CUDA全局内存、共享内存的合理使用
全局内存与合理使用
由于全局内存是GPU内存中容量最大、访问速度最慢的内存,因此对全局内存的关注是十分必要的,只有正确使用全局内存,才能写出高性能的CUDA程序。一般依次传输数据量是32字节。
对全局内存是存在L1、L2高速缓存的,因此访问全局内存首先会经过缓存,如果不命中则执行缺页中断,再从主存中取出。对全局内存的访问有合并和非合并两种方式。
全局内存的合并与非合并访问
合并访问是指一个线程束对全局内存的一次访问申请求所导致的最小数量的数据传输,否则称为非合并访问。
即如果一次请求的数据全部是线程束需要的就是合并访问,否则就是非合并访问。因此合并度可以看作是资源利用率,合并度越高则说明效率越高。
合并度不到100%的原因是因为内存对齐问题,内存对齐在CPU中是非常普遍的现象,malloc分配的内存全部都是内存对齐的,内存对齐也有利于访问速度的提升,此处不再赘诉。在GPU中,全局内存转移到L2缓存的内存是首地址为32字节的整数倍,因此内存首地址需要被对齐到32的整倍数时,即首地址满足addr & ~~(11111b) == 0(低5位位0)才能满足合并度为100%。
使用cudaMalloc()分配的内存地址至少为256的整倍数。
当读取与写入都是非合并的时候,最好合并写入,因为非合并的读取会被__lgd()优化。
也可以尝试使用共享内存将非合并转换成合并。
共享内存与合理使用
前面也提到过,共享内存就是可以被直接编程的缓存,读写速度十分的高,所以很有必要了解其使用。
对大数组求和
对一个大数组进行求和与两个大数组相加的编程思路是不一样的,后者只需要定义相同元素个线程然后两两相加即可。对于前者,可能C++语言会编写出如下的代码
1 |
|
但是上述代码没有办法直接转化成并行计算模式。如果数组大小刚好是2的N次幂时,可以将数组每次分成一半,后一半加到前一半上,直到只剩一个元素就是最终结果。下面给出并行计算的核函数。
1 |
|
但是如果想要在并行计算中使用这个方法,需要注意由于每个线程执行顺序是不确定的,因此需要保证当所有线程都完成当前轮迭代后再开启下一轮。
可以使用__syncthreads()函数来进行同步,当其不带任何参数时,会等待一个线程块内所有线程束完成后再继续执行。我们此处先简单考虑,假设线程块为128,先将d_x[n]这个大数组每128个元素求和,并保存在d_y[n/128]中,因此可以得到这样一个代码。
1 |
|
很明显,上述代码需要频繁的访问d_y,且由于d_y位于全局内存中,这样IO速度会慢很多。同时d_y是多个线程合作的结果,所以也不能使用寄存器(既存不下也不能被其他线程访问),所以此处加速的方法是使用共享内存。
共享内存声明是使用修饰符__shared__即可,由于每个线程都能访问线程块的共享内存,因此将全局内存数据复制到共享内存中不需要写循环。下面给出代码。
1 |
|
但是这种共享内存的声明是硬编码的方式声明的,可扩展与可移植性不好,下面给出动态共享内存的声明方式。
首先,使用了动态共享内存的核函数必须传递三个参数xxx_kernel<<<gridSize,blockSize,sizof(T)*N>>>(...),其中第三个参数为声明的共享内存大小,且在核函数内部必须以extern __shared__ T array[];的方式进行声明。
不能声明成extern shared T *array;
因为指针与数组是不同的,所以这样会编译错误。
在设备上使用动态共享内存和静态共享内存是没有明显的性能差距的,所以最好使用动态共享内存。
共享内存的bank冲突
在共享内存中,连续的32-bits字被分配到连续的32个bank中,这就像电影院的座位一样:一列的座位就相当于一个bank,所以每行有32个座位,在每个座位上可以“坐”一个32-bits的数据(或者多个小于32-bits的数据,如4个char型的数据,2个short型的数据);而正常情况下,我们是按照先坐完一行再坐下一行的顺序来坐座位的,在shared memory中地址映射的方式也是这样的。下图中内存地址是按照箭头的方向依次映射的:
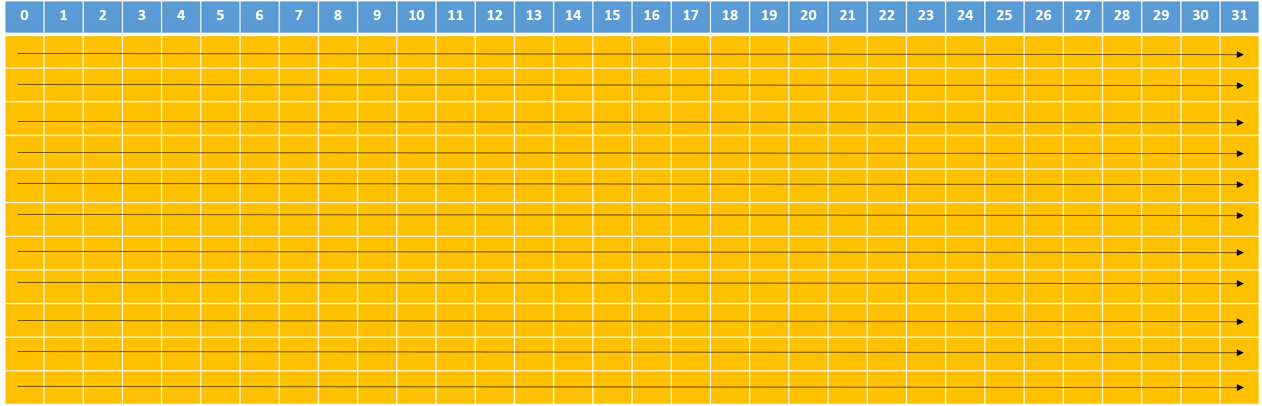
每个bank内的存储数据是共用一根总线的,所以当有两个及以上的线程需要访问一个bank内的数据时,需要两次总线操作;而所有线程访问不同bank内的数据时,所有的访问都能在一次总线操作,因此bank冲突会导致性能下降。
总结
- __syncthreads()函数可以用于线程块内线程同步。
- 静态共享内存在核函数内使用
__shared__修饰符进行修饰。 - 动态共享内存需要在核函数调用时传递第三个参数
xxx_kernel<<<gridSize,blockSize,sizof(T)*N>>>(...),并且在核函数内声明为extern __shared__ array[]; - 要尽可能避免bank冲突。