ORBSLAM2的普通帧Frame与关键帧KeyFrame
普通帧Frame
普通帧主要是记录特征点,同时根据相机内参进行去畸变,并计算出校正后的边界。每个普通帧会有一个参考关键帧,为共视程度最好的关键帧,但用于初始化的两个普通帧的参考关键帧为自身,因为初始化时还不存在其他关键帧。
在Tracking过程中,会存储currentFrame和lastFrame两个普通帧,当前普通帧会根据恒速模型、关键帧跟踪或重定位来确定自身的位姿,因此普通帧中也存在存储自身位姿的数据结构。
特征提取与网格划分
特征点数目
会使用ORB特征提取器来提取特征,由于需要保证尺度不变性,所以需要构建图像金字塔,但是图像金字塔层数越高,对应的图像分辨率越低,因此层级越高的图像的特征点数目也会越少。在ORBSLAM2中,每帧图像提取的特征点数目是存在人为规定的上界的,记为N,同时金字塔层数固定为8层,每层分配的特征点数目是按每层面积的开方来等比例分配的,即第i层分配的特征点数目为
这里的s是金字塔放缩因子,默认为。
网格分配
这里的网格分配与ORB特征提取的四叉树不是同一个东西。四叉树的目的时非极大抑制,是在特征提取阶段进行的;网格分配的目的是加速匹配,是在特征提取完构造帧的时候进行的。
在构造每一帧时,会把像素坐标系分成若干个网格,然后计算每个特征点的坐标并将其分配到网格里,这样做目的是在匹配特征点时加速,也就是先按照网格来粗略查找,然后按照像素点来精细查找,例如在搜索匹配的过程中,都会使用下面这个函数来搜索一定范围内的特征点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
|
vector<size_t> Frame::GetFeaturesInArea(const float &x, const float &y, const float &r, const int minLevel, const int maxLevel) const
{
...
const int nMinCellX = max(0, (int)floor((x - mnMinX - r) * mfGridElementWidthInv));
if (nMinCellX >= FRAME_GRID_COLS)
return vIndices;
const int nMaxCellX = min((int)FRAME_GRID_COLS - 1, (int)ceil((x - mnMinX + r) * mfGridElementWidthInv));
if (nMaxCellX < 0)
return vIndices;
const int nMinCellY = max(0, (int)floor((y - mnMinY - r) * mfGridElementHeightInv));
if (nMinCellY >= FRAME_GRID_ROWS)
return vIndices;
const int nMaxCellY = min((int)FRAME_GRID_ROWS - 1, (int)ceil((y - mnMinY + r) * mfGridElementHeightInv));
if (nMaxCellY < 0)
return vIndices;
const bool bCheckLevels = (minLevel > 0) || (maxLevel >= 0);
for (int ix = nMinCellX; ix <= nMaxCellX; ix++)
{
for (int iy = nMinCellY; iy <= nMaxCellY; iy++)
{
const vector<size_t> vCell = mGrid[ix][iy];
if (vCell.empty())
continue;
for (size_t j = 0, jend = vCell.size(); j < jend; j++)
{
const cv::KeyPoint &kpUn = mvKeysUn[vCell[j]];
if (bCheckLevels)
{
if (kpUn.octave < minLevel)
continue;
if (maxLevel >= 0)
if (kpUn.octave > maxLevel)
continue;
}
const float distx = kpUn.pt.x - x;
const float disty = kpUn.pt.y - y;
if (distx * distx + disty * disty < r * r)
vIndices.push_back(vCell[j]);
}
}
}
return vIndices;
}
|
判断地图点是否在视野内
bool Frame::isInFrustum(MapPoint *pMP, float viewingCosLimit)这个函数在前文中的地图点也提到过,用于判断一个地图点是否在当前帧的视野内。具体而言,当一个地图点满足下面所有条件时,就认为该地图点在当前帧的视野内(也就是理论上可以被检测到)
- 相机坐标系约束:地图点投影到当前帧后深度信息为正,也就是地图点在相机前方
- 像素坐标系约束:地图点投影后的像素点位于帧畸变矫正后的有效像素区域内
- 特征提取约束:地图点与当前帧光心的距离在有效区域内,不然无法通过金字塔提取出来,有效距离的含义在地图点中也提到过了
- 视角约束:地图点平均方向和地图点与当前帧光心的夹角小于一定阈值,即地图点中所描述的平均观测方向
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
bool Frame::isInFrustum(MapPoint *pMP, float viewingCosLimit)
{
...
