一些论文
EventGPT
架构:
- 输入:将一段事件的事件划分成多个Window,每个window负责处理该窗口内的事件,组织成类似图像的格式(论文没说,也许是ts或者aa map之类的)
- 编码:openclip作为编码器,将每个window的frame编码
- Spatio-Temporal Aggregator:因为有多个window,编码结果其实是
,沿着空间平均池化得到这段时间一共发生了什么动作;沿着时间维度最大池化得到在每个特定的时间点,整个画面整体发生了什么变化。 - visual-adapter+event-adapter:两个mlp输入到llm中
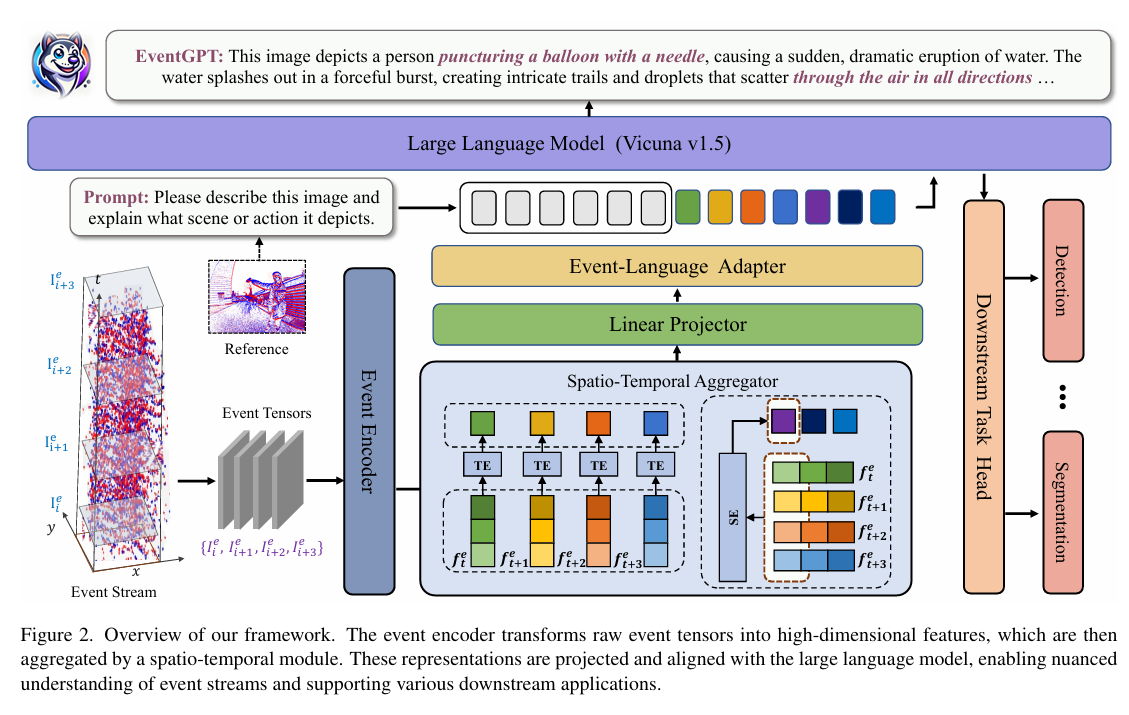
三步骤训练:
- 冻结openclip、llm,训练visual-adapter训练视觉语言对齐
- 冻结openclip、llm和visual-adapter,训练event-adapter和spatio-temporal aggregator训练事件理解
- 微调整个模型
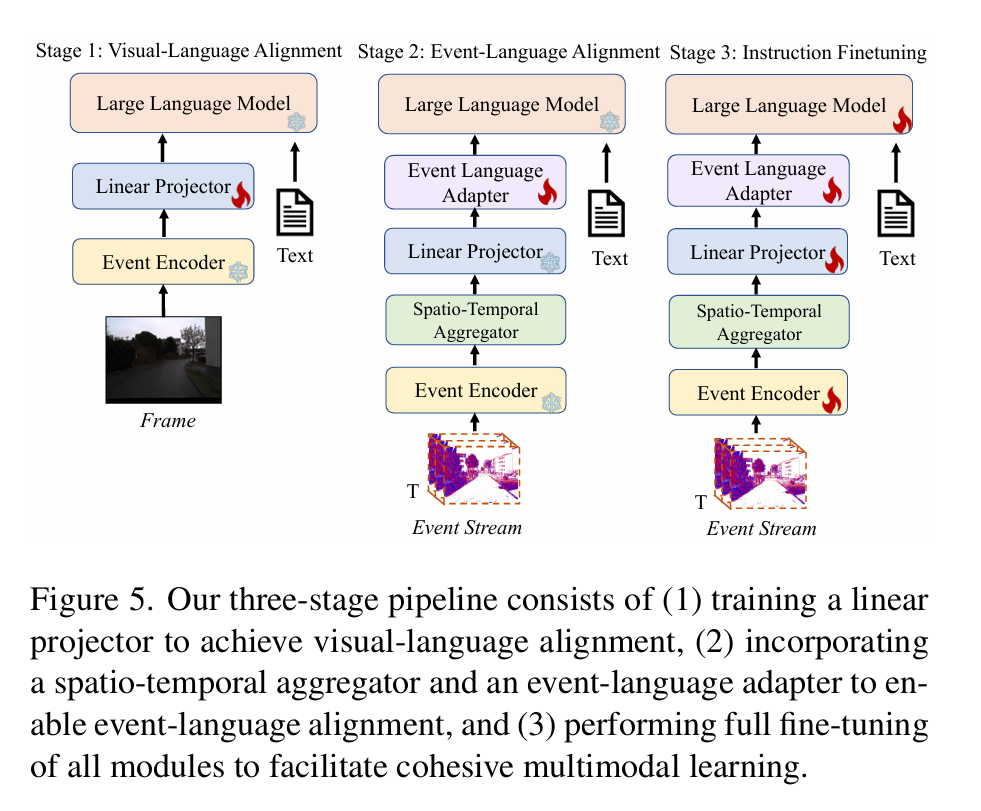
RT1,RT2和openvla
- RT1:小模型,离散化输出,视觉编码和指令编码高度融合,transformer解码出输出token
- RT2:vit(语义)+pale-e/PaLI-X,离散化输出,AR自回归,协同微调,每个batch内混入qa问答防止灾难性遗忘
- openvla:siglip(语义)+dino(空间)+lamma,离散化输出,AR自回归,利用llama在Open X-Embodiment上微调(不协同微调应该是数据规模问题,基模的qa能力肯定也是下降的)
