不基于几何约束的sfm方法:DUSt3R和MASt3R
DUSt3R
传统一些sfm(比如COLMAP、GLOMAP)这种,都是将整个sfm任务划分为多个子任务:提取特征、匹配、三角化特征点等等等等。DUSt3R作者认为,在解决这些子任务时:
- 前一个子任务会把误差累进到后一个子任务中,比如匹配的误差就不可避免会给三角化带来影响
- 后一个子任务的信息很难前馈到前一个子任务中,比如相机估计出来的位姿能够用于重建,但重建后的结果却很难前馈到估计位姿过程中去
而DUSt3R则完全不划分任何子任务,输入两张图像就直接通过网络模型来端到端地计算3D点云。
PointMap与ConfidenceMap
先来看一下DUSt3R的输出格式,对于H*W*3的RGB图像而言,最终会输出一个H*W*3的PointMap和一个H*W的ConfidenceMap。其中ConfidenceMap非常好理解,就是每个像素对应的PointMap的置信度,一共有H*W个像素,所以ConfidenceMap的维度是H*W。
而PointMap则是每个RGB图像的像素点对应的三维空间坐标,因为每个空间点是三维坐标,一共有H*W个像素,所以PointMap的维度是H*W*3。
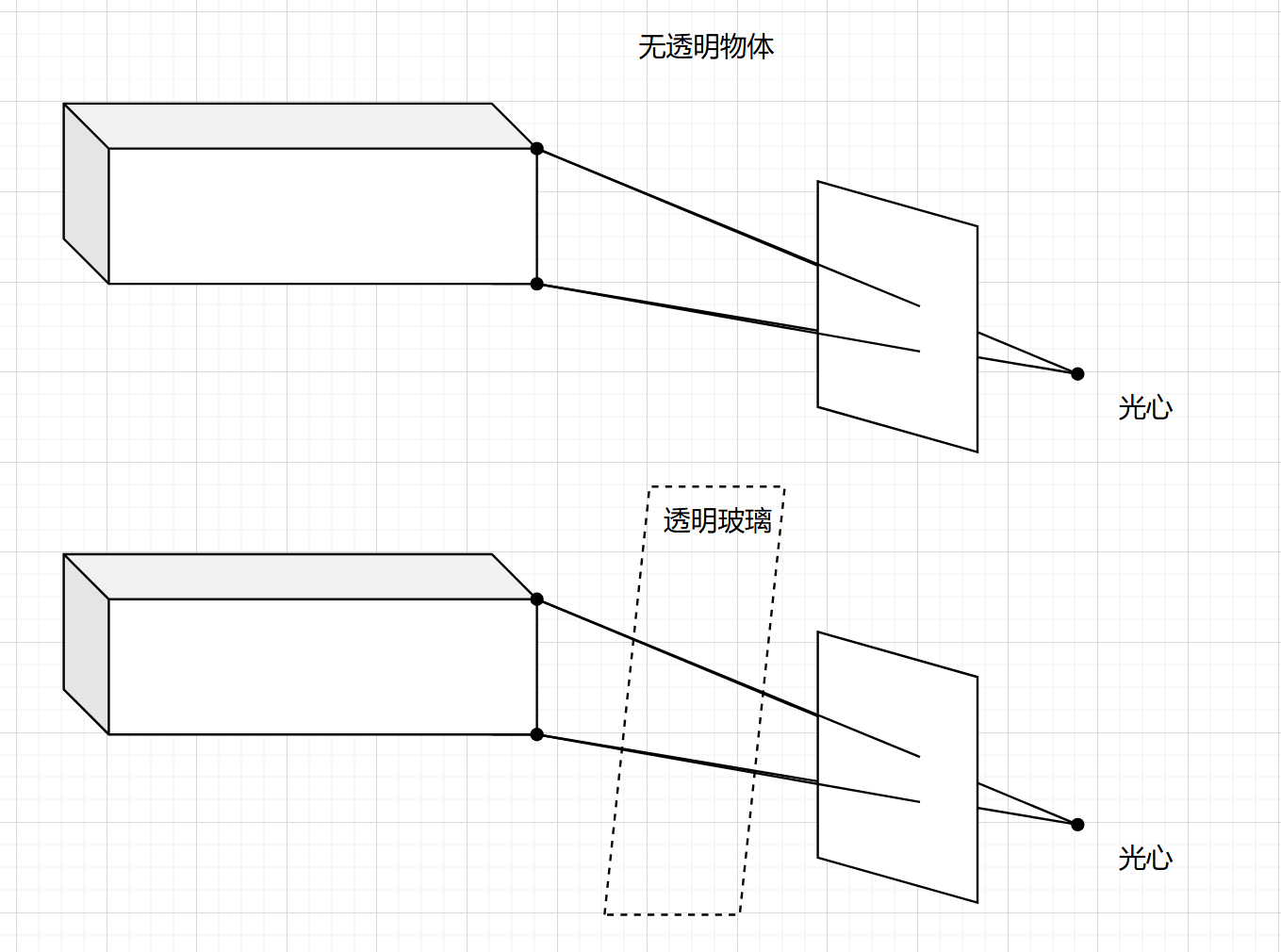
PointMap的物理含义是,从光心与对应像素的组成的射线,遇到的最近的空间结构在相机坐标系中的坐标。但需要注意,这实际上隐含了所有被相机观测的物体都是不透明物体这一假设。如下图,在存在透明/半透明结构时,这时最近的3D点应该是半透玻璃,但实际上因为被半透玻璃遮蔽的物体有更显著的特征,因为基于PointMap大概率无法很好的重建出这类结构。
网络结构
DUSt3R的网络结构比较简单,这里直接用原文的图了。
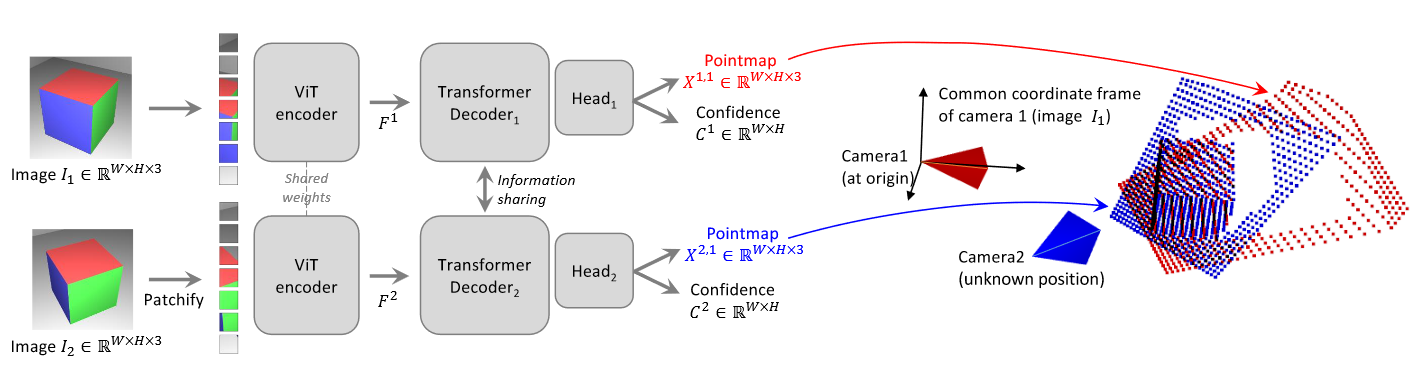
简单来说,输入的两张图像
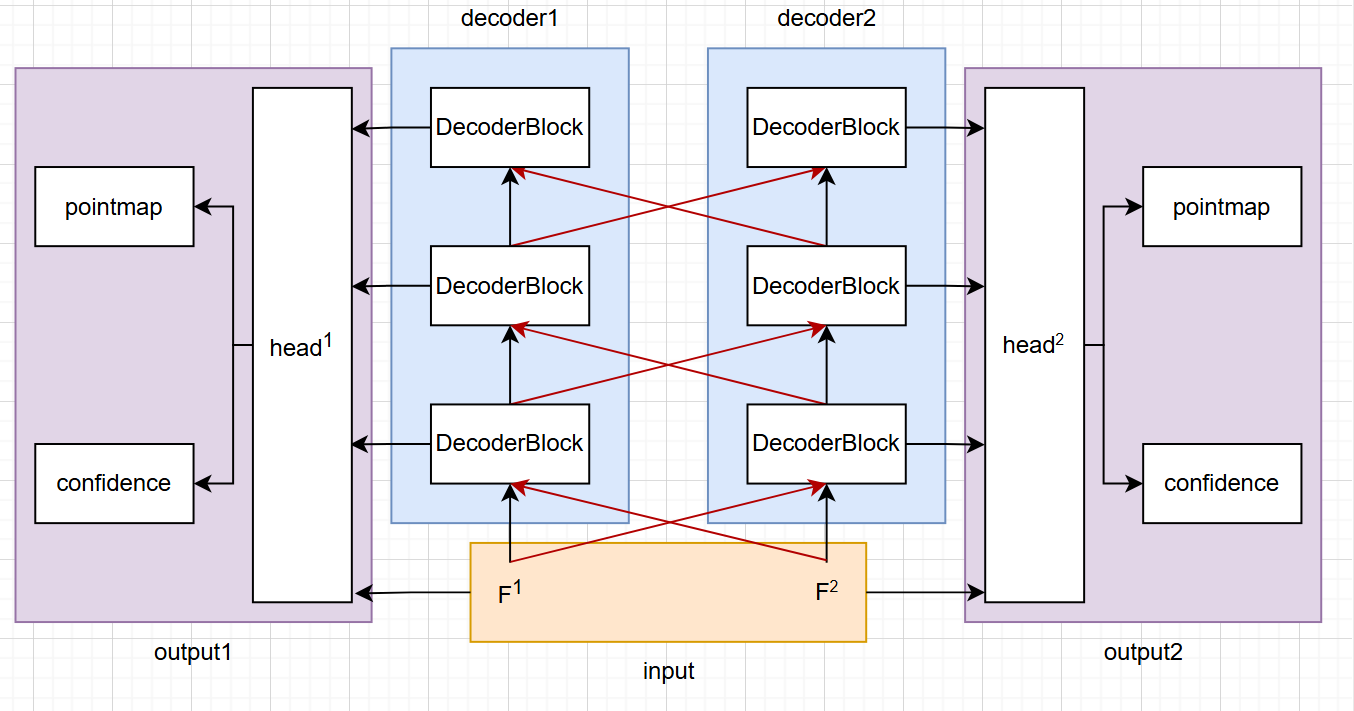
为了避免后续的配准,直接以第一张图像作为基准坐标系,网络输出的第二张图像的PointMap就直接已经位于基准坐标系了。
但是输出的PointMap是不带有尺度信息的,而且因为这个过程完全不带有任何几何约束,所以PointMap对应与每个像素的连线不一定会交于同一点(也就是光心)。
损失函数
损失函数由两部分组成,第一部分是3D点空间距离,第二部分是置信度。
先说3D点距离损失:假设第j张图像(只有两张图,所以j=1或2)的第i个像素在基准坐标系对应的真实空间点为
其中
其中
上述loss只衡量了PointMap的3D点与真实3D点之间的误差,但网络还会输出一个ConfidenceMap,还需要把置信度融合进loss里:
这个其实就是置信度和对应的3D点距离损失相乘,这样3D点预测比较好(对应
文章里提到采用了
1 | # head实际里输出conf的函数 |
多图校准
上述pipeline一次只能输入两张图,但是实际肯定不止这么点,作者是这样处理的:
- 为有重叠区域的图像两两构建匹配对(pair),检测重叠区域用特征点法也好,用encoder输出的隐式特征也好,总之就是把能看到同一区域的图像两两相连起来。
- 把上述每对pair送到pipeline里去检测,用平均置信度来踢掉不太行的pair
- 这样子不就得到了一堆点云了嘛,对于每对图像
,预测出成对的点云 以及它们的置信度图 - 但是这些点云都不在同一个基准坐标系里,然后每个点云的尺度还不一定一样,所以要用一个优化来弄到一个共同的坐标系里
这个优化其实就是为每对图像
为了避免所有缩放因子
实际测试
文章里列出了好多应用,因为相当于获取到了点云了嘛,所以基于点云匹配就能反推出图像的匹配点;优化也能解出相机内参;解pnp能得到位姿...
