MASt3R-SLAM与VGGT-SLAM的论文阅读笔记。
前面已经解析过MAST3R和VGGT了,我们接下来看下MASt3R-SLAM与VGGT-SLAM。
MASt3R-SLAM
MAST3R可以给出两张图像之间的相对位姿和点图,如果将连续的图像都放进来,那么就可以得到这些图像之间的相对位姿,并给出稠密重建的结果。当sfm重建时,因为图像之间没有时间上的连续性,所以需要先根据图像的特征来选出一个联通图,然后两两进行重建。但是因为SLAM系统因为图像是有时间上的顺序的,所以可以像传统的SLAM的系统一样,先选出关键帧,然后每到达一帧后跟关键帧进行结算,并在匹配数目较少的时候插入新的关键帧。
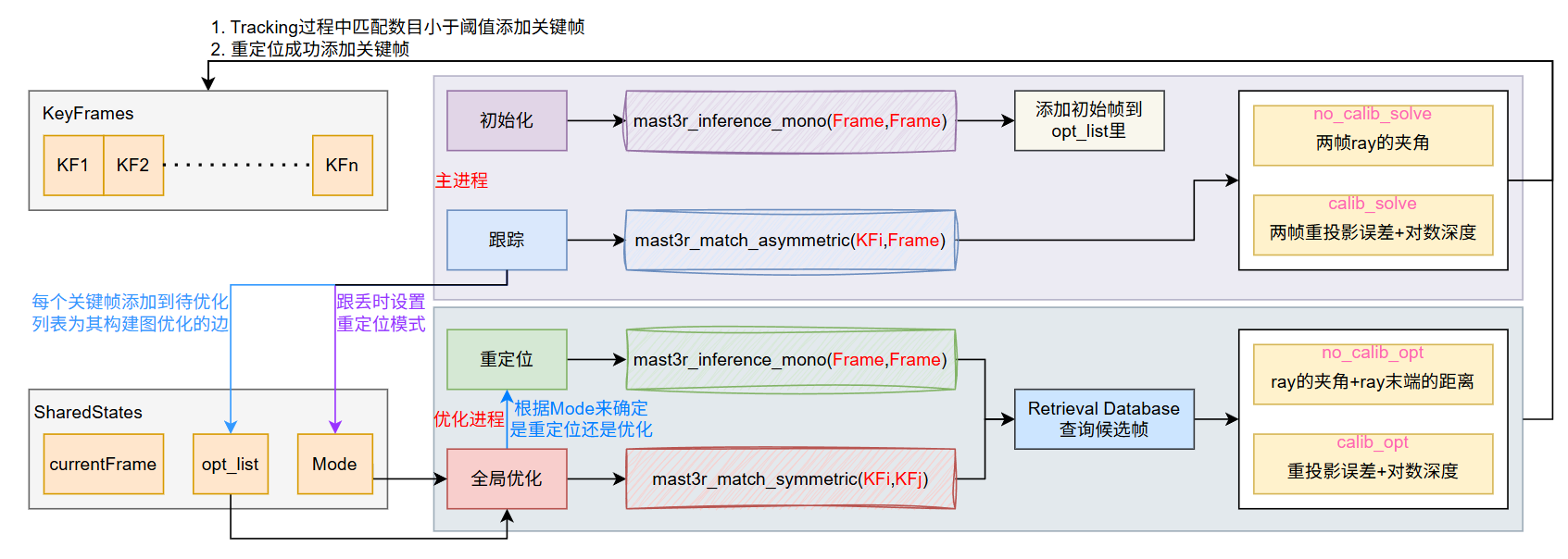
我们后续先来看一下MAST3R-SLAM的数据结构,然后再看下整个的Tracking流程,并最后再看一下优化和匹配的流程。
Frame、SharedStates和SharedKeyframes
MAST3R-SLAM使用Frame来管理所有帧,关键帧和普通帧没有本质区别,不过关键帧会全部被存放在SharedKeyframes里
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 @dataclasses.dataclass class Frame : frame_id: int img_shape: torch.Tensor img_true_shape: torch.Tensor img: torch.Tensor uimg: torch.Tensor T_WC: lietorch.Sim3 = lietorch.Sim3.Identity(1 ) X_canon: Optional [torch.Tensor] = None C: Optional [torch.Tensor] = None feat: Optional [torch.Tensor] = None pos: Optional [torch.Tensor] = None N: int = 0 N_updates: int = 0 K: Optional [torch.Tensor] = None def update_pointmap (self, X: torch.Tensor, C: torch.Tensor ): filtering_mode = config["tracking" ]["filtering_mode" ] if self.N == 0 : self.X_canon = X.clone() self.C = C.clone() self.N = 1 self.N_updates = 1 if filtering_mode == "best_score" : self.score = self.get_score(C) return if filtering_mode == "first" : if self.N_updates == 1 : self.X_canon = X.clone() self.C = C.clone() self.N = 1 elif filtering_mode == "recent" : ... ... class SharedKeyframes : def __init__ (self, manager, h, w, buffer=512 , dtype=torch.float32, device="cuda" ): self.lock = manager.RLock() self.n_size = manager.Value("i" , 0 ) self.h, self.w = h, w self.buffer = buffer self.dtype = dtype self.device = device self.feat_dim = 1024 self.num_patches = h * w // (16 * 16 ) self.dataset_idx = torch.zeros(buffer, device=device, dtype=torch.int ).share_memory_() self.img = torch.zeros(buffer, 3 , h, w, device=device, dtype=dtype).share_memory_() self.uimg = torch.zeros(buffer, h, w, 3 , device="cpu" , dtype=dtype).share_memory_() self.img_shape = torch.zeros(buffer, 1 , 2 , device=device, dtype=torch.int ).share_memory_() self.img_true_shape = torch.zeros(buffer, 1 , 2 , device=device, dtype=torch.int ).share_memory_() self.T_WC = torch.zeros(buffer, 1 , lietorch.Sim3.embedded_dim, device=device, dtype=dtype).share_memory_() self.X = torch.zeros(buffer, h * w, 3 , device=device, dtype=dtype).share_memory_() self.C = torch.zeros(buffer, h * w, 1 , device=device, dtype=dtype).share_memory_() self.N = torch.zeros(buffer, device=device, dtype=torch.int ).share_memory_() self.N_updates = torch.zeros(buffer, device=device, dtype=torch.int ).share_memory_() self.feat = torch.zeros(buffer, 1 , self.num_patches, self.feat_dim, device=device, dtype=dtype).share_memory_() self.pos = torch.zeros(buffer, 1 , self.num_patches, 2 , device=device, dtype=torch.long).share_memory_() self.is_dirty = torch.zeros(buffer, 1 , device=device, dtype=torch.bool ).share_memory_() self.K = torch.zeros(3 , 3 , device=device, dtype=dtype).share_memory_() def __getitem__ (self, idx ) -> Frame: ... def __setitem__ (self, idx, value: Frame ) -> None : ...