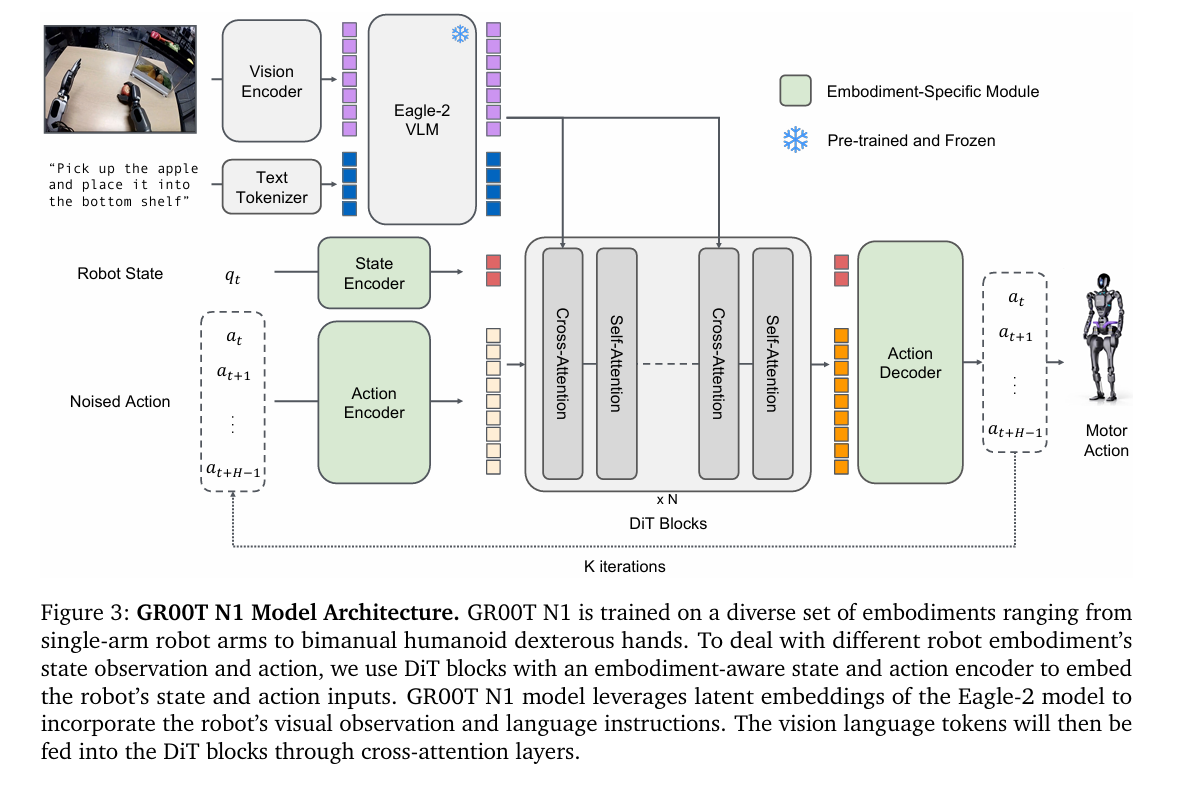
GT001-N1, N1.5, N1.6(人型)
- GT001-N1:大小脑,快慢系统。大脑vlm利用eagle-2(2b),冻结;小脑为dit,接受state作为输入,并将vlm输出作为cond注入到dit中,denoise出action。
- GT001-N1.5:换基模,允许微调vlm扩展语义。
- GT001-N1.6:Cosmos世界模型,不依赖视觉语言。
数据部分(LAPA):使用vqvae来获取视频中动作对应的action,输入相邻两帧,并将latent vector作为实际action(但这个action不能被人或者机械臂理解,只是一种语义表示,其目的是让不同的人在类似视角下的相同动作语义一致)。举例:第一人称视角下不同的人对于抓苹果这个动作的latent vector相似。
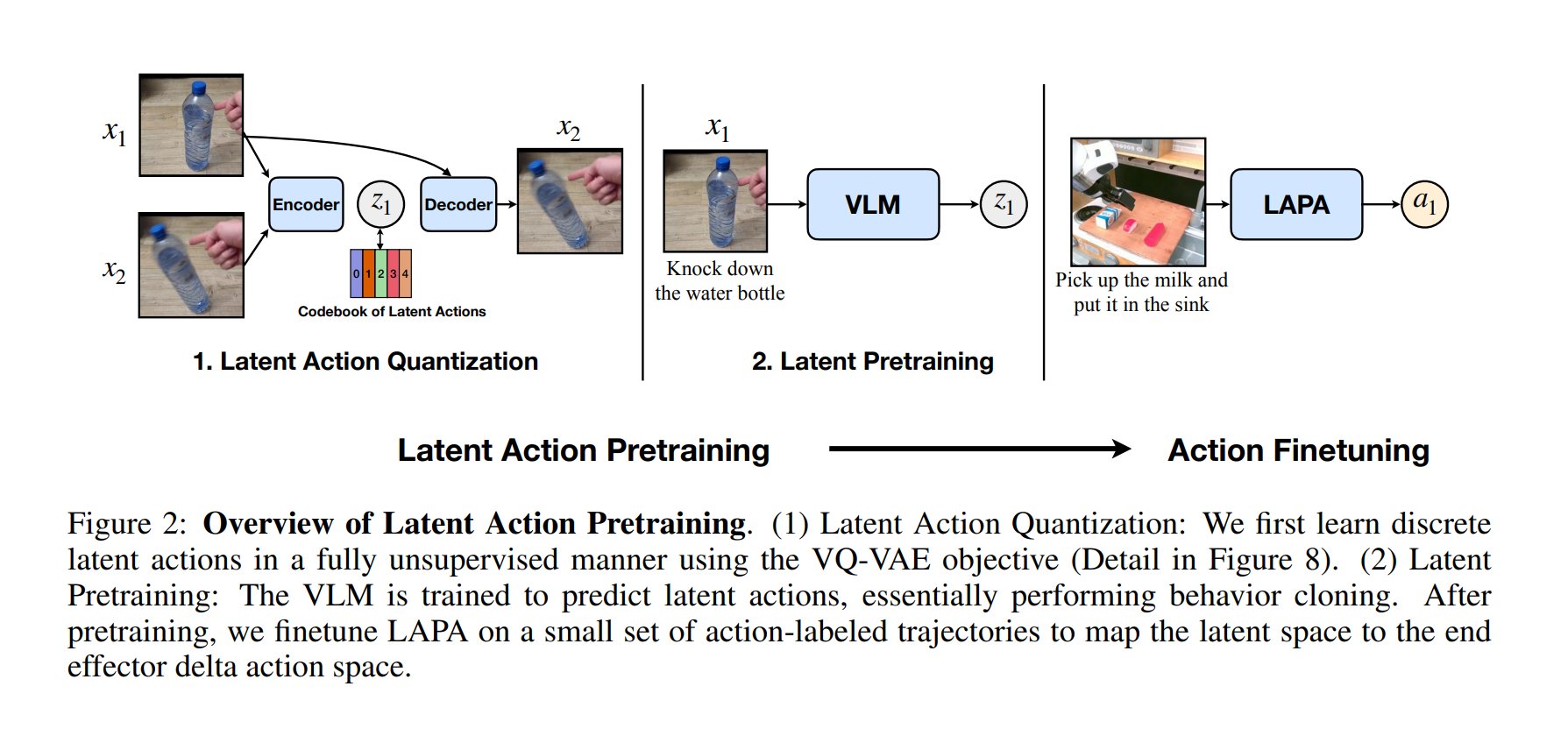
语义action训练:上述提取的video-action序列被作为一个单独的虚拟机器人LAPA的真值数据,由于每个机器人具有单独的decoder head,因此这个虚拟机器人的decoder head解码就是latent vector,用这种方式训练dit的先验语义。
微调训练:用真实数据训练真实机器人的对应的decoder head与dit,但是这会导致灾难性遗忘,因此还引入了很多反事实场景用于训练。
反事实场景:采集少量数据(例如把苹果放到篮子里),再通过sora一类视频生成模型生成反事实数据(例如把香蕉放到桶里),这些反事实数据有相同的视角和机器人外观;最后使用逆运动学IDM模型生成每帧对应的action(这也是一个神经网络,类似vqvae,但是他直接给出的就是关节状态)就可以得到大量的数据
