阅读一篇关于事件相机的综述的论文。
Event-based Vision: A Survey
因为后续可能去做事件相机的相关工作,所以先阅读一下综述,首先被推荐的是这篇论文,所以顺带记录一下。
事件摄像机是不同于传统摄像机的仿生传感器,它并不是以固定的帧率拍摄图像,而是异步测量每个像素的亮度变化,并输出一个使用时间、位置对亮度变化进行编码的流。
与传统摄像机相比,事件摄像机具有以下特性:高时间分辨率(μs量级)、非常高的动态范围(140dB vs 60dB)、低功耗和高像素带宽(kHz量级),并且显著降低运动模糊。因此,事件摄像机在特定的机器人或计算机视觉领域中具有巨大潜力,例如低延迟、高速和高动态响应的场景。
然而,需要新的方法来处理这些传感器的非常规输出。这篇综述全面概述了基于事件的视觉新兴领域,关注一些为了更好开发事件相机潜能的算法。从事件摄像机的工作原理、可用的传感器和它们目标任务,从低级视觉(特征检测和跟踪、光流等)到高级视觉 (重建、分割、识别)。
我们还讨论了为处理事件相机而开发的技术,包括基于深度学习的技术(例如脉冲神经网络),以及用于这些新型传感器的专用处理器。此外,我们必须认识到事件相机还有很多需要解决的问题。在开发更有效、受生物启发的传感器的过程中,仍有待解决的挑战和机遇。
事件相机的介绍与应用
事件相机并不会像传统摄像头那样以规定帧率输出图像,而是以异步的方式测量每个像素的亮度变化,并输出一个使用时间、位置对亮度变化进行编码的流。所谓异步就是它并不是像素立刻变化就输出,而是为每个输出的流打上一个时间戳。
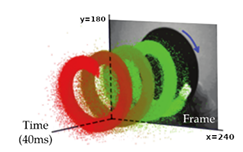
它的优势非常明显:它的时间延迟非常低,而且功耗也显著低于传统摄像头,因为它只有在像素发生变化的时候才会输出,而不是像传统摄像头那样每隔一段时间就输出一帧图像,并且它的动态响应也非常好。
但是,由于事件相机以一种非常特别的方式进行输出(也就是它每次只输出像素的变化而不是测量像素的绝对亮度),所以一些传统的算法并不能很好的直接移植到事件相机上。
事件相机的原理
这里就暂且略过事件相机的物理原理(也就是晶体管那些东西),它输出的每个像素的变化被称为事件,事件是通过数字总线读出的,也就是地址事件表示形式AER(address-event representation)
另外,事件相机也是数据驱动的传感器。当拍摄的运动越快,相机每秒生成的事件也就越多,因为每个像素都根据其监控的对数强度信号的变化率调整其增量调制器采样率。事件以微秒分辨率加盖时间戳,并以亚毫秒级延迟传输,这使得事件相机能做出快速反应。
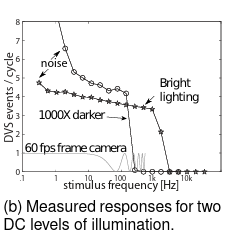
但是事件相机还有另外一个特性:在低频时,DVS像素每个周期产生一定数量的事件。但是一旦超过某个截止频率,那么变化就被感光器动力学滤除,因此每个周期的事件数下降。