另外,MAST3R-SLAM会在SharedStates里存储当前的SLAM系统的状态、以及当前普通帧的各种数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class SharedStates : def __init__ (self, manager, h, w, dtype=torch.float32, device="cuda" ): self.h, self.w = h, w self.dtype = dtype self.device = device self.lock = manager.RLock() self.paused = manager.Value("i" , 0 ) self.mode = manager.Value("i" , Mode.INIT) self.reloc_sem = manager.Value("i" , 0 ) self.global_optimizer_tasks = manager.list () self.edges_ii = manager.list () self.edges_jj = manager.list () self.feat_dim = 1024 self.num_patches = h * w // (16 * 16 ) self.dataset_idx = torch.zeros(1 , device=device, dtype=torch.int ).share_memory_() self.img = torch.zeros(3 , h, w, device=device, dtype=dtype).share_memory_() self.uimg = torch.zeros(h, w, 3 , device="cpu" , dtype=dtype).share_memory_() self.img_shape = torch.zeros(1 , 2 , device=device, dtype=torch.int ).share_memory_() self.img_true_shape = torch.zeros(1 , 2 , device=device, dtype=torch.int ).share_memory_() self.T_WC = lietorch.Sim3.Identity(1 , device=device, dtype=dtype).data.share_memory_() self.X = torch.zeros(h * w, 3 , device=device, dtype=dtype).share_memory_() self.C = torch.zeros(h * w, 1 , device=device, dtype=dtype).share_memory_() self.feat = torch.zeros(1 , self.num_patches, self.feat_dim, device=device, dtype=dtype).share_memory_() self.pos = torch.zeros(1 , self.num_patches, 2 , device=device, dtype=torch.long).share_memory_()
MAST3R提取特征与匹配
这里先来重新回忆一下MAST3R的结构,有一个encoder来获取图像编码patch的feat以及pos、,然后用decoder来将两个图像的feat解码成第一帧坐标系中的点图(X)、点图置信度(Conf)、编码特征(Desc)以及编码特征置信度(Desc_conf)。
相当于MAST3R只提供了对两张图像进行重建的API,但MAST3R-SLAM需要匹配,所以它有几种“利用API”的方法。
在系统初始化的时候,会利用mast3r_inference_mono将输入图像自身进行重建,并将重建后的点图和特征返回,随后只要对特征进行匹配,就能计算出两帧之间的相对位姿,从而能基于此来构建一个视觉历程计了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @torch.inference_mode def mast3r_inference_mono (model, frame ): if frame.feat is None : frame.feat, frame.pos, _ = model._encode_image(frame.img, frame.img_true_shape) feat = frame.feat pos = frame.pos shape = frame.img_true_shape res11, res21 = decoder(model, feat, feat, pos, pos, shape, shape) res = [res11, res21] X, C, D, Q = zip ( *[(r["pts3d" ][0 ], r["conf" ][0 ], r["desc" ][0 ], r["desc_conf" ][0 ]) for r in res] ) X, C, D, Q = torch.stack(X), torch.stack(C), torch.stack(D), torch.stack(Q) X, C, D, Q = downsample(X, C, D, Q) Xii, Xji = einops.rearrange(X, "b h w c -> b (h w) c" ) Cii, Cji = einops.rearrange(C, "b h w -> b (h w) 1" ) return Xii, Cii
在tracking过程中,会使用两种方式来获取特征后进行匹配,一种是asymmetric,用于正常的跟踪过程中,计算普通帧在当前关键帧下的点图和特征。另一种是symmetric,用于重定位,此时不确定当前普通帧最近的关键帧是哪一个,为了保证匹配的稳定性,沿用了之前MAST3R的匹配流程,需要同时计算普通帧在关键帧的点图和特征、关键帧在普通帧的点图和特征。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 @torch.inference_mode def mast3r_asymmetric_inference (model, frame_i, frame_j ): ... feat1, feat2 = frame_i.feat, frame_j.feat pos1, pos2 = frame_i.pos, frame_j.pos shape1, shape2 = frame_i.img_true_shape, frame_j.img_true_shape res11, res21 = decoder(model, feat1, feat2, pos1, pos2, shape1, shape2) res = [res11, res21] X, C, D, Q = zip ( *[(r["pts3d" ][0 ], r["conf" ][0 ], r["desc" ][0 ], r["desc_conf" ][0 ]) for r in res] ) X, C, D, Q = torch.stack(X), torch.stack(C), torch.stack(D), torch.stack(Q) X, C, D, Q = downsample(X, C, D, Q) return X, C, D, Q @torch.inference_mode def mast3r_symmetric_inference (model, frame_i, frame_j ): ... feat1, feat2 = frame_i.feat, frame_j.feat pos1, pos2 = frame_i.pos, frame_j.pos shape1, shape2 = frame_i.img_true_shape, frame_j.img_true_shape res11, res21 = decoder(model, feat1, feat2, pos1, pos2, shape1, shape2) res22, res12 = decoder(model, feat2, feat1, pos2, pos1, shape2, shape1) res = [res11, res21, res22, res12] X, C, D, Q = zip ( *[(r["pts3d" ][0 ], r["conf" ][0 ], r["desc" ][0 ], r["desc_conf" ][0 ]) for r in res] ) X, C, D, Q = torch.stack(X), torch.stack(C), torch.stack(D), torch.stack(Q) X, C, D, Q = downsample(X, C, D, Q) return X, C, D, Q
可能这里会稍微有一点绕,因为API比较多,包含了batch和inference以及带有matching封装的好几种情况,但只要关注mast3r_match_asymmetric和mast3r_match_symmetric这两个就可以了,他们包含了特征提取与匹配着两个步骤。其中mast3r_match_asymmetric用于tracking过程中,只计算每个普通帧在最近关键帧下的匹配(即单向匹配,固定在关键帧下);而mast3r_match_symmetric用于后端优化中,需要计算两个关键帧之间的双向匹配(也就是需要计算两次)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 def mast3r_match_asymmetric (model, frame_i, frame_j, idx_i2j_init=None ): X, C, D, Q = mast3r_asymmetric_inference(model, frame_i, frame_j) ... idx_i2j, valid_match_j = matching.match ( Xii, Xji, Dii, Dji, idx_1_to_2_init=idx_i2j_init ) ... return idx_i2j, valid_match_j, Xii, Cii, Qii, Xji, Cji, Qji def mast3r_match_symmetric (model, feat_i, pos_i, feat_j, pos_j, shape_i, shape_j ): X, C, D, Q = mast3r_decode_symmetric_batch( model, feat_i, pos_i, feat_j, pos_j, shape_i, shape_j ) ... X11 = torch.cat((Xii, Xjj), dim=0 ) X21 = torch.cat((Xji, Xij), dim=0 ) D11 = torch.cat((Dii, Djj), dim=0 ) D21 = torch.cat((Dji, Dij), dim=0 ) idx_1_to_2, valid_match_2 = matching.match (X11, X21, D11, D21) ... return idx_i2j, idx_j2i, valid_match_j, valid_match_i, Qii.view(b, -1 , 1 ), Qjj.view(b, -1 , 1 ), Qji.view(b, -1 , 1 ), Qij.view(b, -1 , 1 )