论文里在训练具体的机器人时最终用IDM取代了LAPA(post training部分,pretrain还是语义的)。因为当采集的真实数据较少时,LAPA效果更好(显然真实数据少意味着无法训练一个有效的IDM);而反之IDM效果更好(post train还是微调dit)。
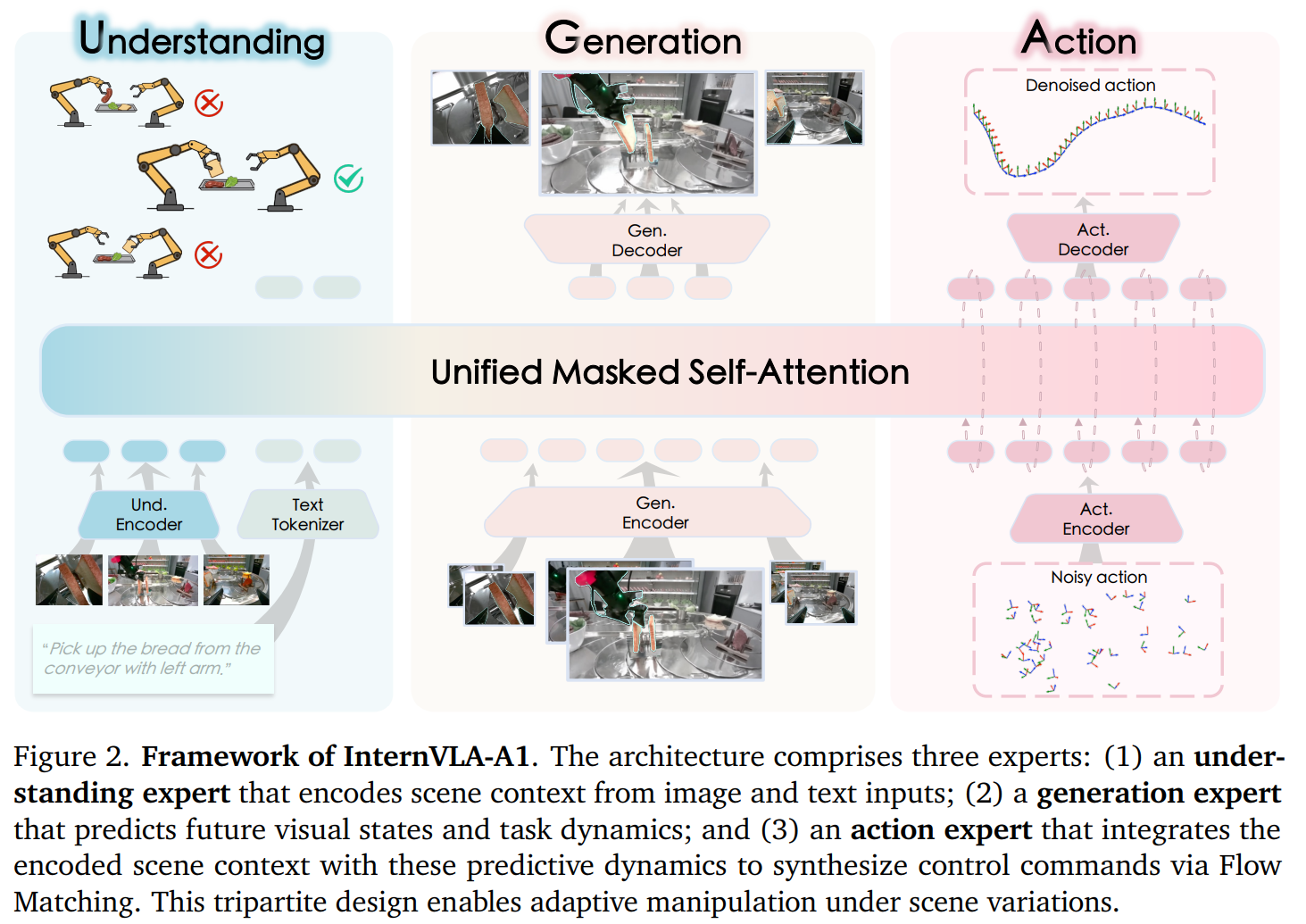
InternVLA A1,M1
- A1:比M1更加强耦合,所有模型共享atten,通过mask来控制每个模型能观测到哪些输入。有理解专家、生成专家和动作专家,AR自回归,每个专家通过设计mask可以观测到输入以及上一个专家的输出。生成专家会基于当前几帧生成未来帧的结果(可以理解成未来物体的位置或者执行动作后结果),最后动作专家会结合当前以及未来toekn输出动作结果。其中动作专家是在COSMOS VAE结果下进行编码,可以通过decode解码出未来的帧。
- M1:Qwen2.5-VL-3B-Instruct作为planner,DINOv2+Dit作为action expert。通过cot的方式先输出spatial planner,然后通过再结合planner的结果输出每个到达坐标,最后这些信息通过projective layer作为cond进入dit。训练时先使用2D spatial数据pretrain,然后post train则是利用spatial训练。
M1这个planner强调spatial,输出的cot是像素空间点对点的移动;pi0.5的planner则是逻辑层级上的分级(先做什么,在做什么)。并且M1松耦合,通过projective layer转换cond;pi0.5则是紧耦合,直接输出expert接收的cond。