我这里也简单试了一下效果:

本质还是力大砖飞,引入超级多的先验来一步到位,多图重建这个优化感觉还可以更进一步。
MASt3R
MASt3R是对DUSt3R的改进,MASt3R其实分为了两篇文章,一篇是MASt3R matching,基于DUSt3R的网络主体结构,多了一些模块用于两帧之间的匹配;还有一篇是MASt3R sfm,这篇是基于MASt3R matching做的一个用于多图sfm。
因为MASt3R sfm是基于MASt3R matching的网络结构并用到了里面一些NN算法,所以我们先来看MASt3R matching。
MASt3R matching
matching的网络结构跟DUSt3R基本保持一致,蓝色的部分是新增的模块。比较明显的是新增了一个head用来提取local feature,然后是多了两个最邻近匹配模块用来构建匹配。
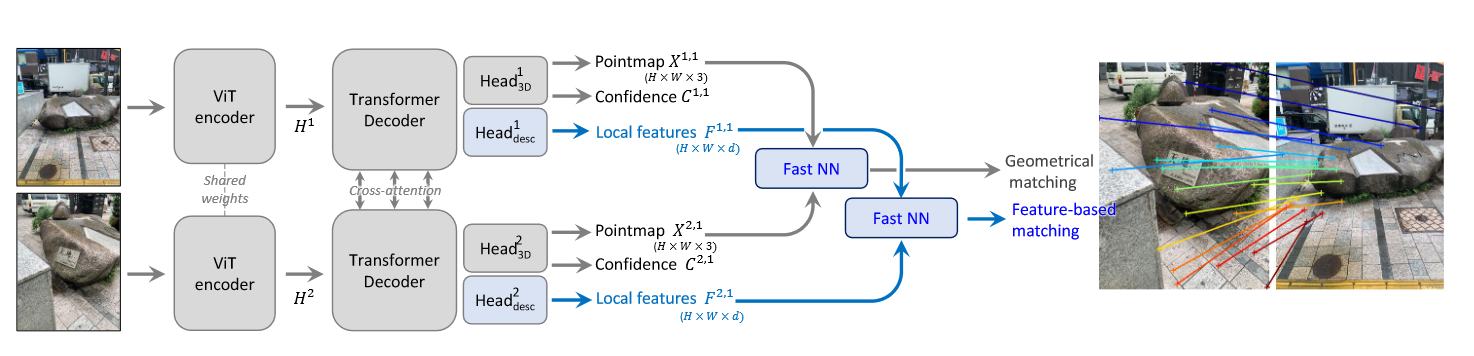
对于H*W*3的输入图像而言,最终除了会输出一个H*W*3的PointMap和一个H*W的ConfidenceMap外,还会为每个像素生成一个长度为d的特征,也就是H*W*3的LocalFeature,也就是用神经网络来提取特征。剩余的网络部分与DUSt3R保持一致。
关于loss部分,MASt3R matching对DUStER的
具体而言,MASt3R matching取消了不同的深度正则化项,直接用gt的平均深度(即
然后因为新增了一个用于匹配的head输出,而希望每个像素点最多和另一张图的一个像素点匹配,作者将这部分描述为infoNCE loss,假设gt的匹配点为
其中
这里面的
所以最终的loss为:
有了上述模型与Loss就可以训练了,但是网络的输出还需要经过一些处理,才能得到需要的匹配关系。注意,网络只输出了PointMap和每个像素的LocalFeature,而期望得到的是两个图像之间的像素点级别的匹配,匹配相关的部分就是图中新增的NN模块。
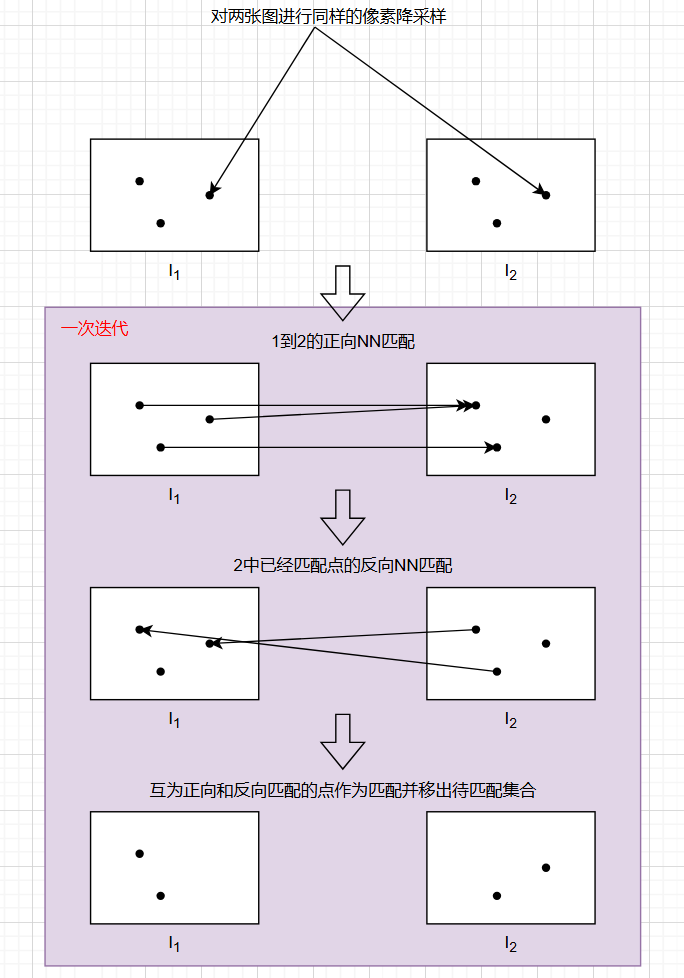
作者在匹配时设计了一个新算法,先对两个图像对应的特征点进行降采样,先得到图像1的特征点对于图像2的正向NN匹配,在从已经匹配上的图像2特征点反向NN匹配到图像1,能够形成闭环的NN匹配关系便成为最终的匹配。一次迭代同时包含正向和反向NN匹配,通过这样就能快速收敛。
作者在正文里嘴上diss了一下kd-tree:
While optimizing the nearest-neighbor (NN) search is possible, e.g. using K-d trees, this kind of optimization becomes typically very inefficient in high dimensional feature space and, in all cases, orders of magnitude slower than the inference time of MASt3R to output
但是实际身体还是很诚实:
For the fast reciprocal matching from section 3.3, we implement the nearest neighbor function ( (x) ) from eq. (14) differently depending on the dimension of ( x ). When matching 3D points ( x ^3 ), we implement ( (x) ) using K-d trees [56].