最后来看一下match这个函数,匹配过程的核心逻辑部分在CUDA内核里实现。当给定两帧的点图(光心出发的光线遇到的第一个相交的空间点)时,可以把每个3D点归一化为单位向量,得到“射线方向图”(ray image)。匹配通过最小化射线方向误差来建立对应,针对第二帧的每个射线,在第一帧的射线场上以给定初值为中心做局部的亚像素优化,也就是找到一个像素位置 (u,v),使该位置的视线方向与该3D点的方向误差最小。注意MAST3R中的点图已经处于同一坐标系下,不然只比较方向是没有意义的。除此之外还会基于三维欧氏距离做额外过滤,若基于夹角的粗匹配对应处的3D点距离太大,则判定为不匹配。
之所以采用这种基于射线方向的方法,一是便于在不知道相机内参或无法直接投影的场景下使用,二是在帧间运动较小时可以用前一帧的结果作为良好初值,从而保证匹配可靠性。相比之下,像KD-tree在并行化上困难,mast3r里的fast nn在实际复杂度和并行效率上也有缺陷。
另外,第一步粗匹配是通过射线夹角和欧式距离来完成的,第二步精匹配是在第一步匹配的邻域内,使用MAST3R输出的特征描述子做点积来找一个最佳匹配。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 def prep_for_iter_proj (X11, X21, idx_1_to_2_init ): ... rays_img = F.normalize(X11, dim=-1 ) rays_img = rays_img.permute(0 , 3 , 1 , 2 ) gx_img, gy_img = img_utils.img_gradient(rays_img) rays_with_grad_img = torch.cat((rays_img, gx_img, gy_img), dim=1 ) rays_with_grad_img = rays_with_grad_img.permute( 0 , 2 , 3 , 1 ).contiguous() X21_vec = X21.view(b, -1 , 3 ) pts3d_norm = F.normalize(X21_vec, dim=-1 ) ... return rays_with_grad_img, pts3d_norm, p_init def match_iterative_proj (X11, X21, D11, D21, idx_1_to_2_init=None ): ... rays_with_grad_img, pts3d_norm, p_init = prep_for_iter_proj( X11, X21, idx_1_to_2_init ) p1, valid_proj2 = mast3r_slam_backends.iter_proj( rays_with_grad_img, pts3d_norm, p_init, cfg["max_iter" ], cfg["lambda_init" ], cfg["convergence_thresh" ], ) batch_inds = torch.arange(b, device=device)[:, None ].repeat(1 , h * w) dists2 = torch.linalg.norm( X11[batch_inds, p1[..., 1 ], p1[..., 0 ], :].reshape(b, h, w, 3 ) - X21, dim=-1 ) valid_dists2 = (dists2 < cfg["dist_thresh" ]).view(b, -1 ) valid_proj2 = valid_proj2 & valid_dists2 if cfg["radius" ] > 0 : (p1,) = mast3r_slam_backends.refine_matches( D11.half(), D21.view(b, h * w, -1 ).half(), p1, cfg["radius" ], cfg["dilation_max" ], ) idx_1_to_2 = pixel_to_lin(p1, w) return idx_1_to_2, valid_proj2.unsqueeze(-1 )
系统入口与Tracking
然后我们来看一下整个系统的流程,整个系统有两个线程,一个主线程负责初始化系统和跟踪每一帧,而优化线程负责在添加关键帧后进行优化以及重定位。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 if __name__ == "__main__" : ... manager = mp.Manager() main2viz = new_queue(manager, args.no_viz) viz2main = new_queue(manager, args.no_viz) ... keyframes = SharedKeyframes(manager, h, w) states = SharedStates(manager, h, w) ... tracker = FrameTracker(model, keyframes, device) last_msg = WindowMsg() backend = mp.Process(target=run_backend, args=(config, model, states, keyframes, K)) backend.start() while True : mode = states.get_mode() frame = create_frame(i, img, T_WC, img_size=dataset.img_size, device=device) if mode == Mode.INIT: X_init, C_init = mast3r_inference_mono(model, frame) ... if mode == Mode.TRACKING: add_new_kf, match_info, try_reloc = tracker.track(frame) if try_reloc: states.set_mode(Mode.RELOC) states.set_frame(frame) elif mode == Mode.RELOC: X, C = mast3r_inference_mono(model, frame) ... if add_new_kf: keyframes.append(frame) states.queue_global_optimization(len (keyframes) - 1 ) ...
而tracking流程也不复杂,把每一帧和最近的关键帧用MAST3R计算点图并得到匹配点,然后用优化的方法来求解普通帧相对于关键帧的位姿,这样就实现了跟踪流程。在优化时,当没有给定相机内参时比较简单,误差为变换前后的射线场之间的夹角(不优化点图的欧式距离是因为远处的估计结果不准确,会拉高平均误差,而夹角本身相当于一种额外的先验加权);在给定内参时情况比较复杂,会同时优化重投影误差和对数深度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 class FrameTracker : def track (self, frame: Frame ): ... idx_f2k, valid_match_k, Xff, Cff, Qff, Xkf, Ckf, Qkf = mast3r_match_asymmetric( self.model, frame, keyframe, idx_i2j_init=self.idx_f2k ) ... try : if not use_calib: T_WCf, T_CkCf = self.opt_pose_ray_dist_sim3(Xf, Xk, T_WCf, T_WCk, Qk, valid_opt) else : T_WCf, T_CkCf = self.opt_pose_calib_sim3(Xf,Xk,T_WCf,T_WCk,Qk,valid_opt,meas_k,valid_meas_k,K,img_size) except Exception as e: print (f"Cholesky failed {frame.frame_id} " ) return False , [], True ... n_valid = valid_kf.sum () match_frac_k = n_valid / valid_kf.numel() unique_frac_f = ( torch.unique(idx_f2k[valid_match_k[:, 0 ]]).shape[0 ] / valid_kf.numel() ) new_kf = min (match_frac_k, unique_frac_f) < self.cfg["match_frac_thresh" ] ... def opt_pose_ray_dist_sim3 (self, Xf, Xk, T_WCf, T_WCk, Qk, valid ): ... T_CkCf = T_WCk.inv() * T_WCf rd_k = point_to_ray_dist(Xk, jacobian=False ) old_cost = float ("inf" ) for step in range (self.cfg["max_iters" ]): Xf_Ck, dXf_Ck_dT_CkCf = act_Sim3(T_CkCf, Xf, jacobian=True ) rd_f_Ck, drd_f_Ck_dXf_Ck = point_to_ray_dist(Xf_Ck, jacobian=True ) r = rd_k - rd_f_Ck ... ... def opt_pose_calib_sim3 ( self, Xf, Xk, T_WCf, T_WCk, Qk, valid, meas_k, valid_meas_k, K, img_size ): ... T_CkCf = T_WCk.inv() * T_WCf old_cost = float ("inf" ) for step in range (self.cfg["max_iters" ]): Xf_Ck, dXf_Ck_dT_CkCf = act_Sim3(T_CkCf, Xf, jacobian=True ) pzf_Ck, dpzf_Ck_dXf_Ck, valid_proj = project_calib( Xf_Ck, K, img_size, jacobian=True , border=self.cfg["pixel_border" ], z_eps=self.cfg["depth_eps" ], ) valid2 = valid_proj & valid_meas_k sqrt_info2 = valid2 * sqrt_info r = meas_k - pzf_Ck ... ... def project_calib (P, K, img_size, jacobian=False , border=0 , z_eps=0.0 ): ... logz = torch.log(z) invalid_z = torch.logical_not(valid_z) logz[invalid_z] = 0.0 pz = torch.cat((p, logz), dim=-1 ) ...
