里程计的作用就是根据图像的变换来估计出相机移动的位姿,也就是求解相机的运动。
通过上述特征点,我们可以得到两个图像的关键信息,下一步就是求解出位姿。
按照匹配的目标不同,可以分为以下几类:
- 2D-2D:知道前后两帧关键点的像素坐标,估计运动,在满足对极几何约束下,可以求解本质矩阵或单应矩阵来估计,也可以使用三角测量来计算深度信息
- 3D-2D:知道前一帧的三维点和后一帧的像素坐标,估计运动,可以使用直接线性变换来硬解,或者使用PnP转化成3D-3D问题来求解,同样可以使用非线性优化方法来求解
- 3D-3D:知道前后两帧的三维点,估计运动,可以使用ICP来求解,同样可以使用非线性优化方法来求解
2D-2D
也就是知道运动前后两帧的关键点对应的像素坐标,去估计位姿。
这些由同一相机在不同位姿下拍摄的图像的特征点具有一个几何上的关系,也就是对极几何,这里描述的是一个相机在两个位置下的对极约束,实际上对极约束也可以用于双目相机标定。
对极几何与对极约束
假设相机在两个位置分别拍摄到两帧图像
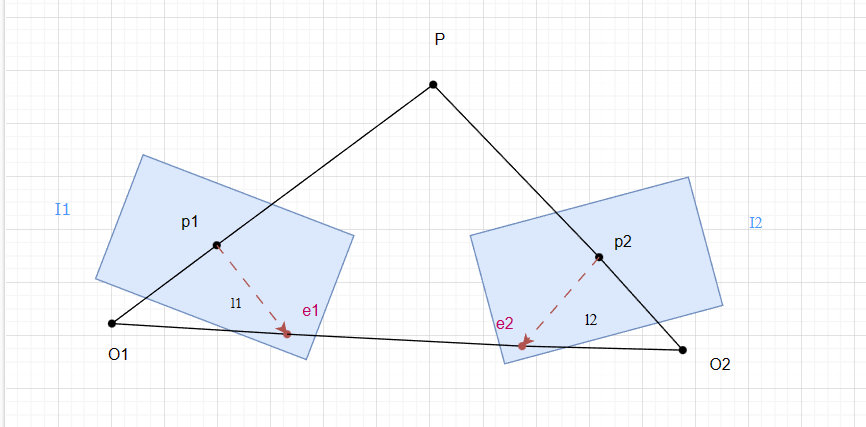
由于
对极约束可以让我们完成三个参数知2求1:
- 已知第一帧的
和空间点 可以求出第二帧中 的像素坐标位置分布,这可以用于双目相机标定(把不定位置的匹配转化成沿着极线的匹配,大大降低计算量) - 已知第一帧的
和第二帧的 可以求出空间点 ,只要让两个涉嫌相交即可,可以用于三角测量
当然,上述的分析都是定性的,下面用坐标的关系来进一步通过代数来描述。
假设
这里的
可以记上述投影关系为尺度意义下相等,记作
回代上式:
另外,记对应归一化平面上的像素坐标为
带入上式,可以得到:
也即是:
然后两边左乘
继续左乘
此时对于等式左侧,
上式即为对极约束,当然如果把
记本质矩阵
那么进一步简化等式为
通过本质矩阵和基础矩阵就可以求解位姿,对于2D-2D匹配问题,一般先通过多个匹配点对求解出本质矩阵或基础矩阵,然后进一步使用SVD求解出位姿的R和t
通过本质矩阵或基础矩阵求解位姿
本质矩阵和基础矩阵只相差一个相机内参,而相机内参通过一次标定即可获得,所以两者本质上没有太大差别
而本质矩阵
- 本质矩阵乘以任意常数后仍然满足约束,也就是不同尺度下对极约束等价
- 本质矩阵的奇异值必定是[σ, σ, 0]的形式,也就是内在性质,所以不是任何一个3x3的矩阵都能作为本质矩阵
- 由于旋转和平移都是3个自由度,再减去尺度等价性,所以可以看成本质矩阵仅有5个自由度,所以最少可以使用5个点对来估计,但是考虑到匹配点数目一般都是很多的,所以8点法也很实用,并且更简单,只需要解线性方程即可
八点法
堆积约束为
这样每一对点都能构成这样一个等式,而需要求解的只有8个未知数(尺度等价性可以消去一个维度),所以只需要8对点组成8个方程,即可求解出本质矩阵。
有了本质矩阵,就可以反解出位姿,主要使用奇异值分解
另外,由于内在性质,第一个奇异值和第二个奇异值是相等的,所以在重排奇异向量时,第一列和第二列顺序可以互换,我们用一个可以表示旋转的矩阵来表示这一过程
奇异值分解可以用下图来进行形象的描述,因为
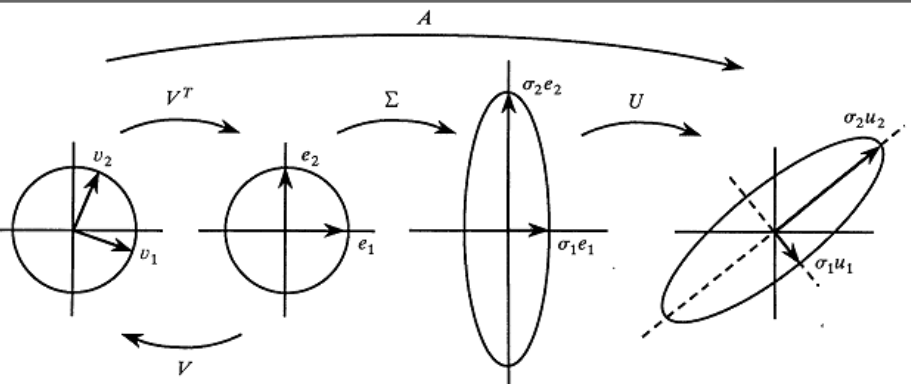
而本质矩阵第一个第二个奇异值相等,也就是说第一维和第二维可以交换而不受影响,而同时本质矩阵还具有尺度等价性,也就是
也就是
仍然有
同时
同时考虑对极约束
而
此外,再次考虑本质矩阵的尺度等价性,所以对
最后,使用线性法解出的本质矩阵的奇异值可能不一定是[σ, σ, 0]的形式,可能是
单应矩阵
单应矩阵描述了特征点位于同一平面上,比如墙面、地板等。假设两张图像
带入
这样就能得到
由于这个矩阵和本质矩阵类似,所以可以使用同样的方法来求解出位姿(同样需要进行分解才行)
这种把矩阵中的参数看成向量,求解线性方程后再恢复矩阵的方法叫线性变换法
如果相加发生纯旋转或特征点共面,那么本质矩阵将发生退化,会影响到位姿求解,而使用单应矩阵则能够很好的估计位姿。
由于本质矩阵的尺度不确定性,导致计算出来的位移
而在初始化初读信息时,如果仅仅只有纯旋转,那么将导致
3D-2D
3D-2D是已知前一帧的三维点和后一帧的像素坐标,去估计位姿。此时只需要3个点对即可完成估计,3D坐标一般是RGBD相机或双目相机测量得到,且不需要对极约束。一般有直接线性变换、PnP、非线性优化等方法。
三维点坐标指的是空间坐标系坐标,而不是相机坐标系坐标
直接线性变换
之前我们同样使用过直接线性变换方法去求解本质矩阵和单应矩阵,这里也可以使用直接线性变换方法去求解位姿。其本质就是联列方程然后求解
3D-2D的3D坐标指的是空间坐标,但是这里需要求解位姿,这个是相机坐标系的变换,所以我们虽然得到的可能是前一时刻的相机坐标系的3D坐标,但是还是要把它看成是一个空间坐标系中的点,然后求解当前时刻相机坐标系与这个空间坐标系的位姿变化。(也就是把3D的点的坐标系直接作为空间坐标系)
如果空间点
这里面的未知数是
但是,这样求解出来的T可能分解后不能得到一个旋转矩阵,所以还需要求解一个与最近似的旋转矩阵,可以使用QR分解来完成。
P3P
P3P是指3个点对求解位姿,它的思想其实是把3D-2D问题转化成3D-3D问题,也就是把3D点投影到另一个坐标系中,然后求解两个坐标系之间的位姿变换。(也就是转化成ICP问题)
P3P需要3对3D-2D匹配点,并且这个输入的3D的点坐标是空间坐标系的坐标,
由于我们知道了三个点,所以可以得到一个三角形。
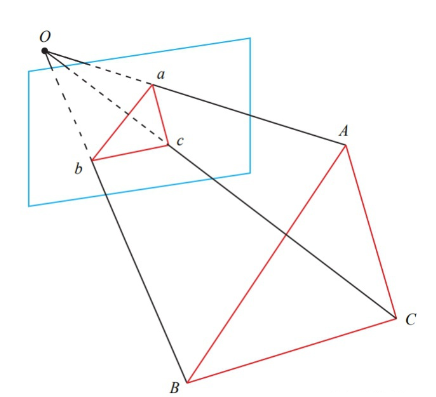
上图中
利用三角形的余弦定理,利用
上式全部两边除以
记
可以利用第一个式子消去
通过吴消元法,可以把上述两个二次方程转化成一个一元四次方程和一个一元一次方程,所以主要的任务还是求解一个一元四次方程,当然也可以通过其他方法转化成一元三次方程,但是目前来看主要的方法还是去求解这个一元四次方程
比如可以基于HC(同伦连续)去解这个一元四次方程就可以求解p3p问题
当然,因为P3P只使用了3个点的信息,所以如果点数过多,或者3个点噪声干扰较大,可能就会难以利用更多信息。所以一般使用RANSAC(随机采样一致)来进行求解,同时也可以使用EPnP来进行求解,EPnP是PnP的一种改进算法,可以使用更多的点对来求解,而且求解速度更快。
优化方法求解
同样,可以最小化重投影误差来求解位姿,也就是通过优化的手段来求解。优化时同时优化位姿和空间点,而不需要单独求解。
假设有若干2D-3D匹配点,那么有
我们的优化目标为,因为已知了2D和3D点,求解位姿,只需要求当前位姿估计下3D点的2D坐标的投影误差和即可
这个就是一个最小二乘问题,由于涉及到了特殊欧式群的求导,所以可以使用李代数来把使用良好定义的加法来求导。
误差对位姿的导数
这个导数可以用于优化位姿,记误差为
其中第二项是李代数的导数,可以用扰动模型来计算。
而第一项是误差关于投影点的导数,而利用相机模型,可以得到投影点和相机坐标系关系为
因此
这样就可以得到对位姿的导数,可以通过若干已知的点对来求解位姿(因为李群没有加法,所以需要转化成李代数用加法求导)
误差对特征点的导数
这个导数可以用于特征点的位置,记误差为
其中第一项前面已经给出,而第二项因为
这样就能求出误差对于空间点的导数,可以在位姿已知的情况下,求出理想的2D对应的3D空间坐标
3D-3D
3D-3D问题就是两组3D点之间的匹配。3D-3D的位姿求解相对简单,主要分为SVD这类直接求解的方法啊,当然,也可以通过优化的方式完成求解。
3D-3D问题一般不涉及相机模型,因为相机模型主要是2D点与3D点之间的桥梁
SVD求解
这就是通过代数的手段,来求解出位姿,不过这种方式其实是对最小二乘法使用非迭代的方式求解,先定义第i对点的误差项
那么得到优化目标
定义质心
然后有
其中
注意到左边一项仅跟旋转矩阵有关,而右边一项与旋转矩阵、平移向量都有关。所以先计算去质心坐标后优化旋转矩阵,得到旋转矩阵后令右边一项为0从而求出旋转向量,其中求旋转向量很容易,就是解一个方程,难点主要在求旋转矩阵上。
我们利用内积展开平方:
由于前两项与旋转矩阵无关,所以只需要优化最后一项即可(旋转矩阵为正交矩阵),然后可以利用二次型的迹表示法,得到:
然后定义矩阵并做SVD
那么旋转矩阵即为
原文中这里是
在求出旋转矩阵后,带入方程即可求出平移向量
优化求解法
我们可以利用特殊正交群去表示欧式变化,然后优化两者之间的误差即可:
此时是使用李代数来表示变化,所以求导只需要使用李代数的扰动模型即可。并且ICP问题是凸优化,极小值就是最小值。