对于A1而言,其提供了一个稳健的物理先验用于估计未来事件,比如想要抓取一个传送带的物体,常规vla一般只能抓取观测时的位姿从而失效。而a1由于有生成专家,所以可以基于前几帧的数据生成未来某个时刻下物体的位置,所以动作专家可以基于上述信息做出正确的决策。但这个模型还是mllm作为backbone(Qwen3-VL)

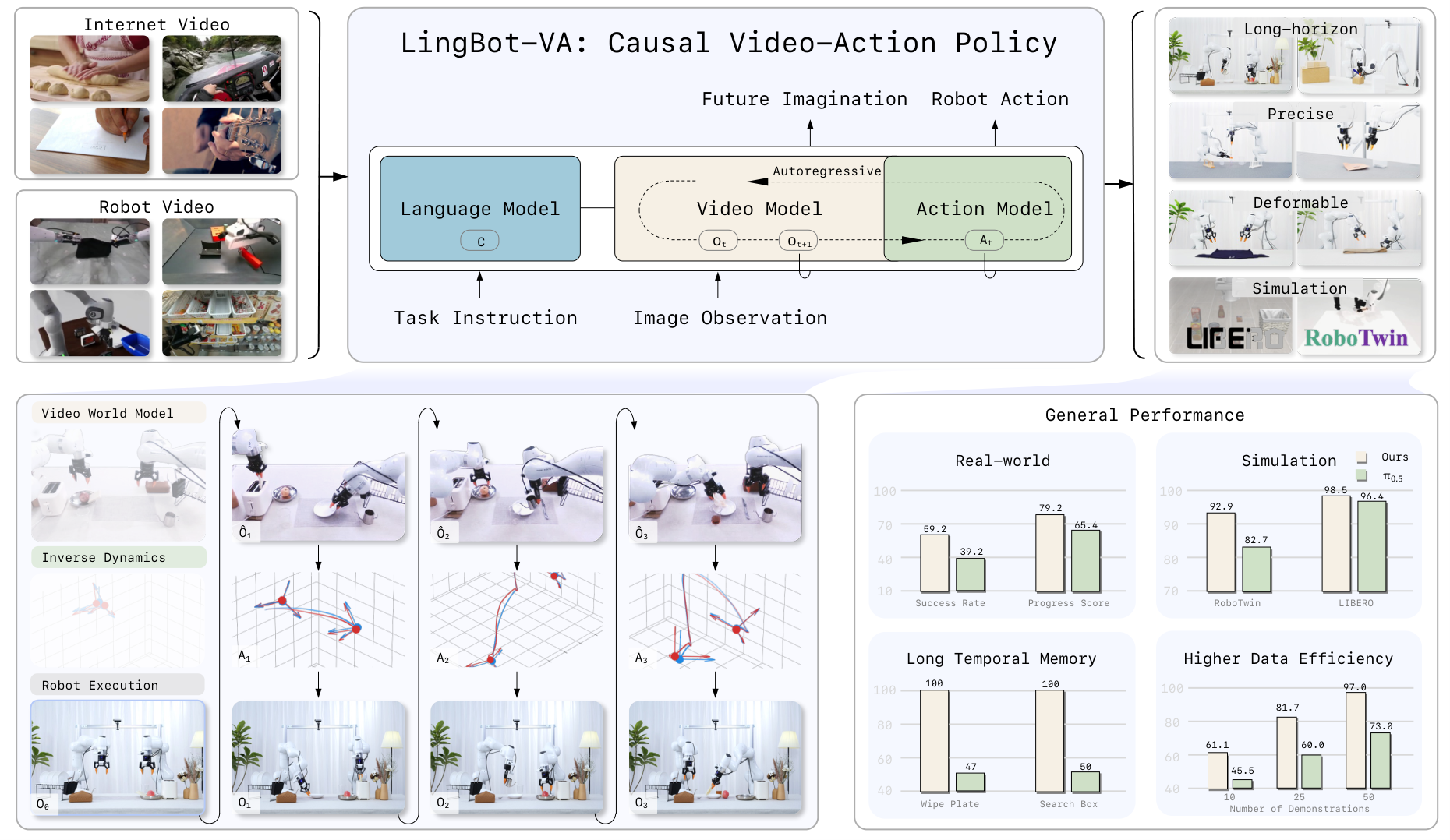
世界动作模型DreamZero、lingbot-va
VAM其实就是把backbone换成了video generation模型,然后通过预测未来时刻帧来对齐physical,先天具备数据大规模化、模型可解释性和隐式物理信息表征。
- lingbot-va: Wan2.2-5B,MOT架构。第一步,根据指令让世界模型生成解决方案(未来的视频);第二步,使用逆运动学模型(IDM)从未来动作里解码出相应的action。输入会混合frame和action,且按照不同采样比例融合;同时由于两者数据分布差异大,通过
这个因子快速收敛。最后,实际上不需要精确采样出video,带噪声的video一样可以用于后续action推理 - dreamzero: Wan2.1-I2V-14B,同时预测出video块和action块。latent video vector和action vector联合向量做fm损失。
感觉小一点的模型用MoT会好一些。这两篇文章还有很多内容在加速上。另外,dreamzero做了只有人物演示post training并有显著提升的实现。
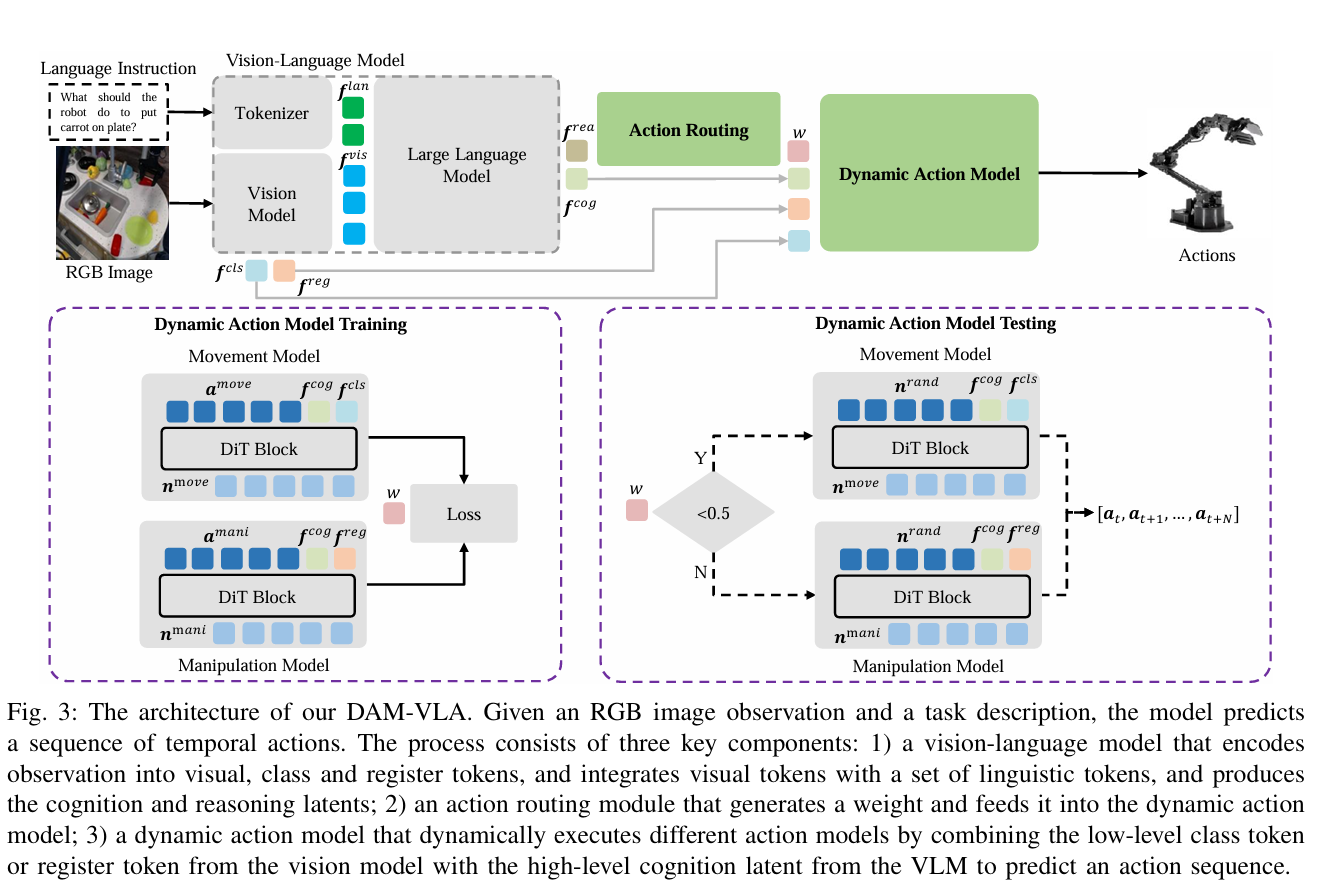