Tracking过程中还会根据匹配点数目来判断是否需要添加关键帧以及是否跟丢,总体来说还是比较简单的。
重定位、回环检测与Optimization
MAST3R中的重定位和优化部分高度耦合在一起,一般情况下都位于一个单独的进程中,如果在tracking过程中出现跟丢情况,那么优化线程会检测这个flag然后进入重定位流程,否则就继续进行全局优化。全局优化的代码也同样是在CUDA中实现的,跟Tracking中求解位姿差不多,有内参时用一个类似重投影误差来优化,没有内参时用一个ray的夹角来作为目标函数。在执行全局优化时,每个CUDA线程处理的是一条边(即一对匹配点多的关键帧),与之对比,在Tracking中的每个CUDA线程处理的是每一条ray。
无论是在重定位还是回环检测,MAST3R-SLAM都高度依赖Retrieval Database,大致原理是用把每张图像的feat经过白化等操作后后选出top-k的局部特征构建的相似度查询数据库。(当然这部分我就大概看了一下,不是特别感兴趣)。先来说回环检测,MAST3R-SLAM并没有像ORB-SLAM那样构造一个非常复杂的检测器,而是跟全局优化耦合在一起,每次为一个关键帧构建图优化时,会将 1)该关键帧前几个相邻的关键帧 2)通过Retrieval Database查询出来与当前关键帧相似的一系列关键帧 一起作为候选回环关键帧,然后调用add_factors函数为图优化添加新的边,这个函数会使用mast3r_match_symmetric来对候选回环关键帧进行匹配,移除掉那些匹配数目不够的候选回环关键帧,然后将这些边全部新增到图优化中进行全局优化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 def run_backend (cfg, model, states, keyframes, K ): ... while mode is not Mode.TERMINATED: ... if mode == Mode.RELOC: frame = states.get_frame() success = relocalization(frame, keyframes, factor_graph, retrieval_database) if success: states.set_mode(Mode.TRACKING) states.dequeue_reloc() continue with states.lock: if len (states.global_optimizer_tasks) > 0 : idx = states.global_optimizer_tasks[0 ] kf_idx = [] n_consec = 1 for j in range (min (n_consec, idx)): kf_idx.append(idx - 1 - j) frame = keyframes[idx] retrieval_inds = retrieval_database.update(frame,add_after_query=True ,k=config["retrieval" ]["k" ],min_thresh=config["retrieval" ]["min_thresh" ],) kf_idx += retrieval_inds ... if kf_idx: factor_graph.add_factors( kf_idx, frame_idx, config["local_opt" ]["min_match_frac" ] ) if config["use_calib" ]: factor_graph.solve_GN_calib() else : factor_graph.solve_GN_rays() ...
而对于重定位而言,基本逻辑与回环检测类似,只不过重定位时,会将当前普通帧临时升级为关键帧(如果重定位成功,就永久升级为关键帧,否则就会被踢掉),然后利用Retrieval Database查询所有相似度高的帧,并尝试构建图优化,这里并不像回环检测一样,重定位有一个strict选项,如果这个选项为真,那么要求所有重定位候选帧都必须能够和当前帧有较多的匹配才认为是重定位成功。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 def relocalization (frame, keyframes, factor_graph, retrieval_database ): with keyframes.lock: kf_idx = [] retrieval_inds = retrieval_database.update( frame, add_after_query=False , k=config["retrieval" ]["k" ], min_thresh=config["retrieval" ]["min_thresh" ], ) ... if kf_idx: ... if factor_graph.add_factors(frame_idx,kf_idx,config["reloc" ]["min_match_frac" ],is_reloc=config["reloc" ]["strict" ]): retrieval_database.update(frame,add_after_query=True ,k=config["retrieval" ]["k" ],min_thresh=config["retrieval" ]["min_thresh" ],) successful_loop_closure = True keyframes.T_WC[n_kf - 1 ] = keyframes.T_WC[kf_idx[0 ]].clone() else : keyframes.pop_last() print ("Failed to relocalize" ) if successful_loop_closure: if config["use_calib" ]: factor_graph.solve_GN_calib() else : factor_graph.solve_GN_rays() return successful_loop_closure
当然,这里面最关键的构建图优化的函数是add_factors,它就是利用MAST3R输出的特征来进行双向匹配(这个上面讲过了),再结合置信度和匹配数目筛选掉不太行的候选帧。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class FactorGraph : def add_factors (self, ii, jj, min_match_frac, is_reloc=False ): ... idx_i2j,idx_j2i,valid_match_j,valid_match_i,Qii,Qjj,Qji,Qij = mast3r_match_symmetric( self.model, feat_i, pos_i, feat_j, pos_j, shape_i, shape_j ) ... valid_Qj = Qj > self.cfg["Q_conf" ] valid_Qi = Qi > self.cfg["Q_conf" ] valid_j = valid_match_j & valid_Qj valid_i = valid_match_i & valid_Qi nj = valid_j.shape[1 ] * valid_j.shape[2 ] ni = valid_i.shape[1 ] * valid_i.shape[2 ] match_frac_j = valid_j.sum (dim=(1 , 2 )) / nj match_frac_i = valid_i.sum (dim=(1 , 2 )) / ni ii_tensor = torch.as_tensor(ii, device=self.device) jj_tensor = torch.as_tensor(jj, device=self.device) invalid_edges = torch.minimum(match_frac_j, match_frac_i) < min_match_frac consecutive_edges = ii_tensor == (jj_tensor - 1 ) invalid_edges = (~consecutive_edges) & invalid_edges if invalid_edges.any () and is_reloc: return False ...
最后来看下优化中的CUDA实现,同样的,这里也分为无标定和有标定,但是与tracking中的优化情况略有不同,在这里会将每条图优化的边映射到一个CUDA block上,然后block的每个CUDA thread来处理匹配点的jacobian以及残差等东西。在无标定参数的情况下,优化目标为两条ray之间的角度差+归一化后的ray的距离误差,不直接优化ray的距离的原因上面已经提到过了;而在有标定参数的情况下会优化重投影误差+对数深度误差,跟匹配的时候类似。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 #define GPU_1D_KERNEL_LOOP(k, n) \ for (size_t k = threadIdx.x; k < n; k += blockDim.x) __global__ void ray_align_kernel (...) ... GPU_1D_KERNEL_LOOP (k, num_points) { const float norm2_i = squared_norm3 (Xi); const float norm1_i = sqrtf (norm2_i); const float norm1_i_inv = 1.0 /norm1_i; float ri[3 ]; for (int i=0 ; i<3 ; i++) ri[i] = norm1_i_inv * Xi[i]; actSim3 (tij, qij, sij, Xj, Xj_Ci); const float norm2_j = squared_norm3 (Xj_Ci); const float norm1_j = sqrtf (norm2_j); const float norm1_j_inv = 1.0 /norm1_j; float rj_Ci[3 ]; for (int i=0 ; i<3 ; i++) rj_Ci[i] = norm1_j_inv * Xj_Ci[i]; err[0 ] = rj_Ci[0 ] - ri[0 ]; err[1 ] = rj_Ci[1 ] - ri[1 ]; err[2 ] = rj_Ci[2 ] - ri[2 ]; err[3 ] = norm1_j - norm1_i; const float q = Q[block_id][k][0 ]; const float ci = Cs[ix][ind_Xi][0 ]; const float cj = Cs[jx][k][0 ]; const bool valid = valid_match_ind & (q > Q_thresh) & (ci > C_thresh) & (cj > C_thresh); const float conf_weight = q; const float sqrt_w_ray = valid ? sigma_ray_inv * sqrtf (conf_weight) : 0 ; const float sqrt_w_dist = valid ? sigma_dist_inv * sqrtf (conf_weight) : 0 ; w[0 ] = huber (sqrt_w_ray * err[0 ]); w[1 ] = huber (sqrt_w_ray * err[1 ]); w[2 ] = huber (sqrt_w_ray * err[2 ]); w[3 ] = huber (sqrt_w_dist * err[3 ]); const float w_const_ray = sqrt_w_ray * sqrt_w_ray; const float w_const_dist = sqrt_w_dist * sqrt_w_dist; w[0 ] *= w_const_ray; w[1 ] *= w_const_ray; w[2 ] *= w_const_ray; w[3 ] *= w_const_dist; ... } } __global__ void calib_proj_kernel (...) ... GPU_1D_KERNEL_LOOP (k, num_points) { actSim3 (tij, qij, sij, Xj, Xj_Ci); const bool valid_z = ((Xj_Ci[2 ] > z_eps) && (Xi[2 ] > z_eps)); const float zj_inv = valid_z ? 1.0 /Xj_Ci[2 ] : 0.0 ; const float zj_log = valid_z ? logf (Xj_Ci[2 ]) : 0.0 ; const float zi_log = valid_z ? logf (Xi[2 ]) : 0.0 ; const float x_div_z = Xj_Ci[0 ] * zj_inv; const float y_div_z = Xj_Ci[1 ] * zj_inv; const float u = fx * x_div_z + cx; const float v = fy * y_div_z + cy; const bool valid_u = ((u > pixel_border) && (u < width - 1 - pixel_border)); const bool valid_v = ((v > pixel_border) && (v < height - 1 - pixel_border)); err[0 ] = u - u_target; err[1 ] = v - v_target; err[2 ] = zj_log - zi_log; } }
VGGT-SLAM
VGGT本身也是重建算法,并且它更加直接干脆,像MAST3R只能输出点图和特征图,仍然需要后续匹配和优化求解;而VGGT由于本身可以通过Camera Head和DPT来输出位姿和深度图、点图,因此基于VGGT构建的SLAM系统在代码层面就更加简洁了。并且由于VGGT的性质,它利用AA来一次处理一批图像,所以在构架SLAM的架构时也有所不同。