const cv::Mat Pc = mRcw * P + mtcw;
const float &PcX = Pc.at<float>(0);
const float &PcY = Pc.at<float>(1);
const float &PcZ = Pc.at<float>(2);
if (PcZ < 0.0f)
return false;
const float invz = 1.0f / PcZ;
const float u = fx * PcX * invz + cx;
const float v = fy * PcY * invz + cy;
if (u < mnMinX || u > mnMaxX)
return false;
if (v < mnMinY || v > mnMaxY)
return false;
const float maxDistance = pMP->GetMaxDistanceInvariance();
const float minDistance = pMP->GetMinDistanceInvariance();
const cv::Mat PO = P - mOw;
const float dist = cv::norm(PO);
if (dist < minDistance || dist > maxDistance)
return false;
cv::Mat Pn = pMP->GetNormal();
const float viewCos = PO.dot(Pn) / dist;
if (viewCos < viewingCosLimit)
return false;
...
return true;
}
|
对于双目与RGBD
对于双目与RGBD而言,会额外存储以下信息(单目下面两个数据结构都是-1):
mvuRight:左目特征点对应右目图像的横坐标(对极矫正后纵坐标是一样的)mvDepth:左目特征点对应的深度
如果是双目相机,由于在对极约束后可以直接得到mvuRight,因此需要根据视差来计算mvDepth;相反,对于RGBD相机而言,mvDepth是直接获取的,所以需要根据基线来反向计算出mvuRight
关键帧KeyFrame
在tracking线程中决定是否添加关键帧,关键帧具备普通帧的数据结构比如位姿、特征点、网格划分等等,但同样维护了一些用于优化的数据。
共视图与生成树
当两个关键帧能同时观测到至少15个共同的地图点时,就认为两者具有共视关系,共视权重为共同地图点数量。每个关键帧会按照权重降序存储共视帧,并单独记录共视权重最高的共视关键帧作为父关键帧。共视图会用于LocalMapping中扩大地图点以及LoopClosing中闭环检测和重定位,除此之外Tracking中也会利用共视关系来优化普通帧的位姿。
记录父关键帧的目的是维护生成树,每个关键帧只会存在一个父节点,但是可能会有多个子节点。生成树本身不会参与任何优化,其作用是在LoopClosing中创建本质图进行优化。(本质图仅用于闭环检测,本质图不止包含生成树,还包含闭环关系和一些较好的共视关系)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
void KeyFrame::UpdateConnections()
{
...
for(vector<MapPoint*>::iterator vit=vpMP.begin(), vend=vpMP.end(); vit!=vend; vit++)
{
MapPoint* pMP = *vit;
if(!pMP)
continue;
if(pMP->isBad())
continue;
map<KeyFrame*,size_t> observations = pMP->GetObservations();
for(map<KeyFrame*,size_t>::iterator mit=observations.begin(), mend=observations.end(); mit!=mend; mit++)
{
if(mit->first->mnId==mnId)
continue;
KFcounter[mit->first]++;
}
}
...