DAM-VLA 2026.3 arxiv
引入MoE架构,将diffusion head分为快速移动head(接近)和精细操作head(处理)。vlm输出一个weight,用于评估当前处于哪个状态。用dino的cls和register token分别处理全局或者局部编码(register token让dino比vit在atten图上降低伪影)。
全局轨迹级权重:由于精细操作和长程操作数据量不匹配,作者选出夹爪移动的瞬间,并用不对称高斯分布对附近loss加权。夹取前权重大;而夹取后权重小,因为夹取了就相对比较稳定了。
局部动作块级权重:一般一次会一次预测出一个action chunk,但是由于moe架构,导致预测近的比较准,远的就不准。用指数衰减对一个action chunk进行加权。
VLM-PoseManip(灵巧手的文章) 2026.3 AEI
非end2end,vlm+G-DNINO用于分解指令+HOID检测;Diffusion head计算出物体的6D pose;IK+优化+affordance计算灵巧手params。
工程向论文。
PhysGraph 2026.3 arxiv
GNN对HOI建模,物体(手掌,手指,工具,物体)为节点,接触关系(物理连接,接触)为边,构建图神经网络。
通过引入物理先验偏置,来为网络提供先验信息,先验的偏置矩阵会被直接加在atten map上。具体而言,包括空间先验(沿着机械臂/手指关节,距离越近的部件越应该互相参考)、边缘偏置(区分两个部件是骨骼硬连接还是物理接触)、几何偏置(在三维空间中靠得越近的部件,交互的可能性越大,即使它们不属于同一只手)、解剖学偏置(同一根手指上的关节具有串联运动特性,不同手指的同一层级关节,比如所有手指的中关节,具有协同收缩的特)。
偏置矩阵被直接加在atten上,对于增加偏置的节点呈现出更高的交互可能。为了避乱偏置混乱,利用多头注意力本身特性,在不同head上增加不同的偏置,从而让每个head学习不同先验。
对标maniptrans,但是实验不充分,头重脚轻。
MEM: Multi-Scale Embodied Memory for Vision Language Action Models 2026.3 arixv
Pi0组提出的解决长时记忆问题的一篇文章,比如让机器人在厨房连续工作15分钟这种任务是很困难的,这篇文章能够在不牺牲推理速度的前提下,让机器人拥有最长15分钟尺度的记忆架构。
短期记忆和长期记忆都是必不可少的,但是不能直接通过将累计帧全部输入的方式来增加记忆时间,否则计算量爆炸。这篇文章对于短期记忆处理方法是:先看懂这一帧有什么东西在哪里(空间),再隔几层网络让模型想这个东西过去几帧里是怎么动的(时间);而对于长期记忆处理方法是内置一个高层策略,将已经做过的动作做成总结丢弃冗余信息。
这篇文章的短期记忆虽然输入多帧,但是通过一个video encoder编码后只会出单帧,不会把所有的frame全部输入到llm里。这个video encoder会让每帧里的patch最对比,吸收掉所有冗余表征。
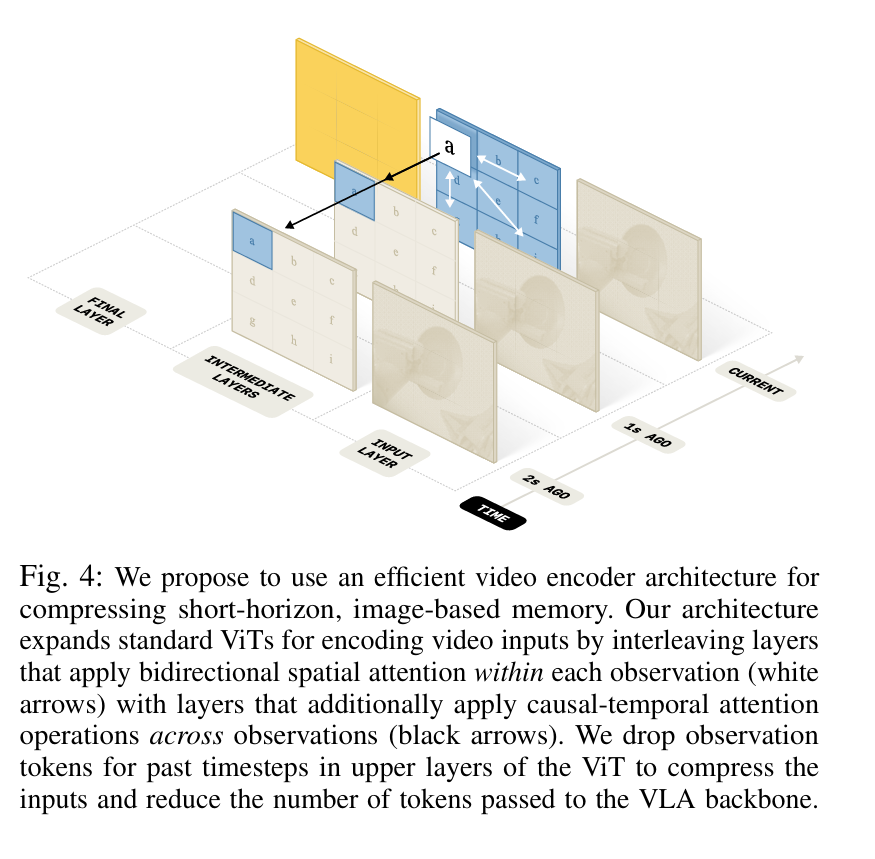
图像块只跟同一帧里图像对比(白色箭头),每隔4层网络施加一次时间注意力,每个patch只跟过去时间上的patch对比(黑色箭头)。当一切计算完成后,把历史17帧丢弃只保留最新帧。video encoder是连同mllm一同训练的。
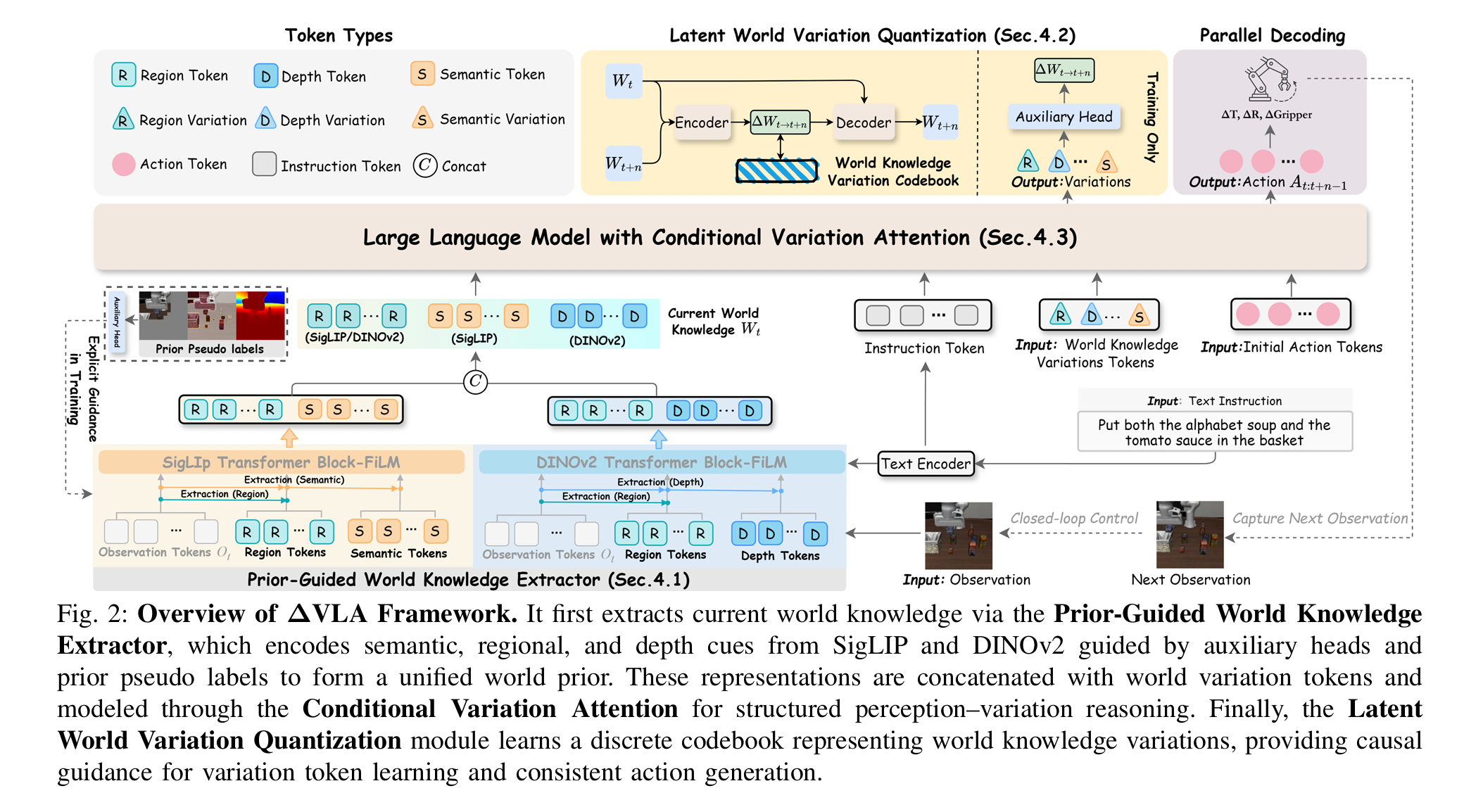