事件相机的设计
事件相机的设计有很多种,下面介绍几种常见的
- DVS(Dynamic Vision Sensor):这是最早的事件相机,它的像素是单独的,每个像素都有自己的电路,它的输出是一个事件流,每个事件都包含了像素的坐标和时间戳,但是它的分辨率比较低(因为每个像素都有很大的电路),而且它的像素是单独的,所以它的成本比较高。另外,它只能输出亮度变化,而不能输出绝对亮度
- Asynchronous Time Based Image Sensor (ATIS) :这种事件相机的每个像素都包含一个读取亮度变化和绝对亮度的传感器,所以可以同时读取两种数据,并且它的动态响应也很高(由于读取两个传感器时间也会更多,这也限制了动态响应进一步提升),但是每个像素的电路面积是DVS的两倍,所以它的成本也比较高。
- Dynamic and Active Pixel Vision Sensor(DAVIS):这是目前用的最多的事件相机,它将同一像素中的传统有源像素传感器(APS)与DVS相结合。ATIS的尺寸要小得多,因为光电二极管是共享的,读出电路只会增加DVS像素面积。这是目前大多数采用事件相机的CV项目选用的事件相机类型。
事件相机优点
- 低延迟:事件相机的延迟非常低,因为它只有在像素发生变化的时候才会输出,而不是像传统摄像头那样每隔一段时间就输出一帧图像
- 高时间分辨率:是指他在时间上的分辨率很高,但是空间上由于每个像素尺寸限制,所以不会特别大
- 低功耗:由于它只有在像素发生变化的时候才会输出,所以功耗也会比较低
- 高动态响应:它的动态响应要远远高于传统帧率摄像头
事件相机缺点
- 低空间分辨率:由于每个像素的尺寸限制,所以空间分辨率不会特别高
- 仅灰度图像:一般事件相机只能输出灰度图像,而不能输出彩色图像
- 噪声敏感:事件相机存在一个亮度变化的触发阈值,为了获得尽可能多的数据,阈值一般比较低,所以噪声很容易触发输出
- 稀疏输出:事件相机的输出是稀疏的,也就是每个像素的变化都会输出,而不是像传统摄像头那样每个像素都会输出,这种格式会影响一些传统算法的移植
事件相机的模型
事件相机是通过对光强对数来进行编码的,所以可以使用此来描述光强(或亮度)
对于每个事件
其中
其中
另外,事件和时间的导数可以描述光强,对于一个很小的时间内而言,考虑一阶泰勒展开
当然这种方式并不像普通相机那样直接描述光强,它只是描述了光强的变化,但是这种方式也有它的优势就是了。
此外,事件相机的所有事件都是由移动的边缘引起的,这点很好理解,因为如果没有移动的边缘,那么光强就不会发生变化,也就不会产生事件。
同时,由于事件相机是存在噪声的,所以也可以使用概率模型去描述事件相机的输出,这也是事件相机的未来发展方向之一。
事件相机的可用性
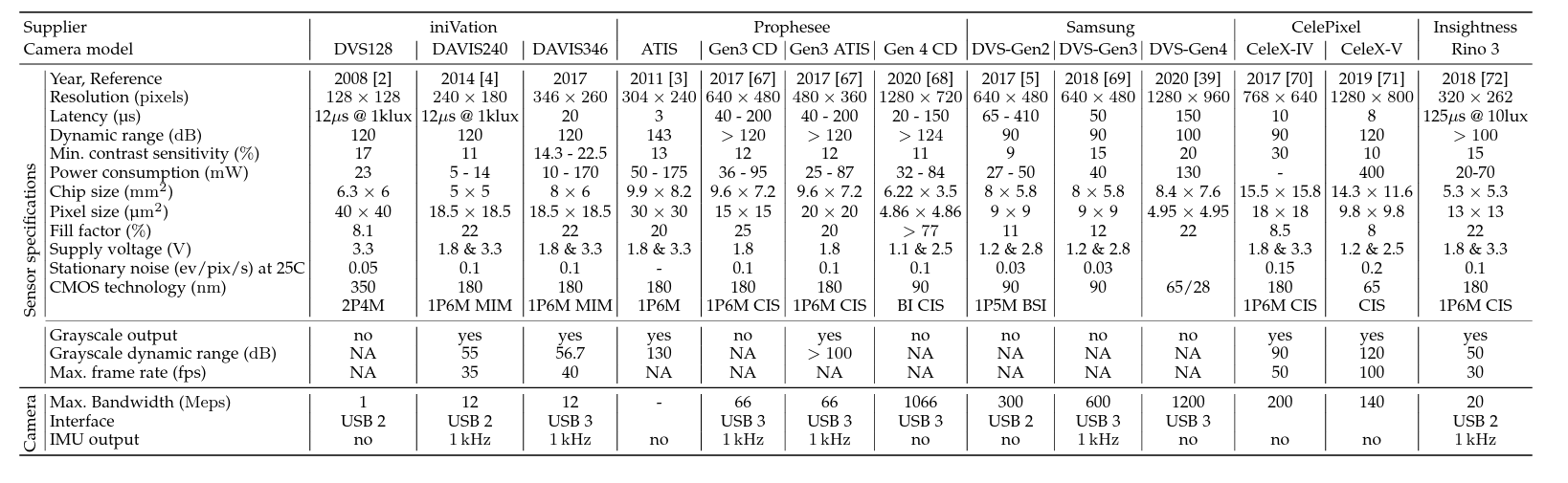