}
|
关键帧数据库KeyFrameDatabase
每个关键帧中还会存储一个关键帧数据库KeyFrameDatabase,记为KFDB,其中KFDB全局只会存在一个实例,它使用词袋作为特征,为每个关键帧构建特征集。其作用是通过词袋匹配在Tracking中重定位时获取重定位候选帧以及在LoopClosing中获取闭环候选帧。
KFDB里有两个比较关键的数据结构:
const ORBVocabulary *mpVoc:预先训练好的词典(本身也是个词袋),用于计算两个关键帧之间的相似程度std::vector<list<KeyFrame *>> mvInvertedFile:倒排索引,mvInvertedFile[i]表示包含了第i个word id的所有关键帧,用于粗略匹配候选关键帧
计算重定位候选关键帧和闭环候选关键帧时的步骤是极为类似的:
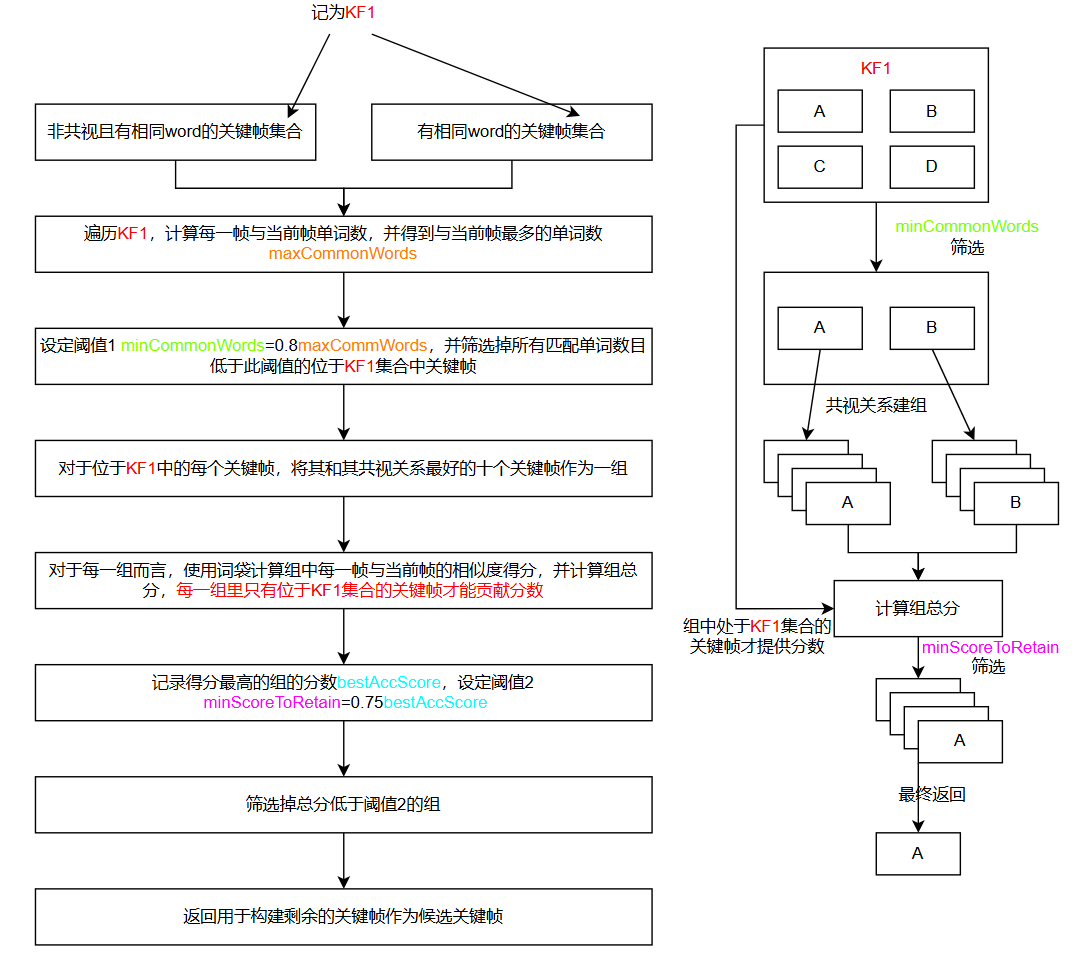
重定位候选关键帧(输入普通帧Frame)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
|
vector<KeyFrame *> KeyFrameDatabase::DetectRelocalizationCandidates(Frame *F)
{
list<KeyFrame *> lKFsSharingWords;
{
unique_lock<mutex> lock(mMutex);
for (DBoW2::BowVector::const_iterator vit = F->mBowVec.begin(), vend = F->mBowVec.end(); vit != vend; vit++)
{
list<KeyFrame *> &lKFs = mvInvertedFile[vit->first];
for (list<KeyFrame *>::iterator lit = lKFs.begin(), lend = lKFs.end(); lit != lend; lit++)
{
KeyFrame *pKFi = *lit;
if (pKFi->mnRelocQuery != F->mnId)
{
pKFi->mnRelocWords = 0;
pKFi->mnRelocQuery = F->mnId;
lKFsSharingWords.push_back(pKFi);
}
pKFi->mnRelocWords++;
}
}
}
if (lKFsSharingWords.empty())
return vector<KeyFrame *>();
int maxCommonWords = 0;
for (list<KeyFrame *>::iterator lit = lKFsSharingWords.begin(), lend = lKFsSharingWords.end(); lit != lend; lit++)
{
if ((*lit)->mnRelocWords > maxCommonWords)
maxCommonWords = (*lit)->mnRelocWords;
}
int minCommonWords = maxCommonWords * 0.8f;
list<pair<float, KeyFrame *>> lScoreAndMatch;
int nscores = 0;
for (list<KeyFrame *>::iterator lit = lKFsSharingWords.begin(), lend = lKFsSharingWords.end(); lit != lend; lit++)
{
KeyFrame *pKFi = *lit;
if (pKFi->mnRelocWords > minCommonWords)
{
nscores++;
float si = mpVoc->score(F->mBowVec, pKFi->mBowVec);
pKFi->mRelocScore = si;
lScoreAndMatch.push_back(make_pair(si, pKFi));
}
}
if (lScoreAndMatch.empty())
return vector<KeyFrame *>();
list<pair<float, KeyFrame *>> lAccScoreAndMatch;
float bestAccScore = 0;
for (list<pair<float, KeyFrame *>>::iterator it = lScoreAndMatch.begin(), itend = lScoreAndMatch.end(); it != itend; it++)