同样的,我们后面从VGGT-SLAM的数据结构开始,然后再详细介绍其系统架构与流程,当然,也要着重介绍一下为什么会使用SL(4)取代Sim(3)。
GraphMap与Submap
GraphMap和Submap两个类总体上还是比较简单的,GraphMap类只是提供了对于Submap管理的接口,主要用于获取子地图以及子地图中的帧以及优化后更新子地图位姿,就不贴代码了。而Submap存储了每个子地图与世界坐标系的转换,以及当前子地图中的所有帧和VGGT估计出来的点图、内参矩阵,当然还有用于回环检测的向量。
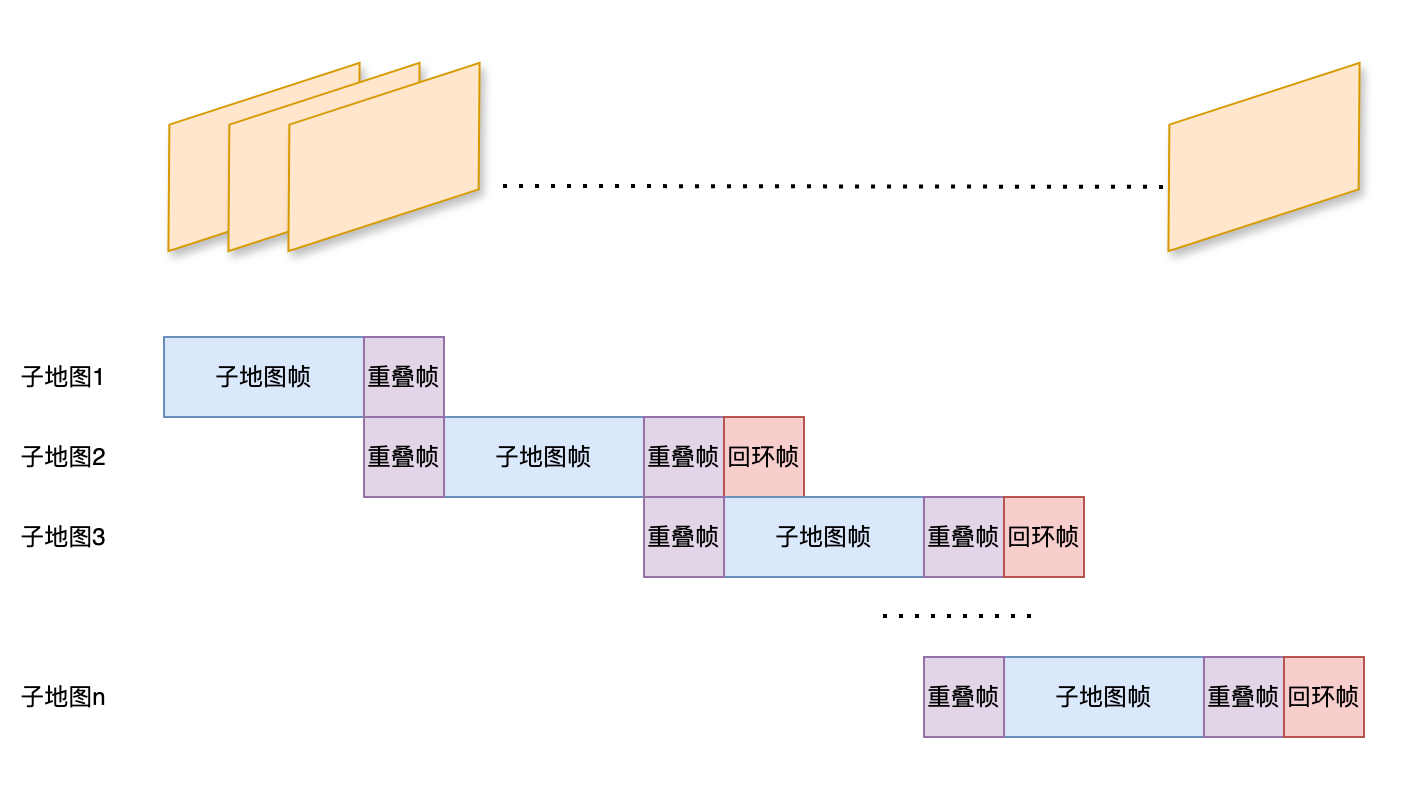
因为VGGT支持一次输入多张图像进行重建,所以在VGGT-SLAM里的最小重建单元就是子地图,每次累计一批图像然后,然后保证前后两个子地图之间有一部分重叠,并把回环帧也一块扔到VGGT里得到结果,再根据重叠帧来计算两个子地图的相对变换从而获取到每帧在空间中的位置,这部分的处理还是相对比较粗暴的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Submap : def __init__ (self, submap_id ): self.submap_id = submap_id self.frame_ids = None self.last_non_loop_frame_index = None self.frames = None self.H_world_map = None self.poses = None self.vggt_intrinscs = None self.pointclouds = None self.retrieval_vectors = None self.conf = None self.conf_masks = None self.conf_threshold = None self.colors = None
SL(4)与Sim(3)的子地图配准
射影重构定理
在详细讲这部分内容之前我们先来看一下射影重构定理。
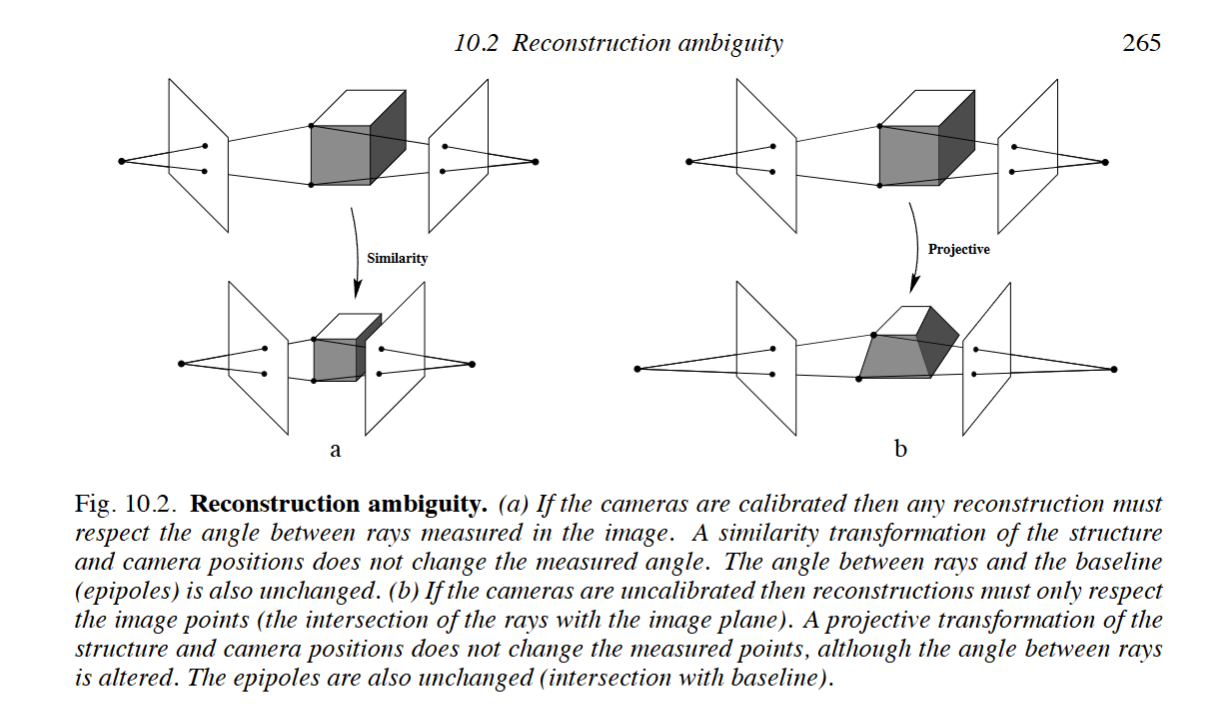
射影重构定理:如果两幅视图的一个点对应集唯一的确定了基本矩阵,则景物和摄像机可以仅由这些对应重构,而且由这些对应产生的任何两个重构都是射影等价的。
这句话非常的拗口,但它的意思其实很简单,就是说如果我们有两张图像,并且通过匹配点计算出了它们之间的基本矩阵(即不知道相机的内参),我们此时虽然可以恢复出场景的3D点和相机的位姿,但这个恢复出来的结果并不是唯一的,并且恢复出来的空间场景可能与真实场景非常不同,但它们在这两幅图像下的投影结果是一样的,并且这些不同的场景之间仅仅相差一个射影变换。换句话说,在不知道内参的情况下,我们只能通过两幅图像来恢复出一个射影等价的重建结果,如下图右侧所示;如果知道相机内参那么就是使用本质矩阵进行重建,那么重建结果与真实结果之间仅仅相差一个相似变换,如下图左侧所示。
为什么在相机内参未知的时候重建会出现射影多义性呢
这部分严格的数学证明可以参考《Multiple View Geometry in Computer Vision》第9章和第十章,写的非常清楚了。下面说一下个人的几个直观的角度的理解。
从直观意义角度来看。未标定相机丢失了内部尺度、正交、比例等度量信息,所以只能通过匹配只恢复了射影结构。射影变换又仅仅保留了“穿过相机中心的直线投影到图像”的对应关系,所以任何全局射影变形都没办法被计算出来。 从射影空间角度来看。标定相机的内参实质上就是标定绝对二次曲线的像(或者叫IAC,
特殊线性群SL(n)群与射影特殊线性群PSL(n)
SL(n)即特殊线性群,跟一般线性群GL(n)的区别在于其行列式恒为1(类似正交群O(n)和特殊正交群SO(n)的关系,特殊指的就是行列式为1)。而我们也同样知道,射影变换对应的矩阵也满足行列式为1,因此射影变换矩阵属于SL(n)群。而由于射影变换矩阵存在一个比例因子的歧义性,因此我们通常使用PSL(n)来表示射影变换群,PSL(n)即为SL(n)群除以其中心Z(SL(n)),也就是所有比例因子构成的群。
换句话说,SL(n)可以诱导一个PSL(n),但PSL(n)可以对应多个SL(n),这是因为射影变换作用在齐次坐标上,而齐次坐标本身就存在比例因子的歧义性。
举个例子,以在三维空间为例,射影变换可以表示为一个4x4的矩阵作用在齐次坐标上:
如果取射影变换
而如果取
VGGT-SLAM中的优化
SL(4)与PSL(4)的关系非常像单位四元数SU(2)和特殊正交群SO(3)的关系,即
同样的,VGGT-SLAM中也是基于SL(4)的李代数
作者是为GTSAM补充了一个SL(4)的模块,有兴趣的话可以参考作者给出的实现,这里就不再赘述了。
VGGT-SLAM重建与回环
VGGT-SLAM直接利用了VGGT的API,没有对图像做更多的处理了。还有一点,VGGT-SLAM在完成点图计算后也没有进行匹配的流程,因为重叠帧的位置是严格确定的,只需要取出对应位置的两帧用RANSAC晒掉坏点就可以了。
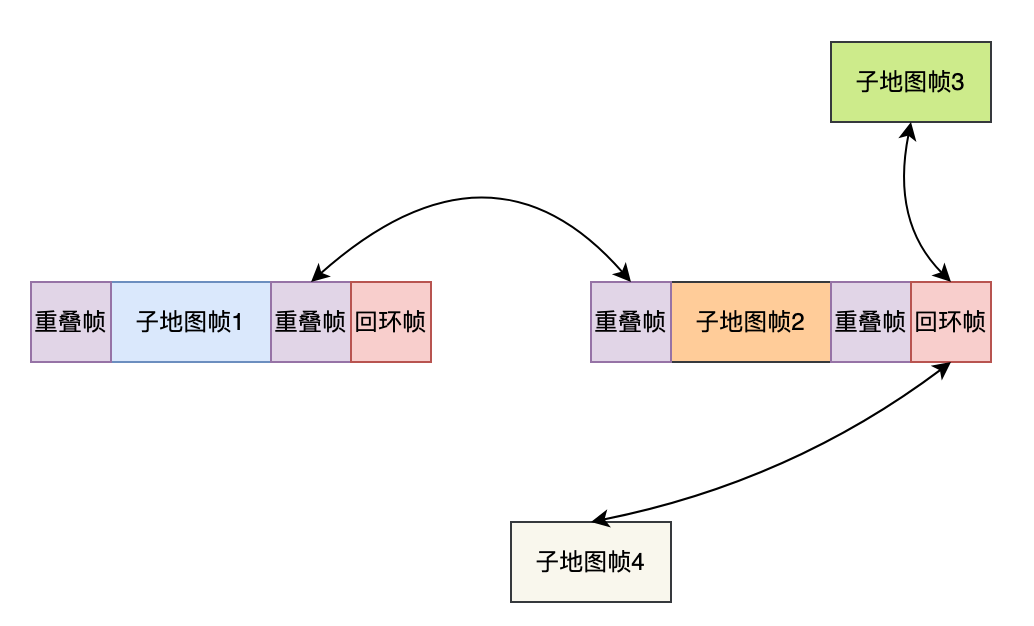
而VGGT-SLAM的整体流程可以说是非常简单:到达若干张图像后,将上一个子地图最后几张放在现在图像的前面;再使用SALAD模型全局搜索一下回环帧,把回环帧放在现在图像后面;这样组成一个图像集合直接送给VGGT来进行预测。VGGT会给出子地图中每一帧的相对位姿,因此只需要在重叠帧和回环帧上计算出当前子地图对于上一子地图和回环子地图之间的相对变换,就能构建一个Pose Graph来进行优化(没错,VGGT-SLAM只有Pose Graph级别的优化,完全不涉及任何地图点的BA)。这部分内容实在没什么好说的,直接看看代码吧。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def main (): ... for image_name in tqdm(image_names): ... if (len (image_names_subset) == args.submap_size + args.overlapping_window_sizeor image_name == image_names[-1 ]): predictions = solver.run_predictions(image_names_subset, model, args.max_loops) solver.add_points(predictions) solver.graph.optimize() solver.map .update_submap_homographies(solver.graph) image_names_subset = image_names_subset[-args.overlapping_window_size :]