上图展示了一些事件相机,可以看到,事件相机的空间分辨率并不是很高,这主要就是因为传感器尺寸难以减小导致的。
另外,事件相机的成本很高,这也是限制其进一步应用的因素之一。
前面也说了,事件相机目前还只能输出灰度图像,同时对于噪声很敏感,这些都需要在应用中进行考量。
事件相机的数据处理
由于事件相机的输出的特殊性(异步、稀疏),所以存在很多种方式来处理其输出的流,而不同的处理方式都存在不同的应用领域。大致分为以下两种类型:
- 基于单个事件:每次收到一个事件就处理一个事件,这样延迟很低,但是会存在很多噪声
- 基于一组事件:将多个事件组合成一组再进行处理,这样可以减少噪声,但是延迟会比较高
另外,从事件是如何被处理的角度也可以分为:
- 基于模型:使用深度学习的方式来处理事件
- 基于优化:使用优化的方式来处理事件(几何、光度)
事件的表示
事件的表示是和应用以及后续处理密切相关的,使用不同的表示形式,能方便后续的处理。
- 单个事件(Individual events)/事件流(Event packet):使用
来表示,是最原始的表示形式,可以用于脉冲神经网络。通过选择合适长度的事件流,可以很好的表示时刻内的运动 - 事件帧/2D直方图(Event frame/image or 2D histogram):时空邻域中的事件以一种简单的方式(通过计数事件或按像素累积极性)转换成图像,可以馈送到基于图像的计算机视觉算法中。但是,结果图像对使用的事件数量非常敏感
- 时间面(Time surface):每个像素只存储该像素的最近的时刻的变化,时间越近那么表现得数值越大。由于只保留一个时间戳的信息,所以在纹理丰富、像素脉冲频繁的场景中有效性降低。但是它可以异步更新数据。
- 体素网格(Voxel Grid):是事件的3D时空直方图,其中每个体素代表一个特定的像素和时间间隔。
- 3D点集合(3D point set):也就是把
看成一个三维坐标,注意 是二维的坐标 - 平面点集(Point sets on image plane):把事件看作是平面上的运动的集合,可以用于ICP估计
- 运动补偿图像(Motion-compensated event image):是一种不仅依赖于事件而依赖于运动假设的表征。当边缘发生移动的时候(只有边缘能触发事件),可以使用这些触发的事件来估计运动
- 图像重建(Reconstructed images):通过对事件得到的亮度可以重建图像,比事件帧或时间面的运动不变性更好
下图是一些表示的可视化结果,分别为事件集合、事件帧、时间面、体素网格、运动补偿图像和图像重建

上述表示可以用于深度学习的输入数据,或是其他图像算法移植后的输入数据。
事件的处理方法
上面描述的事件表示可以用于算法不同阶段,下面再介绍一些关于不同事件表示的处理方法,每种处理方法可能不局限于一种表示