{
KeyFrame *pKFi = it->second;
vector<KeyFrame *> vpNeighs = pKFi->GetBestCovisibilityKeyFrames(10);
float bestScore = it->first;
float accScore = bestScore;
KeyFrame *pBestKF = pKFi;
for (vector<KeyFrame *>::iterator vit = vpNeighs.begin(), vend = vpNeighs.end(); vit != vend; vit++)
{
KeyFrame *pKF2 = *vit;
if (pKF2->mnRelocQuery != F->mnId)
continue;
accScore += pKF2->mRelocScore;
if (pKF2->mRelocScore > bestScore)
{
pBestKF = pKF2;
bestScore = pKF2->mRelocScore;
}
}
lAccScoreAndMatch.push_back(make_pair(accScore, pBestKF));
if (accScore > bestAccScore)
bestAccScore = accScore;
}
float minScoreToRetain = 0.75f * bestAccScore;
set<KeyFrame *> spAlreadyAddedKF;
vector<KeyFrame *> vpRelocCandidates;
vpRelocCandidates.reserve(lAccScoreAndMatch.size());
for (list<pair<float, KeyFrame *>>::iterator it = lAccScoreAndMatch.begin(), itend = lAccScoreAndMatch.end(); it != itend; it++)
{
const float &si = it->first;
if (si > minScoreToRetain)
{
KeyFrame *pKFi = it->second;
if (!spAlreadyAddedKF.count(pKFi))
{
vpRelocCandidates.push_back(pKFi);
spAlreadyAddedKF.insert(pKFi);
}
}
}
return vpRelocCandidates;
}
|
闭环候选关键帧(输入关键帧KeyFrame)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
|
vector<KeyFrame *> KeyFrameDatabase::DetectLoopCandidates(KeyFrame *pKF, float minScore)
{
set<KeyFrame *> spConnectedKeyFrames = pKF->GetConnectedKeyFrames();
list<KeyFrame *> lKFsSharingWords;
{
unique_lock<mutex> lock(mMutex);
for (DBoW2::BowVector::const_iterator vit = pKF->mBowVec.begin(), vend = pKF->mBowVec.end(); vit != vend; vit++)
{
list<KeyFrame *> &lKFs = mvInvertedFile[vit->first];
for (list<KeyFrame *>::iterator lit = lKFs.begin(), lend = lKFs.end(); lit != lend; lit++)
{
KeyFrame *pKFi = *lit;
if (pKFi->mnLoopQuery != pKF->mnId)
{
pKFi->mnLoopWords = 0;
if (!spConnectedKeyFrames.count(pKFi))
{
pKFi->mnLoopQuery = pKF->mnId;
lKFsSharingWords.push_back(pKFi);
}
}
pKFi->mnLoopWords++;
}
}
}
if (lKFsSharingWords.empty())
return vector<KeyFrame *>();
list<pair<float, KeyFrame *>> lScoreAndMatch;
int maxCommonWords = 0;
for (list<KeyFrame *>::iterator lit = lKFsSharingWords.begin(), lend = lKFsSharingWords.end(); lit != lend; lit++)
{
if ((*lit)->mnLoopWords > maxCommonWords)
maxCommonWords = (*lit)->mnLoopWords;
}
int minCommonWords = maxCommonWords * 0.8f;
int nscores = 0;
for (list<KeyFrame *>::iterator lit = lKFsSharingWords.begin(), lend = lKFsSharingWords.end(); lit != lend; lit++)
{
KeyFrame *pKFi = *lit;
if (pKFi->mnLoopWords > minCommonWords)
{
nscores++;
float si = mpVoc->score(pKF->mBowVec, pKFi->mBowVec);
pKFi->mLoopScore = si;
if (si >= minScore)
lScoreAndMatch.push_back(make_pair(si, pKFi));
}
}
if (lScoreAndMatch.empty())
return vector<KeyFrame *>();
list<pair<float, KeyFrame *>> lAccScoreAndMatch;
float bestAccScore = minScore;
for (list<pair<float, KeyFrame *>>::iterator it = lScoreAndMatch.begin(), itend = lScoreAndMatch.end(); it != itend; it++)
{
KeyFrame *pKFi = it->second;
vector<KeyFrame *> vpNeighs = pKFi->GetBestCovisibilityKeyFrames(10);
float bestScore = it->first;
float accScore = it->first;
KeyFrame *pBestKF = pKFi;
for (vector<KeyFrame *>::iterator vit = vpNeighs.begin(), vend = vpNeighs.end(); vit != vend; vit++)
{
KeyFrame *pKF2 = *vit;
if (pKF2->mnLoopQuery == pKF->mnId && pKF2->mnLoopWords > minCommonWords)
{
accScore += pKF2->mLoopScore;
if (pKF2->mLoopScore > bestScore)
{
pBestKF = pKF2;
bestScore = pKF2->mLoopScore;
}
}
}
lAccScoreAndMatch.push_back(make_pair(accScore, pBestKF));
if (accScore > bestAccScore)
bestAccScore = accScore;
}
float minScoreToRetain = 0.75f * bestAccScore;
set<KeyFrame *> spAlreadyAddedKF;
vector<KeyFrame *> vpLoopCandidates;
vpLoopCandidates.reserve(lAccScoreAndMatch.size());
for (list<pair<float, KeyFrame *>>::iterator it = lAccScoreAndMatch.begin(), itend = lAccScoreAndMatch.end(); it != itend; it++)
{
if (it->first > minScoreToRetain)
{
KeyFrame *pKFi = it->second;
if (!spAlreadyAddedKF.count(pKFi))
{
vpLoopCandidates.push_back(pKFi);
spAlreadyAddedKF.insert(pKFi);
}
}
}
return vpLoopCandidates;
}
|