关于pnp问题的end2end训练方法
PnP-Net: A hybrid Perspective-n-Point Network
这次看两篇关于针对pnp问题融合深度学习的求解器的设计,其中深度学习的网络仅仅是看成一个映射,所以这个一种end2end的设计,而end2end的主要问题还是求解后续步骤中的梯度问题。
首先来看第一篇论文PnP-Net: A hybrid Perspective-n-Point Network,这篇论文设计了一种全连接的网络结构,用来求解p3p问题的位姿,而神经网络是用来给后续求解器提供初始点的。
概述
跳过introduction和problem formulation,直接来看他求解问题的思路。首先拿到2d-3d的匹配点对,然后送入到一个网络中计算出一个初始化值,用于LM算法的初始化,然后再用LM算法进行迭代,得到最终的位姿结果。
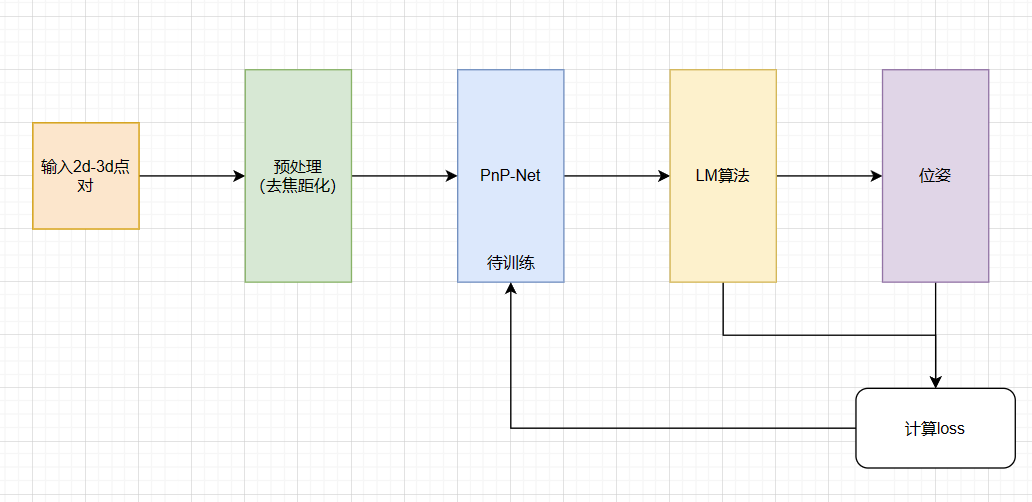
对于输入而言,由于是2D-3D的匹配点对,所以一个点对就有2+3=5个维度,而对于PnP问题共有n个点对,所以输入维度为5n,而输出的维度为6,即一个位姿的6个自由度(不过网络输出的维度时7维,这个后面再说,是由于网络表示位姿的方式差异导致的)
预处理
输入是一对对的2d-3d匹配点对,而文中会对3d的输入数据进行预处理,从而消除焦距的差异,具体如下所示。
对于3d点
其中
由于不同的相机焦距是不同的,所以为了保证网络具有良好的效果,所以要实现焦距归一化,具体而言,只需要对3d点进行如下变换即可
这样,分母中的
定义网络
网络的输入是5n维的向量,而输出是6维的向量,即一个位姿的6个自由度,而网络的结构如下所示,是很简单见的fc+relu结构
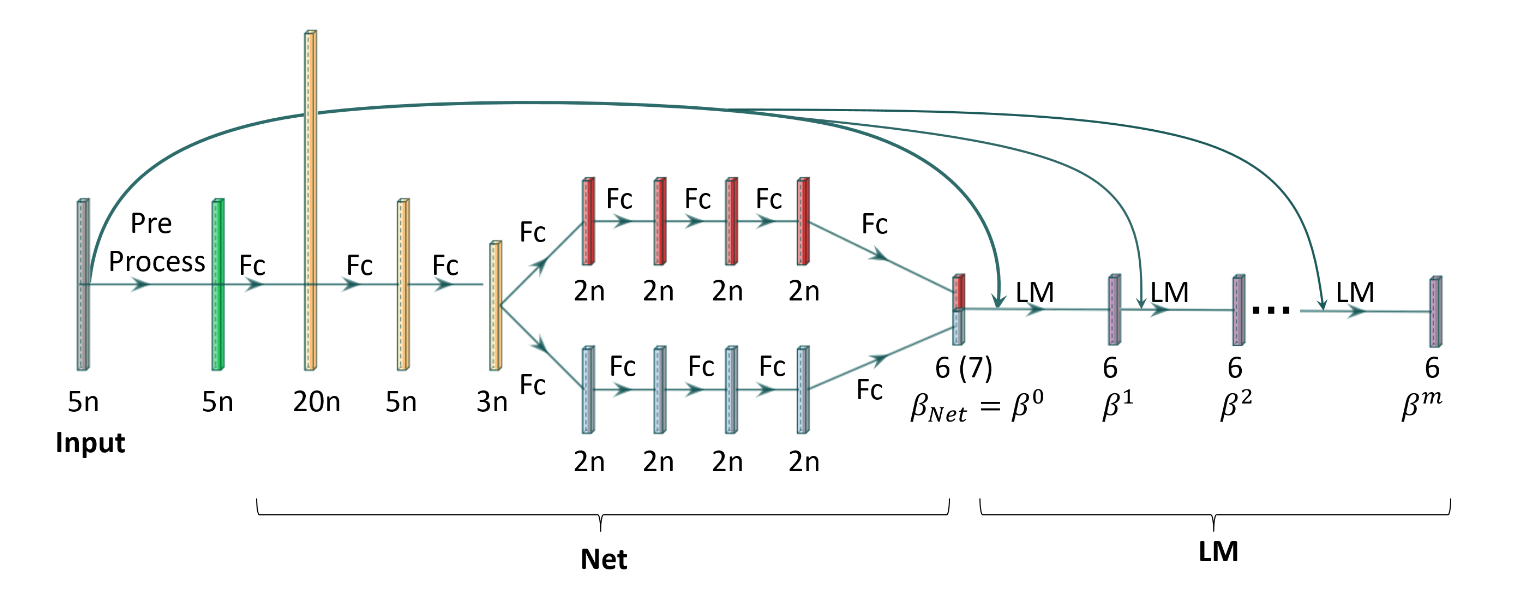
网络中间一分为二,上半部分表示位姿中的旋转,下半部分表示位姿中的平移。但是注意,网络的输出是7维的,这是因为使用了旋转轴(三个维度)+旋转量(一个维度)这样四个维度来对旋转进行非奇异的冗余表示导致的。
网络的输出会被当作后续LM算法的初始值从而完成进一步的计算工作。
LM算法
这里不再进一步介绍LM算法,它只是用于优化求解位姿的算法。
本文中并没有把LM算法当作一个layer看待,而是看作一个独立的模块,LM的输出和网络的输出分别是用于构建损失函数的一部分,因此没有去求解LM算法输出对于网络的梯度问题,这里处理的有些粗暴。
损失函数
损失函数决定了训练时的更新的梯度问题,本文的算法梯度有两个主要部分组成。
- 网络输出损失:由于网络会计算出一个
,可以直接用网络输出的位姿与真实位姿的差平方作为网络的输出损失 - LM优化损失:这个相当于全局的损失,LM算法使用网络输出作为起始值,经过迭代优化后得到的位姿与真实位姿的差平方作为LM优化损失
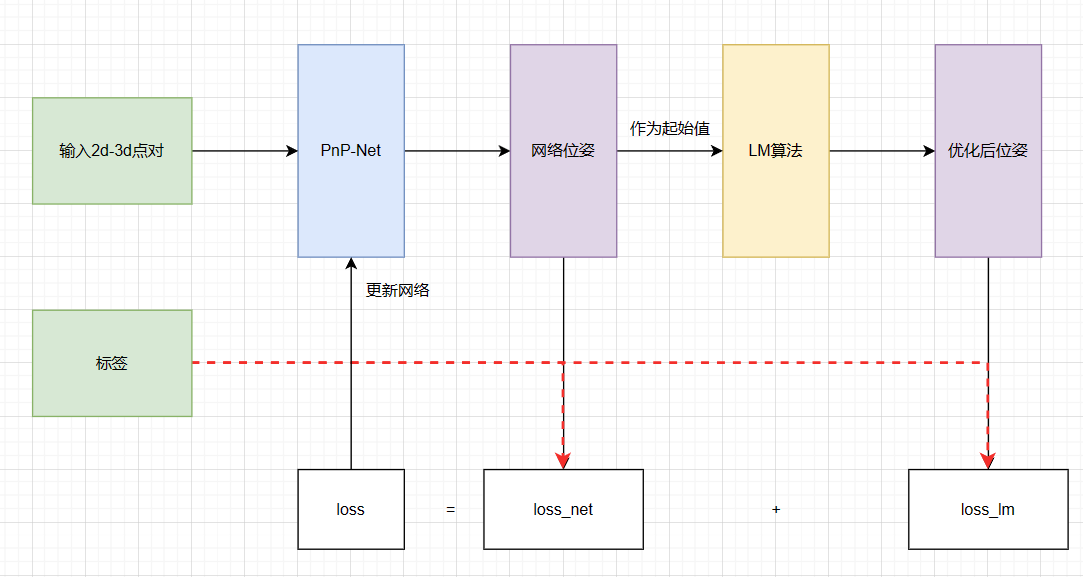
文中还提到,在算法刚运行时,仅仅以网络输出损失来进行优化,只有运行一段时间后,才加入LM优化损失。
总结
我个人觉得本文中的end2end训练策略还是有点太粗暴了,没有更进一步去考虑LM对于net的梯度,而且,文中说更详细的信息可以参考"supplementary code",但是无论怎么查都查不到...
还有就是,文中说LM中有
End-to-End Learnable Geometric Vision by Backpropagating PnP Optimization
第二篇文章是End-to-End Learnable Geometric Vision by Backpropagating PnP Optimization,这篇文章中对于求解器部分梯度的处理更加精细,并且也有比较完善的代码。