Delta VLA 2026.3 arxiv(看起来投的应该是eccv)
- 核心是用一个token取代图像,降低运算量
- 提出了两个组件PWKE (先验引导的世界知识提取器)和LWVQ (潜在世界变化量化)。前者用于将输入图像编码成Wt(包含区域token,语义token,深度token,用siglip和dino提取出来;从sam3等模型蒸馏);后者负责将模型预测出来的Wt+1的Δ值量化,将回归问题变为分类问题。
- CA-Atten负责让模型在深度预测时仅利用深度token的信息,避免模态泄露。同时因为不是自回归,CA-Atten也负责确保每一token仅能利用到自身相关的信息,同时负责并行解码(仅针对action部分)。
- action chunk内部居然是双向atten,居然可以这么做嘛?
- 非自回归。
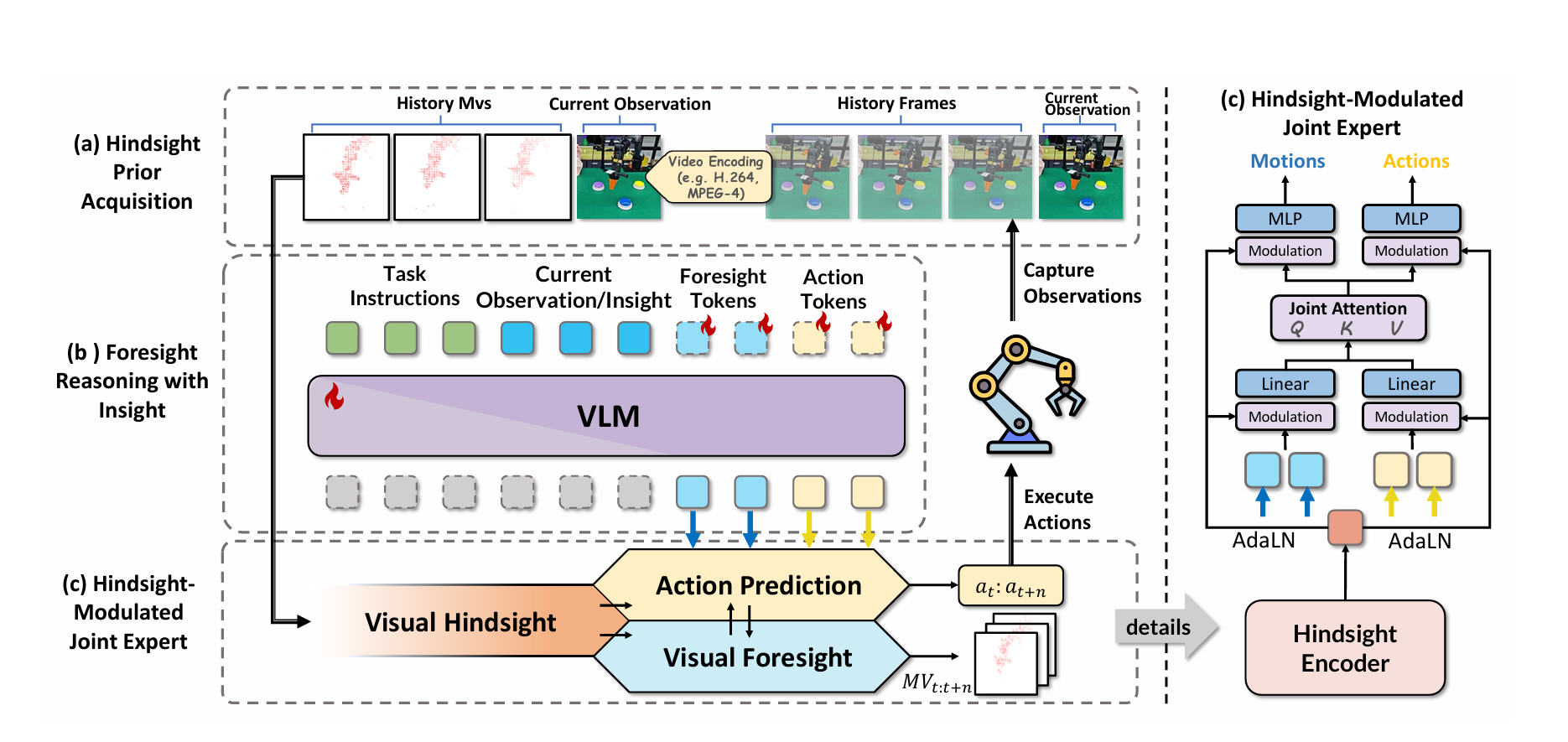
Hif VLA 2026.3 arxiv
- openvla这种基于马尔可夫假说,只能通过当前帧来规划动作,但是如果将所有历史帧传进来又会有很大开销。
- 使用视频编码器获取到运动矢量,然后使用这些矢量作为视频编码后送入到vlm。同时vlm也会同时预测未来的运动矢量和action。
- 把历史特征当成Condition,用AdaLN注入到MLP/Attention Head里,而不是塞进VLM里,因为vlm是在文本-图像模态上训练的,不认识这种数据,会降低泛化性。
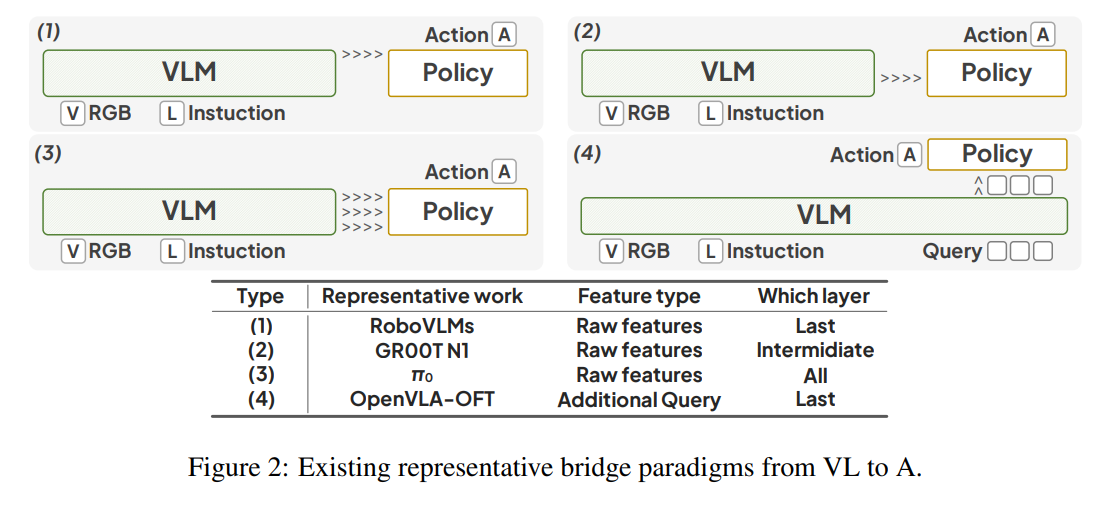
vla-adapter 2025.9
理论文章,值得一看。主要分析了不同的VL特征(单层 vs 多层;Raw vs ActionQuery)对动作生成的具体影响,并得出了“全层特征融合+双特征结合最佳”的结论。
现有 VLA 模型的桥接范式主要分为两大流派:使用Raw Features或引入ActionQuery。
早期的 RoboVLMs 等,认为 VLM 的最后一层包含了最高级的语义信息,直接把最后一层的特征送到 Policy 里。英伟达的 GR00T 系列,认为中间层保留了更多的空间细节和多模态对齐信息,因此提取特定的中间层(或前半部分层)送入 Policy。OpenVLA-OFT,在 VLM 的最后一层加入可学习的 Token(ActionQuery),让这个 Token 去聚集信息,然后只把这个 Token 送给 Policy。像pi0这种则是提取的是 VLM 的所有层的输出特征,然后layer2layer的当作cond注入到policy里。
key findings:
- 对于 Raw features,中间层比深层更好,深层基本为语义信息,而中间层特征刚好完成了视觉和文本的初步融合,同时保留了丰富的局部细节和空间坐标
- 对于 ActionQuery,深层比浅层/中间层更好,因为初始化的action query是无意义的
- 逐层注入policy效果显著好于单层注入。
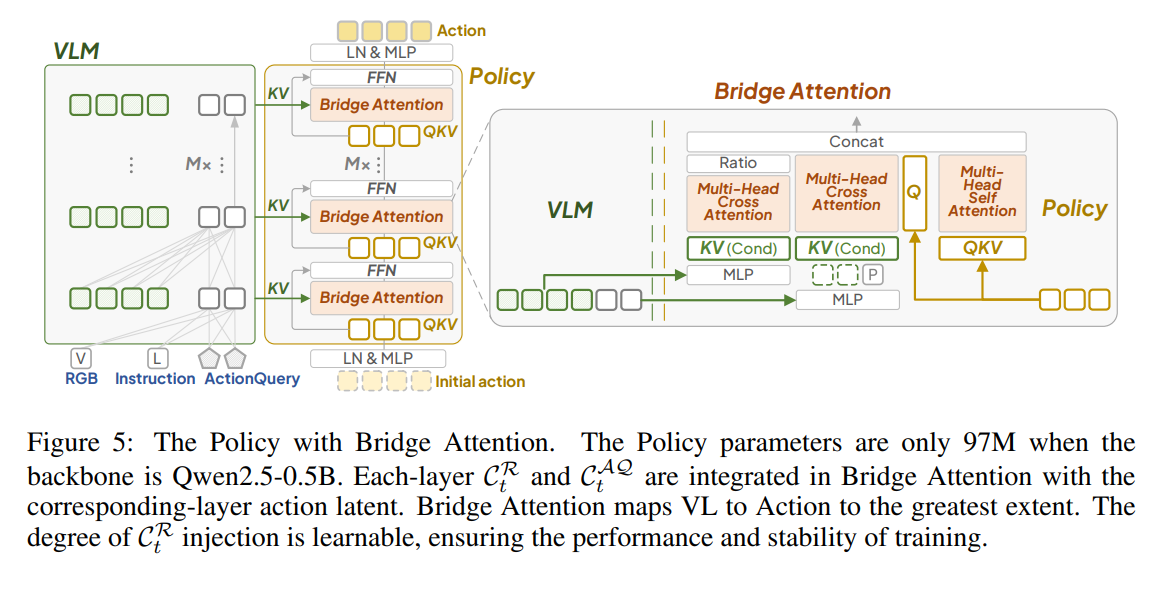
最终设计:
- 逐层注入,policy和vlm为等层数
- 同时使用Raw features和ActionQuery,可学习标量g作为raw feature的贡献度,tanh后作用在attention结果上拼接
- action query和本体状态P联合后做cross attention
没看代码,但应该和pi0那种双流结构是类似的吧。