下面是一些针对单个事件进行处理的方法,这些方法的异步性和延迟都非常出色:
- 基于事件触发的方法(Event-by-event–based Methods):这种方法就对应最原始的处理手段,也就是使用类似卡尔曼滤波器、贝叶斯滤波器等滤波手段来对每个事件进行处理。这种方法可以很好的适应事件相机的异步输出,从而保持事件相机的低延迟的特性
- 多层神经网络(multi-layer ANN):这也是一种比较主流的方法,就是分为有监督和无监督(文中提到了SVM,但是这个也算是多层网络嘛?),这种方法也是使用单个事件作为输入。文中还提到了脉冲神经网络(SNN)可以用于嵌入式设备。
下面是一些针对事件包(event package)进行处理的方法,使用多个事件能够显著提升信噪比:
- 基于事件帧(event frame)的方法:这种方法就是将事件包转换成图像,然后使用传统的图像算法进行处理,这种方法可以很好的适应传统的计算机视觉算法
- 基于时间面(time surface)的方法:通过使用时间面,可以构建分层特征提取器,时间面可以结合较长的时间信息,来用于提取更多的特征。当然时间面也经常用于角点检测
- 基于体素网格(voxel grid)的方法:这种方法就是将事件包转换成体素网格,然后基于卷积或其他优化算法来实现
- 基于运动补偿图像(motion-compensated event image)的方法:一般使用连续时间的运动模型,并且结合IMU数据来进行处理
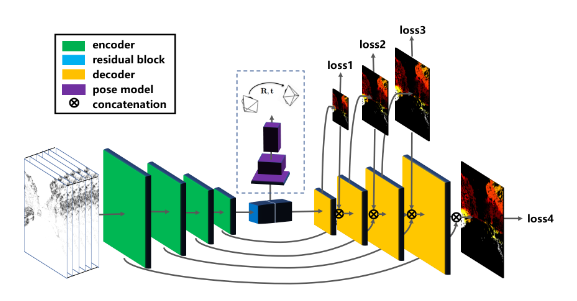
- 基于深度学习的处理方法:对于事件相机的深度学习模型一般都存在数个编码器和解码器,如下图所示
生物启发的视觉处理--SNN
SNN是脉冲神经网络,SNN使用脉冲(也即是时间点上的离散事件),由于事件相机的输出也是离散的,所以两者能很好地对应的上。每个峰值由代表生物过程的微分方程表示出来,其中最重要的是神经元的膜电位。本质上,一旦神经元达到了某一电位,脉冲就会出现,随后达到电位的神经元会被重置。对此,最常见的模型是 Leaky Integrate-And-Fire (LIF) 模型。
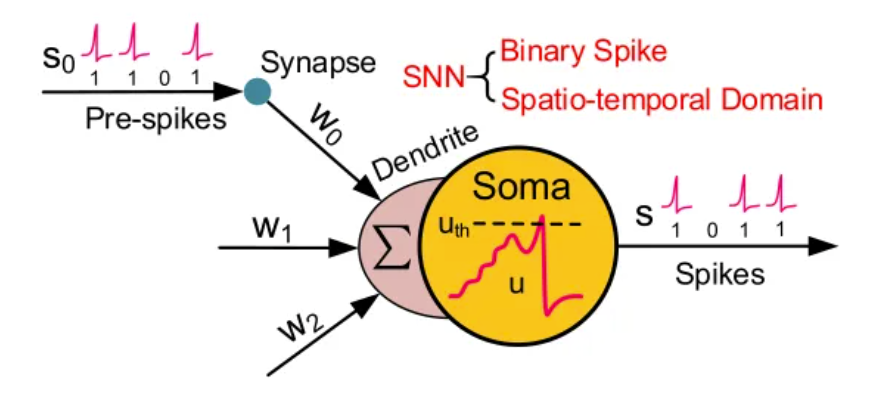
SNN使用脉冲的序列来传递信息,每个脉冲神经元都经历着丰富的动态行为。具体而言,除了空间域中的信息传播外,时间域中的过去历史也会对当前状态产生紧密的影响。因此,与主要通过空间传播和连续激活的神经网络相比,神经网络通常具有更多的时间通用性,但精度较低。由于只有当膜电位超过一个阈值时才会激发尖峰信号,因此整个尖峰信号通常很稀疏。 此外,由于尖峰值 (Spike) 是二进制的,即0或1,如果积分时间窗口为1,输入和权重之间的乘法运算就可以消除。由于上述原因,与计算量较大的ANN网络相比,SNN网络通常可以获得较低的功耗。