这篇文章设计了一种end2end的BPNP网络,可以用于求解位姿、相机标定等等,我这里主要关注一下位姿求解的问题。
同样是对于PnP问题,上一篇文章是输入为2d-3d点对,网络给后续求解器计算出一个初始种子;而这一篇文章则是输入为3d点对和平面图像,网络计算出与3d点相匹配的2d点对,并用于后续的计算,并且把后续的迭代优化看成是一个可导的layer,其参与到net部分的梯度计算。
隐函数求导
论文上来先提到了隐函数求导,为什么需要这个东西呢?因为在网络后需要使用一个优化器通过迭代的方法来完成位姿的计算,我们不妨把这个优化器记为
但是此时我们的
我们要求解梯度,其实就是求解
隐函数求导法则
对于矩阵函数
且
可以看到,通过上式,可以把形式未定的
构造f函数
当然,上一步仅仅是把求
由于不同求解器求解出来的收敛的解一定是一个极值点,那么一定有
由于求解出来的
而隐函数定理中要求
这样就构造出了满足隐函数定理的
进一步我们来看看
由于
记
因此有
以上,我们构造出了
通过这种方法,就把后续的优化看作是一个layer,从而可以完成梯度的计算与更新
位姿估计
有了上述的推导,其用在位姿估计上就很简单了,我们来看一下基于上述网络的算法。文中的算法是已知的环境

在每个epoch里,首先利用网络来估计出当前图像
而此时的损失是这个样子的
损失函数的第一项是描述估计的位姿与标签的最佳位姿之间的差距;而第二项则描述了当前位姿与"正确"的位姿之间的差距(因为x相当于是输入的2d点,优化后的位姿应该保证3d结构重投影后能够尽量满足观测到的数据)
而计算损失的时候,则直接利用之前的隐函数求导法则,构建出
总结
显然,这种通过隐函数求导的方式来求解出优化器中难以计算的梯度,从而把优化器直接转换成一个可导layer是十分巧妙的,然后作者也把它封装成了一个pytorch的layer,可以直接用于其他任务的训练。