主要的函数就上面列出的这几个,而这几个函数内部对比其他的SLAM系统也可以说是非常简单了。由于位姿估计是VGGT的API,而又不需要执行匹配操作,所以主要代码就集中在add_points()里。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 class Solver : def run_predictions (self, image_names, model, max_loops ): ... new_submap.set_all_retrieval_vectors(self.image_retrieval.get_all_submap_embeddings(new_submap)) detected_loops = self.image_retrieval.find_loop_closures(self.map , new_submap, max_loop_closures=max_loops) retrieved_frames = self.map .get_frames_from_loops(detected_loops) num_loop_frames = len (retrieved_frames) new_submap.set_last_non_loop_frame_index(images.shape[0 ] - 1 ) if num_loop_frames > 0 : image_tensor = torch.stack(retrieved_frames) images = torch.cat([images, image_tensor], dim=0 ) new_submap.add_all_frames(images) self.current_working_submap = new_submap with torch.no_grad(): with torch.cuda.amp.autocast(dtype=dtype): predictions = model(images) ... return predictions def add_points (self, pred_dict ): if self.use_point_map: world_points_map = pred_dict["world_points" ] conf = pred_dict["world_points_conf" ] world_points = world_points_map else : depth_map = pred_dict["depth" ] conf = pred_dict["depth_conf" ] world_points = unproject_depth_map_to_point_map(depth_map, extrinsics_cam, intrinsics_cam) cam_to_world = closed_form_inverse_se3(extrinsics_cam) points_in_first_cam = world_points[0 ,...] h, w = points_in_first_cam.shape[0 :2 ] new_pcd_num = self.current_working_submap.get_id() if self.first_edge: self.first_edge = False self.prior_pcd = world_points[-1 ,...].reshape(-1 , 3 ) self.prior_conf = conf[-1 ,...].reshape(-1 ) H_w_submap = np.eye(4 ) self.graph.add_homography(new_pcd_num, H_w_submap) self.graph.add_prior_factor(new_pcd_num, H_w_submap, self.graph.anchor_noise) else : prior_pcd_num = self.map .get_largest_key() prior_submap = self.map .get_submap(prior_pcd_num) current_pts = world_points[0 ,...].reshape(-1 , 3 ) good_mask = self.prior_conf > prior_submap.get_conf_threshold() * (conf[0 ,...,:].reshape(-1 ) > prior_submap.get_conf_threshold()) if self.use_sim3: R_temp = prior_submap.poses[prior_submap.get_last_non_loop_frame_index()][0 :3 ,0 :3 ] t_temp = prior_submap.poses[prior_submap.get_last_non_loop_frame_index()][0 :3 ,3 ] T_temp = np.eye(4 ) T_temp[0 :3 ,0 :3 ] = R_temp T_temp[0 :3 ,3 ] = t_temp T_temp = np.linalg.inv(T_temp) scale_factor = np.mean(np.linalg.norm((T_temp[0 :3 ,0 :3 ] @ self.prior_pcd[good_mask].T).T + T_temp[0 :3 ,3 ], axis=1 ) / np.linalg.norm(current_pts[good_mask], axis=1 )) H_relative = np.eye(4 ) H_relative[0 :3 ,0 :3 ] = R_temp H_relative[0 :3 ,3 ] = t_temp world_points *= scale_factor cam_to_world[:, 0 :3 , 3 ] *= scale_factor else : H_relative = ransac_projective(current_pts[good_mask], self.prior_pcd[good_mask]) H_w_submap = prior_submap.get_reference_homography() @ H_relative non_lc_frame = self.current_working_submap.get_last_non_loop_frame_index() pts_cam0_camn = world_points[non_lc_frame,...].reshape(-1 , 3 ) self.prior_pcd = pts_cam0_camn self.prior_conf = conf[non_lc_frame,...].reshape(-1 ) self.graph.add_homography(new_pcd_num, H_w_submap) self.graph.add_between_factor(prior_pcd_num, new_pcd_num, H_relative, self.graph.relative_noise) ... for index, loop in enumerate (detected_loops): loop_index = self.current_working_submap.get_last_non_loop_frame_index() + index + 1 if self.use_sim3: pose_world_detected = self.map .get_submap(loop.detected_submap_id).get_pose_subframe(loop.detected_submap_frame) pose_world_query = self.current_working_submap.get_pose_subframe(loop_index) pose_world_detected = gtsam.Pose3(pose_world_detected) pose_world_query = gtsam.Pose3(pose_world_query) H_relative_lc = pose_world_detected.between(pose_world_query).matrix() else : points_world_detected = self.map .get_submap(loop.detected_submap_id).get_frame_pointcloud(loop.detected_submap_frame).reshape(-1 , 3 ) points_world_query = self.current_working_submap.get_frame_pointcloud(loop_index).reshape(-1 , 3 ) H_relative_lc = ransac_projective(points_world_query, points_world_detected) self.graph.add_between_factor(loop.detected_submap_id, loop.query_submap_id, H_relative_lc, self.graph.relative_noise) self.graph.increment_loop_closure() self.map .add_submap(self.current_working_submap)
而接下来会执行一次优化,但是VGGT-SLAM的优化只有Pose Graph优化,只会根据重叠帧和回环帧的约束来建立优化,而不会像MAST3R-SLAM那样基于ray夹角或者重投影误差来优化地图点,感觉VGGT-SLAM这样做有些粗糙了,同时也太相信VGGT的重建结果了。而回环的求解也很简单,使用SALAD描述符作为图像的回环特征,用L2距离来进行回环检测,这部分代码就懒得贴了。具体Pose Graph就如下图所示。
总结
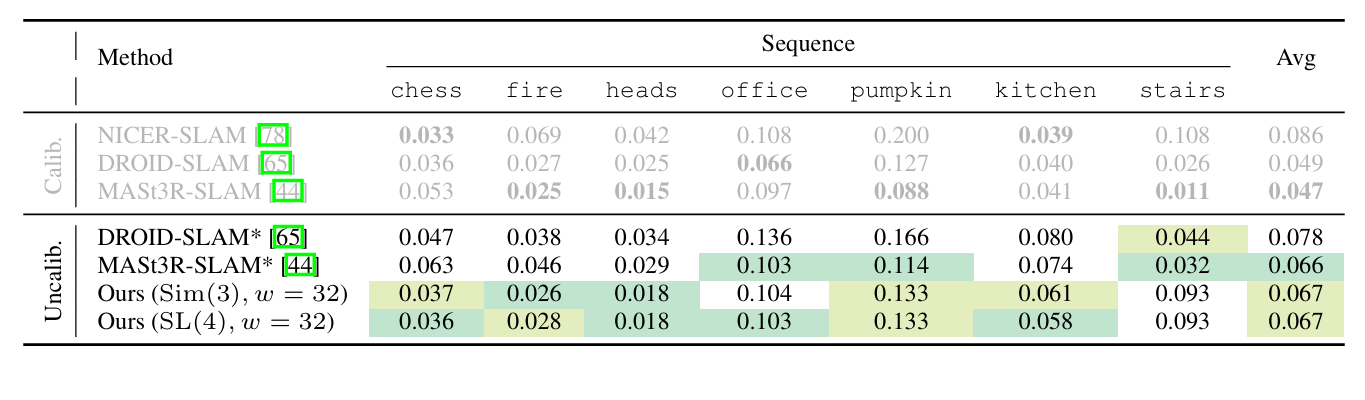
有一说一,VGGT-SLAM在工程上的处理实在是有些粗糙,让人读下去的欲望确实不是很大。另外,VGGT-SLAM提出SL(4)作为优化确实很有意思,但是从文中的指标来看,似乎并没有什么显著的提升...并且相机内参在SLAM中很容易获得,所以综合来看MAST3R-SLAM还是更胜一筹叭。
而且这个指标感觉也是有水分的,因为代码中求解Sim3是直接依赖Pose Graph优化,而求解SL(4)则是基于RANSAC求解初值+Pose Graph优化。另外,关于作者提到的用Sim3做子地图配准的错位问题,但我觉得这并不能完全归咎于Sim3,因为作者在代码里并没有利用VGGT估计的内参做重投影误差的全局BA,而是完全依赖VGGT自身的输出结果,但是单目相机本来就丢失了自由度,完全依赖单目重建整个场景本身就具有奇异性。作者提到在对于稠密空间点做BA可能会非常耗时,但其实MAST3R已经提供了一个BA的范式:认为一个小区域内的像素相对深度是准确的,然后算一下这个小区域的平均深度来作为anchor,优化的时候只优化anchor并保持相对深度不变从而反推出区域内像素所有深度。