到这matching还没结束,还有一步优化,因为之前不是降采样了嘛,降采样之后的最邻近不一定是真的最邻近,所以还要回到原分辨率的图像上去,重新分块再来一遍匹配(无论是分块还是降采样肯定都比直接全局NN快得多)。这里主要是这个函数(我这里引用的代码是MASt3R-sfm的代码,我没clone MASt3R matching的repo,所以可能会和论文提到的有些出入,比如MASt3R matching里提到的FAISS这里就完全没出现):
1 | def fast_reciprocal_NNs(pts1, pts2, subsample_or_initxy1=8, ret_xy=True, pixel_tol=0, ret_basin=False, device='cuda', **matcher_kw): |
这样就得到了最终的匹配关系,因为懒得clone了,就没实际测试效果,但看论文的example感觉挺不错的,一些相当抽象的匹配点对都能找到。

多帧输入构建共视图
这里开始正式进入MASt3R sfm(后文全部简称为MASt3R),同理我们先看总览下pipeline:

虽然看起来MASt3R直接在pipeline里集成了多帧输入,但是因为网络从DUSt3R一脉相承仍然只能一次处理两张图像,只是MASt3R的在确实多帧输入的处理方式上存在很多改进,效果也确实好很多。
MASt3R sfm是基于MASt3R matching的网络结构来开展的,MASt3R sfm只用了MASt3R matching里encoder的输出作为tokenFeature(注意不是head输出的LocalFeature),而不需要像素级别的匹配关系。
MASt3R也是像DUSt3R那样,先基于重叠视角构建一个Graph,具体做法如下:
- 根据encoder输出的tokenFeature,使用最远点采样算法(farthest point sampling, FPS)来选出N个关键帧(或控制帧,理解成聚类算法的中心点一样东西),然后把这N个关键帧两两相连,构成
条边 - 剩余的普通帧连接到最近的关键帧上,然后还会通过NN算法连接到最近的k个普通帧上去
在上述过程中计算特征的距离完全是基于tokenFeature,对tokenFeature白化(feature whitening)后计算二进制距离来实现的。而由于一个图像不止一个特征,所以会采用ASMK算法计算相似度来描述两张图像重叠视野,也就是用ASMK相似度来描述两张图像是否接近。
这里使用encoder输出而不是head的输出作为feature的好处是显而易见的:encoder的输入只要一张图像,所以每张图像都过一遍encoder就行了,而encoder又是不可缺少的步骤,相当于提取特征没有开销。
也就是构建pair时用encoder输出作为tokenFeature,而后续的匹配和优化则使用head输出的LocalFeature。
匹配与标准点图
通过上述共视图计算两两pair的PointMap、ConfidenceMap和LocalFeature后,会首先使用MASt3R matching中提到NN算法来匹配一个pair中的2D-3D点(分别得到
但是从构建共视图中就可以看出来,同一张图像肯定不止参与一个pair的运算,这样相当于一张图像同时有好几个PointMap,每个PointMap都可能有一定误差,而且一对多这样子也不方便后面计算,所以作者将一张图像的所有PointMap合成为一个Canonical PointMap(姑且翻译成标准点图),其实就是PointMap对于置信度的加权平均(这里
BA优化
回想一下,我们期望得到的输出是3D点云,使用Canonical PointMap作为点云可以吗?显然不可以,首先多帧之间的Canonical PointMap不一定对齐,其次每帧估计出来的Canonical PointMap也不一定准确(比如不满足针孔相机模型,所有2D-3D连线不一定能过光心)。
在DUSt3R里是仅对共视图的连接关系进行多帧优化,相对而言确实比较粗糙。而在MASt3R里,首先会先固定Canonical PointMap来优化出一个尽可能满足针孔相机模型约束的焦距,从而恢复出一个比较接近的相机内参矩阵,这个优化仅涉及自身的Canonical PointMap,所以跟pair什么的没关系,如果图片是不同相机拍的也可以为每个相机做单独的优化:
然后来优化Canonical PointMap对于像素的重投影误差,这会同时优化相机内参K和共视图中pair连接的相对位姿(外参),这是使用3D点误差来优化的。这里的
这里的
论文里提到会使用anchor的方式来优化,粗略地看了下代码,好像除了优化内参K之外都是基于anchor来构建优化的。
解释下为什么要这么做,归根到底其实还是tokenFeature无法精准匹配的问题。假设存在a、b和c三张图用于重建,经过MASt3R网络提取特征后,
解决这个问题思路其实也不难,就是认为一个小区域内的像素相对深度是准确的,然后算一下这个小区域的平均深度来作为anchor,优化的时候只优化anchor,然后反推出每个像素的深度。这样虽然
在代码里,考虑到可能存在的匹配点对不足的问题,MASt3R还会优化DUSt3R的那个全局BA误差。
实际测试
MASt3R的效果还是相当不错的,我们用同样的场景来测试下,这次脸的点云相当好,起码不扭曲了:
