一些论文
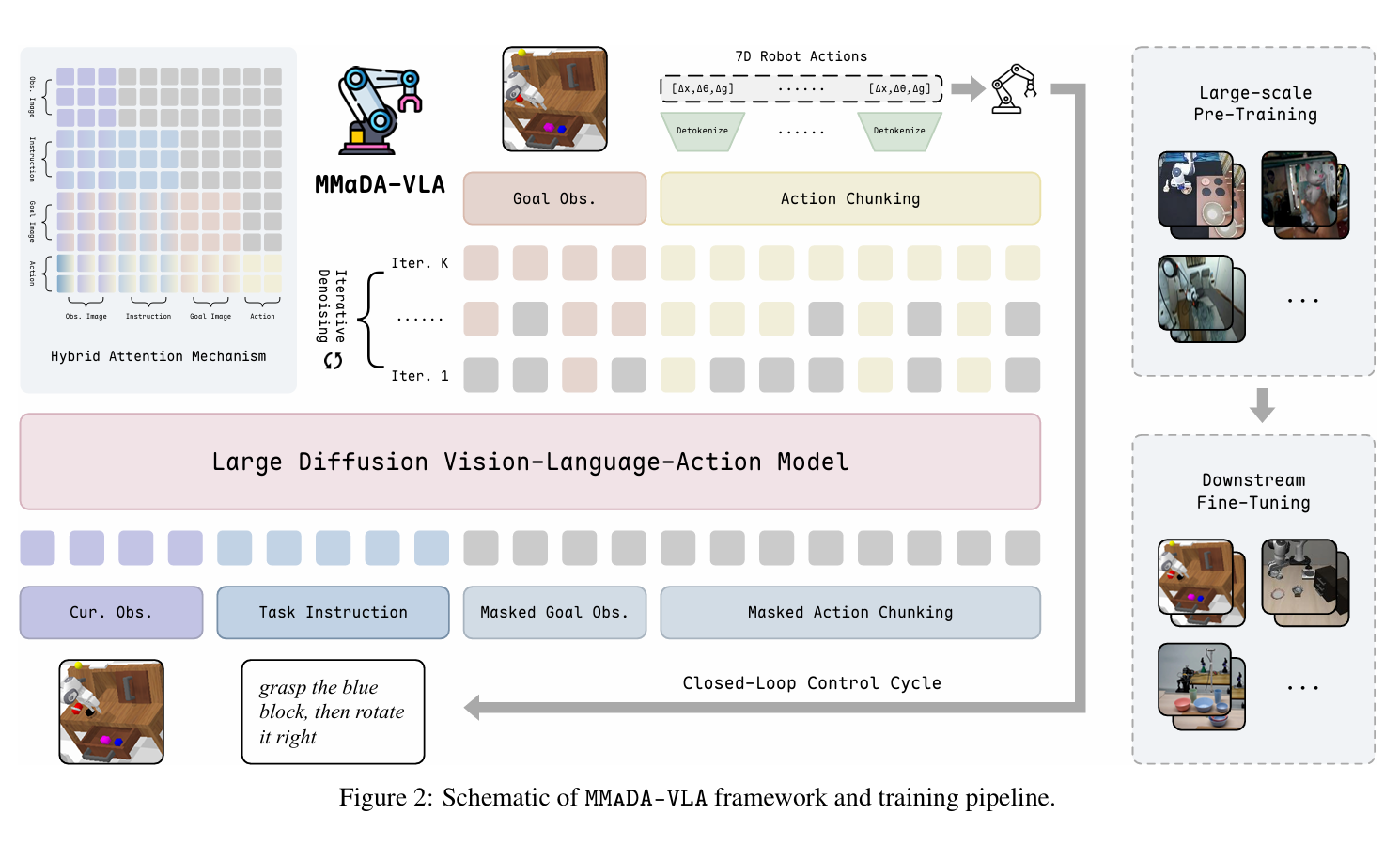
MMaDA-VLA 2026.4 arxiv
沿用openvla的离散action token机制,但是不自回归,留好空future img token和action token位置后直接并行解码。
推理时基于置信度的迭代 Mask 采样,future img和action都为mask,每一步并行预测所有token,并根据置信度保留相应预测结果(双向attention)重复迭代n次后输出所有token
但是不确定的mask会导致kv cache失效,这里沿用dLLM-Cache类似的设计。每次扩散的instruction和images被永久缓存;对于masked部分,不是每次生成都刷新缓存(因为去噪过程变化比较小)。
当触发刷新时,模型不会重新计算生成部分所有 Token 的 KV 值。它会计算当前 Token 的特征向量与缓存中旧特征向量的 余弦相似度 (Cosine Similarity)。模型只挑出那些相似度最低(即特征发生剧烈改变)的 k% 个 Token 进行重新计算和缓存更新)。那些变化不大的 Token 就继续沿用旧的缓存。
另外缓存除了k和v外,额外缓存了attentionout和ffnout。
但不确定这种近似行不行呀,感觉应该前几步denoise变化剧烈一些,后面变换应该会小很多,感觉刷新机制还需要变一变?
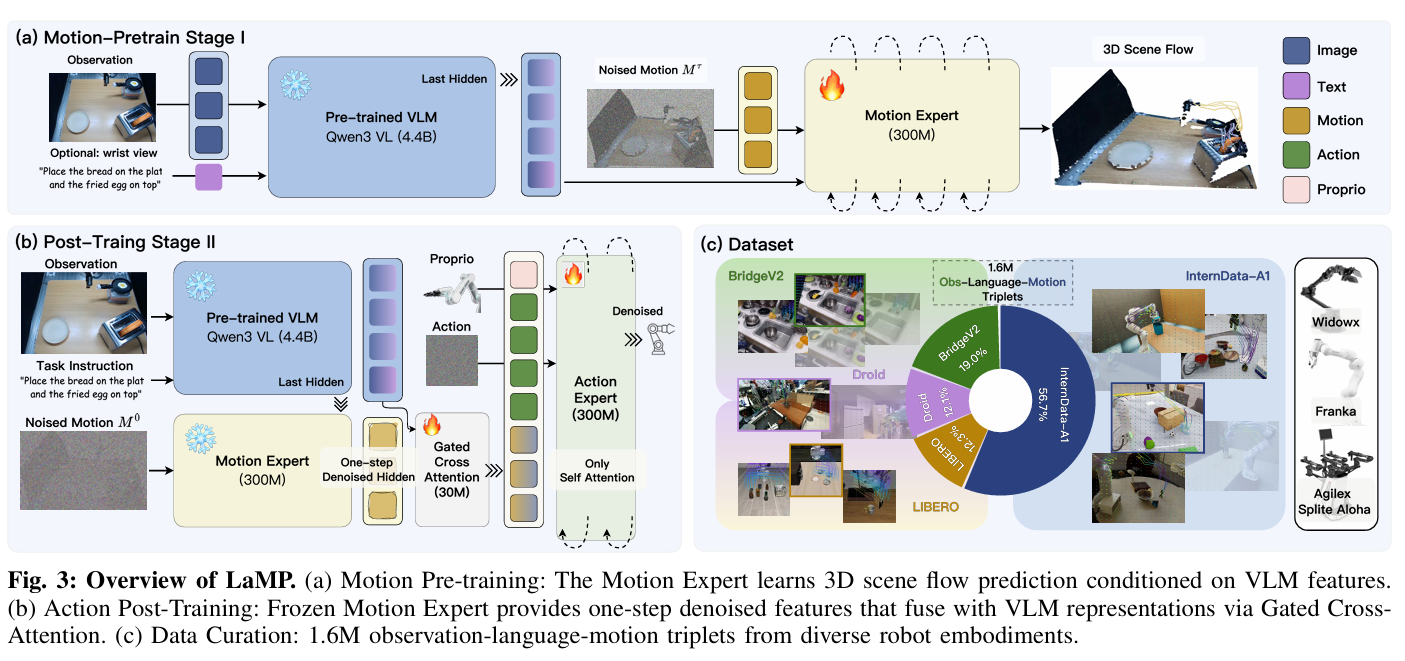
LaMP 2026.4 arxiv
用3D Scene Flow作为future prediction,用TraceForge生成出来的。
另外,直接把3d信息直接塞到2d表征里(add/concat)会不稳定,使用零初始化门控交叉注意力,即3d表征是逐渐引入的,保留vla一开始本身的稳定性(类似zeroconv)。
以及,注入公式是这样的:
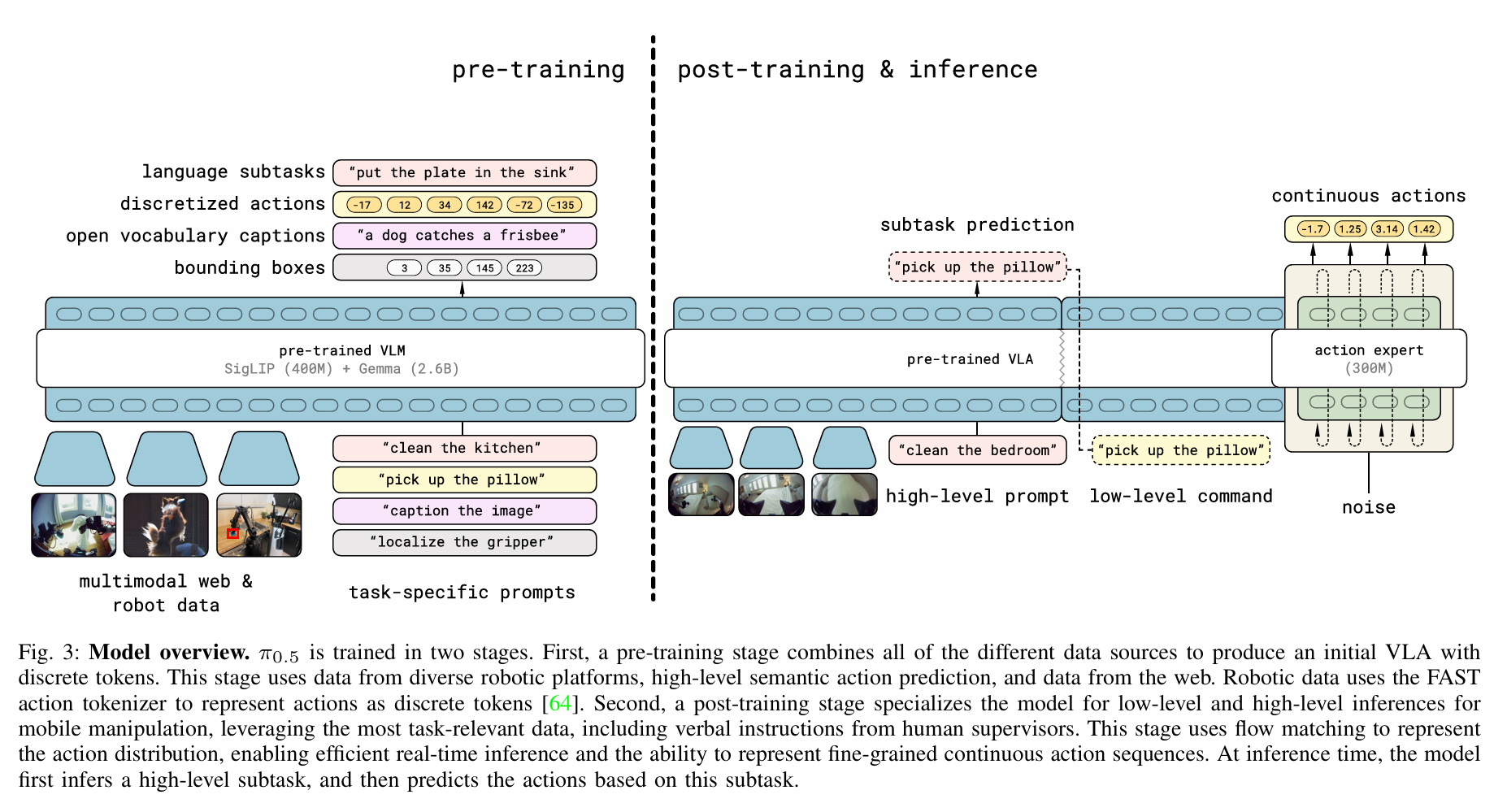
pi0 0.5 0.6 0.7
- pi0 mot架构,double stream,expert diffusion解码。训练时prefix suffix+timepos同时输入两个expert,拼接qkv-selfatten-拿出对应位置token。推理时先输入prefix,拿到kv cache后,使用suffix逐步去噪得到action。共享的只有atten算子本身,prefix双向atten,suffix-state观测不到suffix action,suffix-aaction能观测到全部。
- pi0.5,跟pi0类似的架构,区别是state离散编码(类似openvla)拼接在instruction后面和time embedding通过adaptive RMSNorm注入到expert里。论文里说会分解成subgoal,但是似乎代码里没有体现这点。
- pi0.5的high level train应该是跟knowledge insulation那篇有关,让动作专家的梯度不会回传到 VLM 主干,通过stop-gradient让动作专家自己练自己的,VLM 主干只用离散动作 token 的梯度来更新。
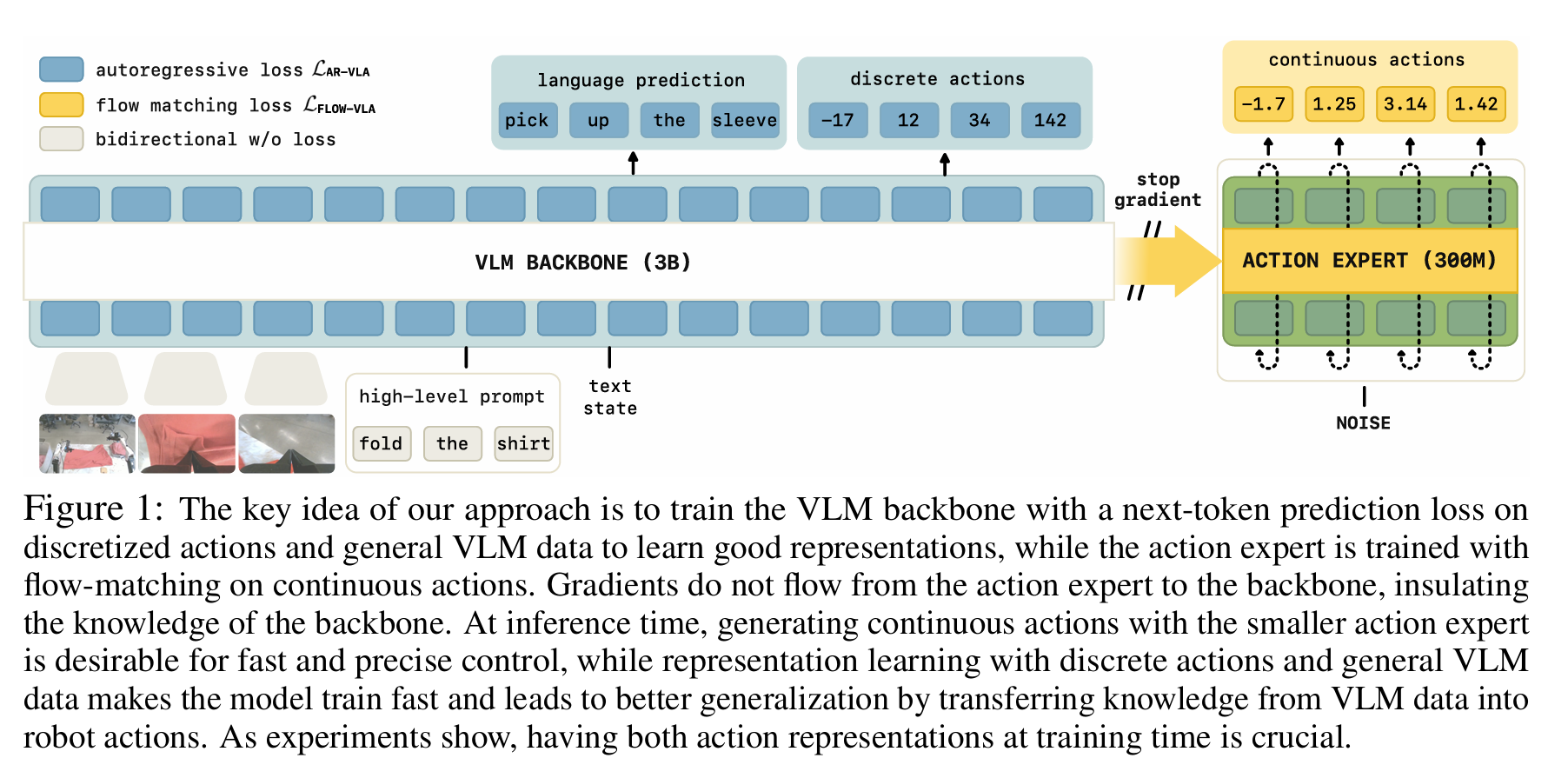
- pi0.6,引入RL(RECAP框架)。diffusion里因为不好求log-likelihood,所以ppo用不了。pi0.6使用正确(演示和纠错)和错误的动作输入,有一个价值函数预测预期还需要多少步才能成功。对于每一帧和对应的动作,使用价值函数计算对应的reward(结果-value),并基于reward对该帧打上pos/neg标签,并把这个标签作为prompt一部分输入到llm里。从而构建出pos/neg对应成功/失败的映射,在真实部署的时候永远使用pos标签来引导模型生成正确的动作。
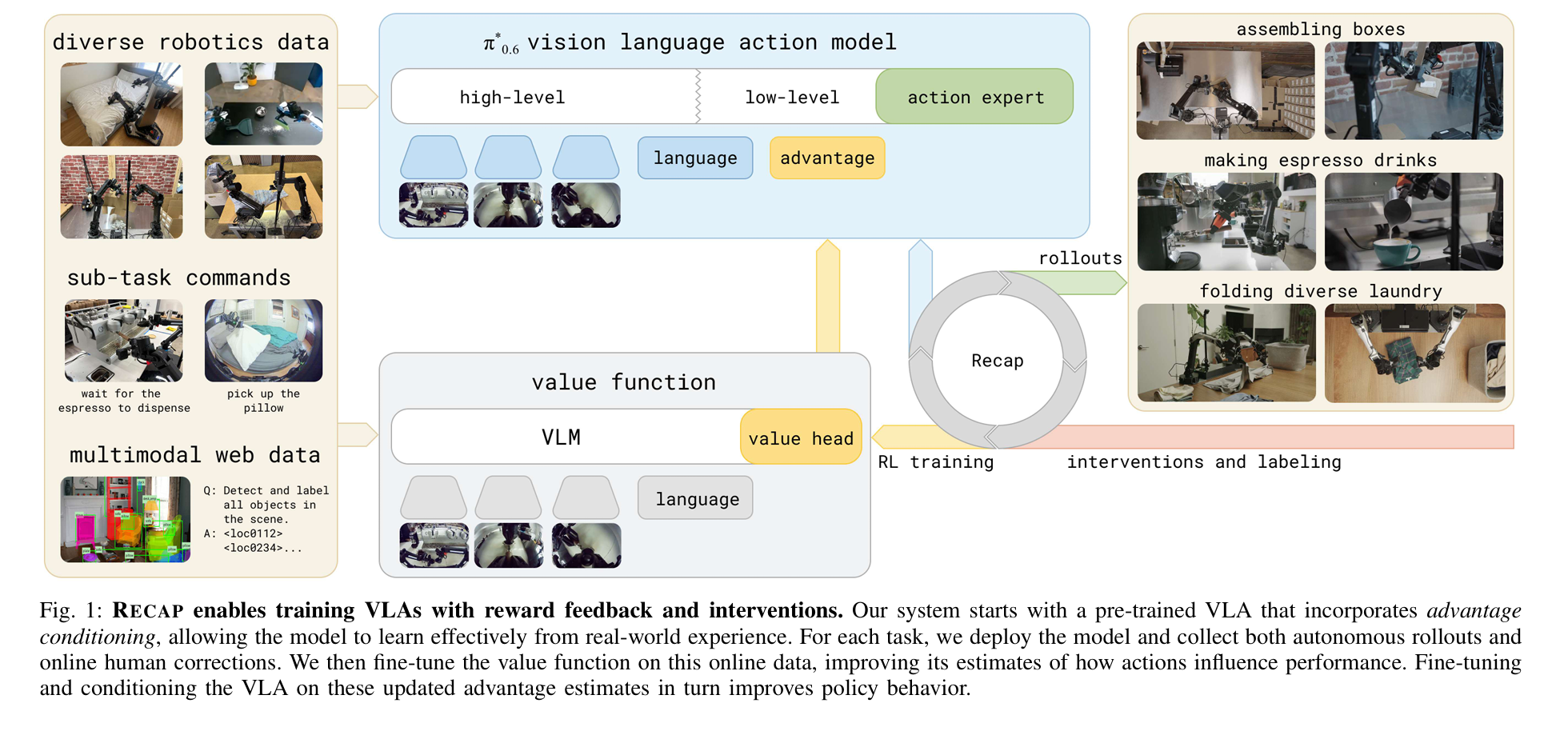
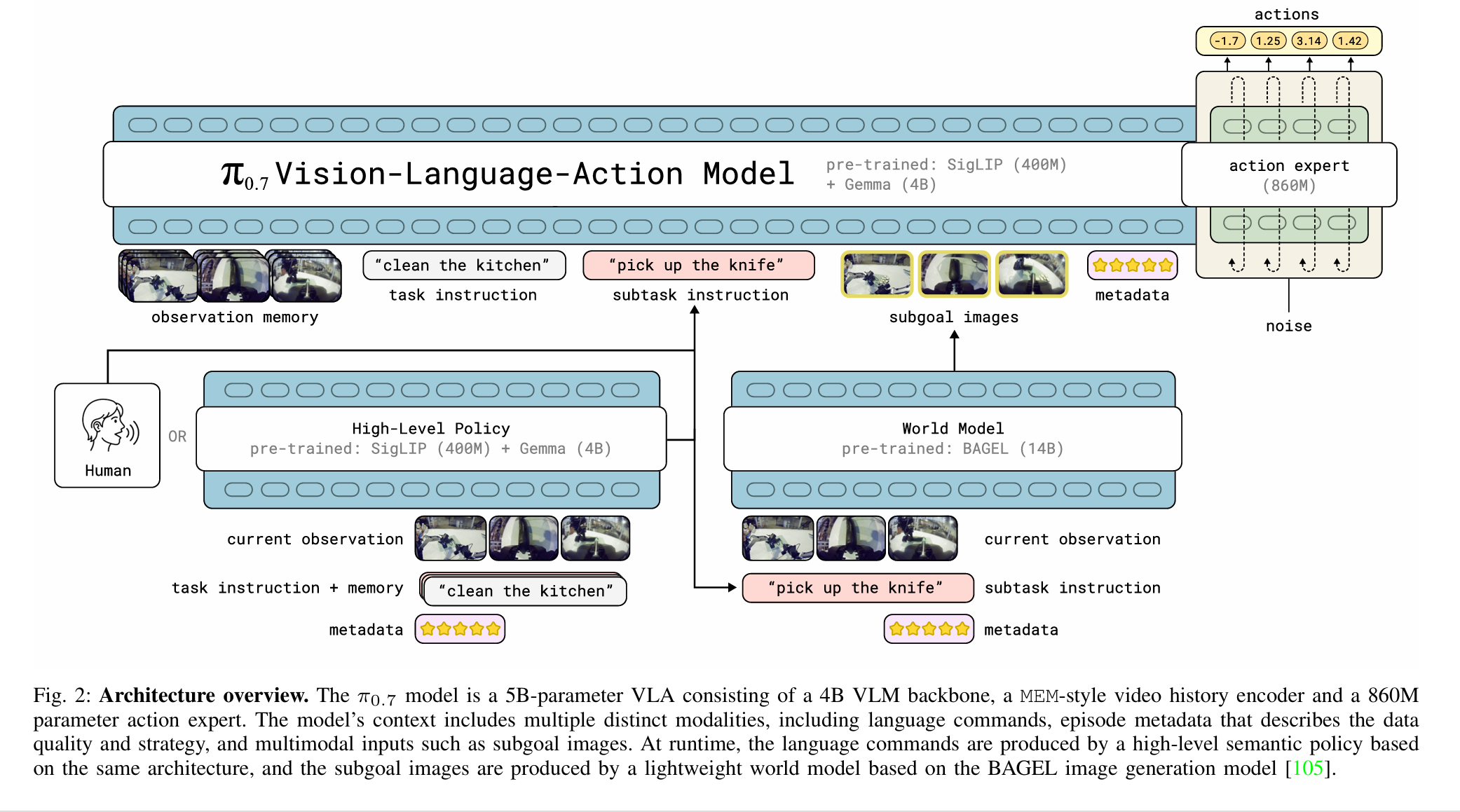
- pi0.7,感觉主要还是数据和prompt层面的工作。对数据标注评分、质量等细节作为Metadata,将次优任务引入到训练里;使用世界模型构建视觉子目标,起到类似affordance的作用。
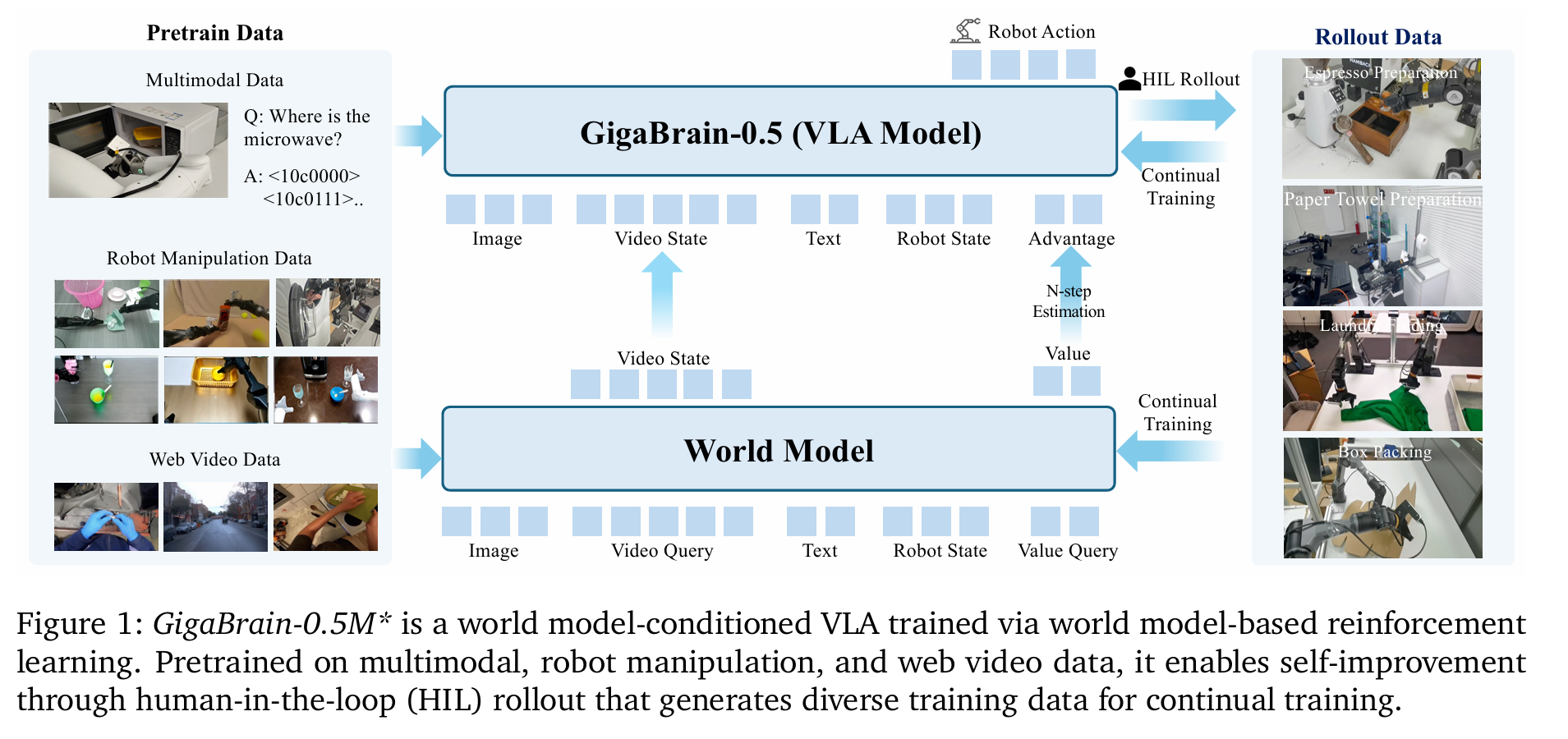
GigaBrain-0.5M* 2026.2 arxiv
引入世界模型,让策略在生成动作时能够参考预测的未来状态和价值评估,从而实现更鲁棒的长期规划。RAMP的四阶段闭环训练范式:
- 利用大规模真实机器人数据训练一个基于Wan2.2架构的DiT世界模型,该模型不仅预测未来的视觉隐状态特征(z),同时联合预测当前状态的价值 (Vt)(和pi0.6一样,价值函数定义也是pi0.6)
- 将基础VLA与WM结合。策略网络的输入增加两个条件:WM预测的未来状态特征z和离散化的优势函数
- Human-in-the-Loop数据收集。将模型部署到真机上自主运行,当发生错误时由人类专家介入修正
- 利用收集到的HILR混合数据,对策略和WM进行联合微调,实现能力的螺旋上升。
感觉主要改进就是给pi0.6的recap结构上接了一个未来状态。
JEPA LAPA JALA VLA-JEPA
JEPA用在pretrain里比较多,适合video gen和vla这种大量无标注数据的场景。核心是根据上下文,预测另一部分内容(重建内容)在 latent space 里的表示,天然倾向学dynamics-relevant latent variables
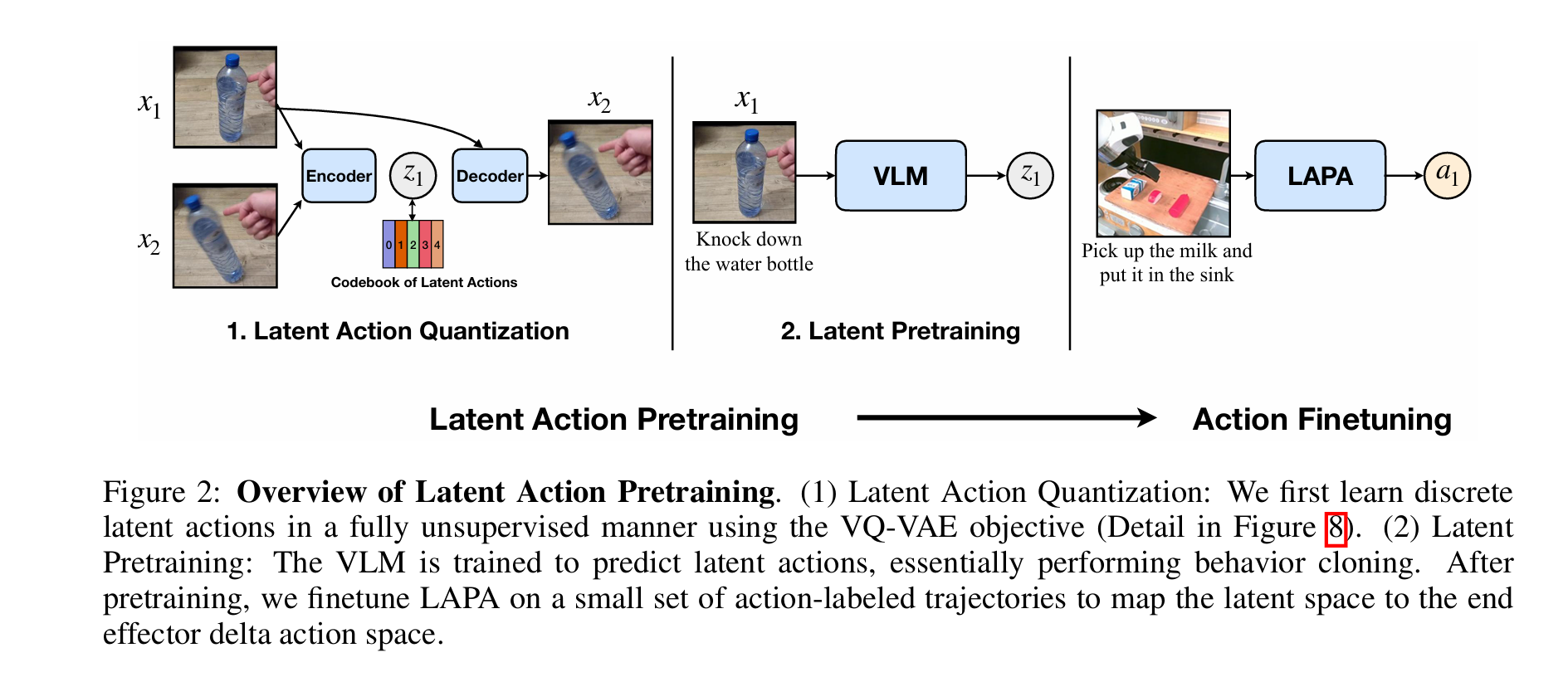
LAPA用在gr00t上,目的是利用无标签的数据进行自监督训练,用于pretrain。输入x1 x2的图像给vqvae encoder,输出code;然后decoder输入x1和code,试图重建x2,这样得到的codebook就相当于两帧之间的“动作”了。实质是构建像素空间的差值和动作的映射。后续可以把encoder作为idm来给无action视频打上lapa action label用于vla pretrain。
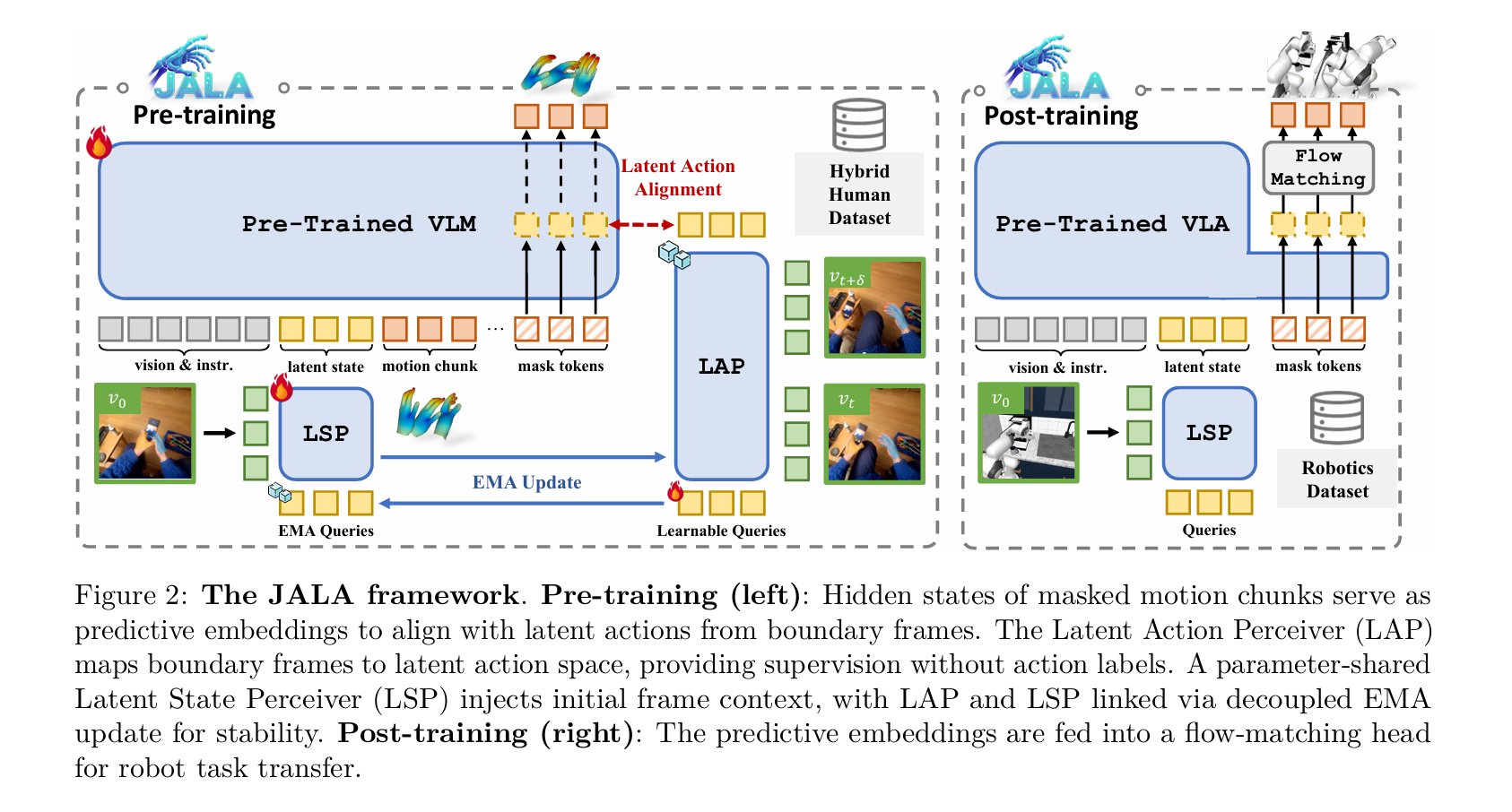
JALA则不是直接构建像素-动作之间的映射,而是直接把idm和vlm强耦合,用vlm hidden state做action对齐。有一个LAP(IDM,随机初始化)和LSP(vision encoder,不是随机初始化)。在训练的时候vla正常输入text rgb以及其他token,其中rgb token要经过LSP编码得到,经过vlm得到hidden token,projective后得到隐式动作表征z,然后LAP输入x1和x2,输出z',让两者做对齐。在更新的时候LSP通过EMA更新,其余组件正常梯度更新,这样完成pretrain后,vlm的hidden states本身就带有隐式action属性了。另外pretrain训练数据分成两类,一类是采集的mano数据,有action label,另一类是in the wild video;对于有action label的数据,会额外通过输出的z来预测真正的action,锚定真实的action空间。在sft阶段,丢掉LAP,在vlm后面接一个flow matching,然后直接预测动作即可。
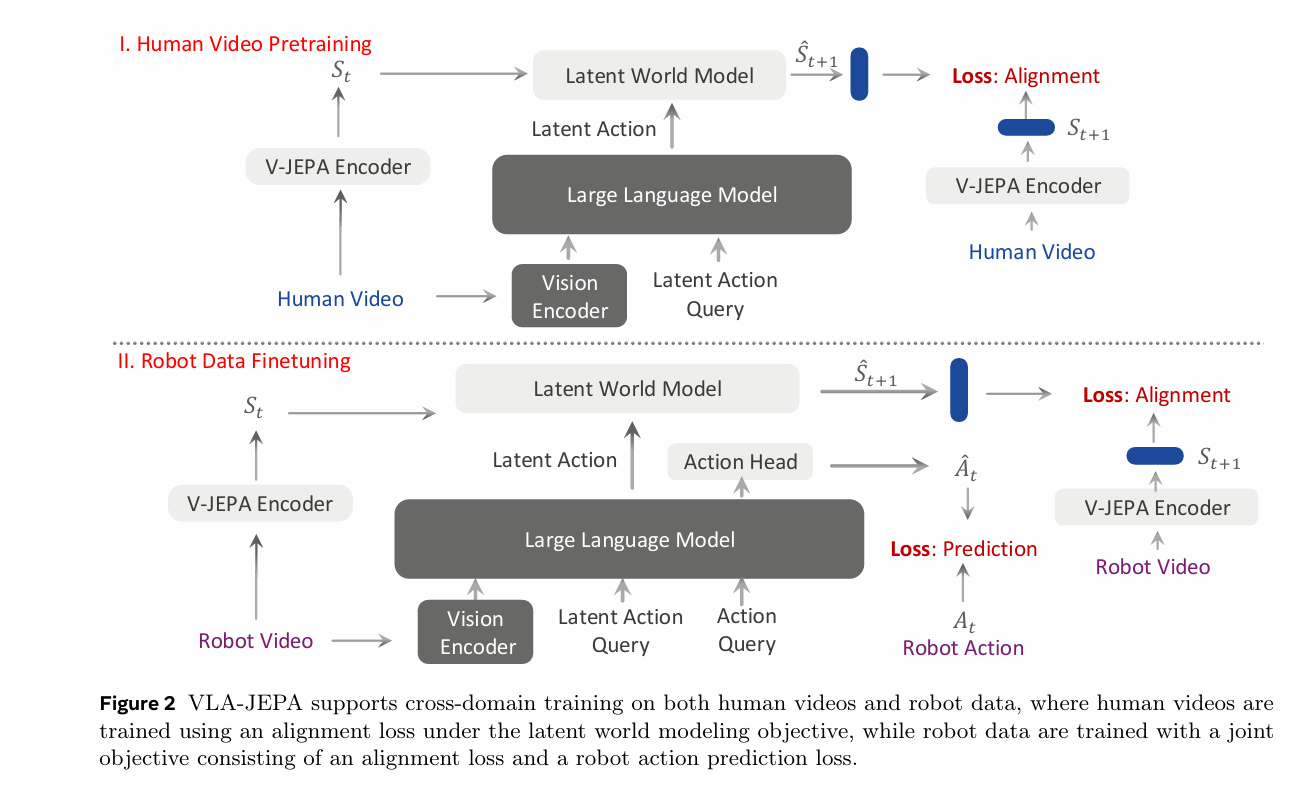
VLA-jepa则是利用v-jepa encoder,不像lapa那样直接预测像素空间,而是预测隐空间。
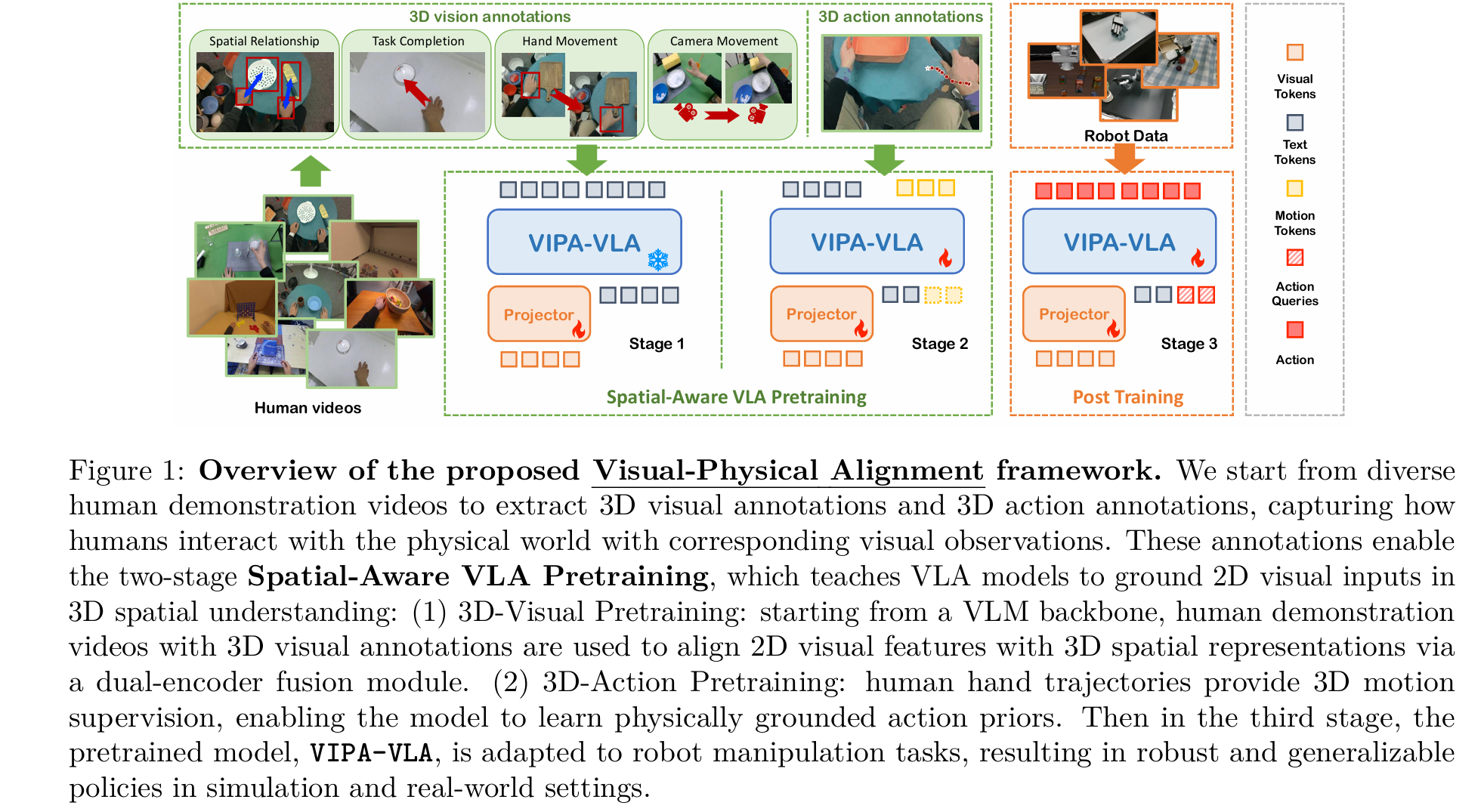
VIPA VLA cvpr 2026
使用3D信息来融入vla,而不是从2d rgb frame推理3d信息。3D编码器使用cut3r,多阶段对齐训练:
- 3D 视觉预训练:仅训练cut3r的projective layer,使用spatial vqa数据
- 3D 动作预训练:训练projective layer和backbone,引入motion token,使用action数据来尝试预测action
- post train:训练backbone和dit,仅使用少量数据在真机微调
Motion token是类似openvla的离散动作token(xyz+移动),在2阶段用于生成人手的动作(比如动作序列轨迹,end effector的traj),3阶段输入dit作为条件(相当于已经训练了一个粗轨迹出来了)。
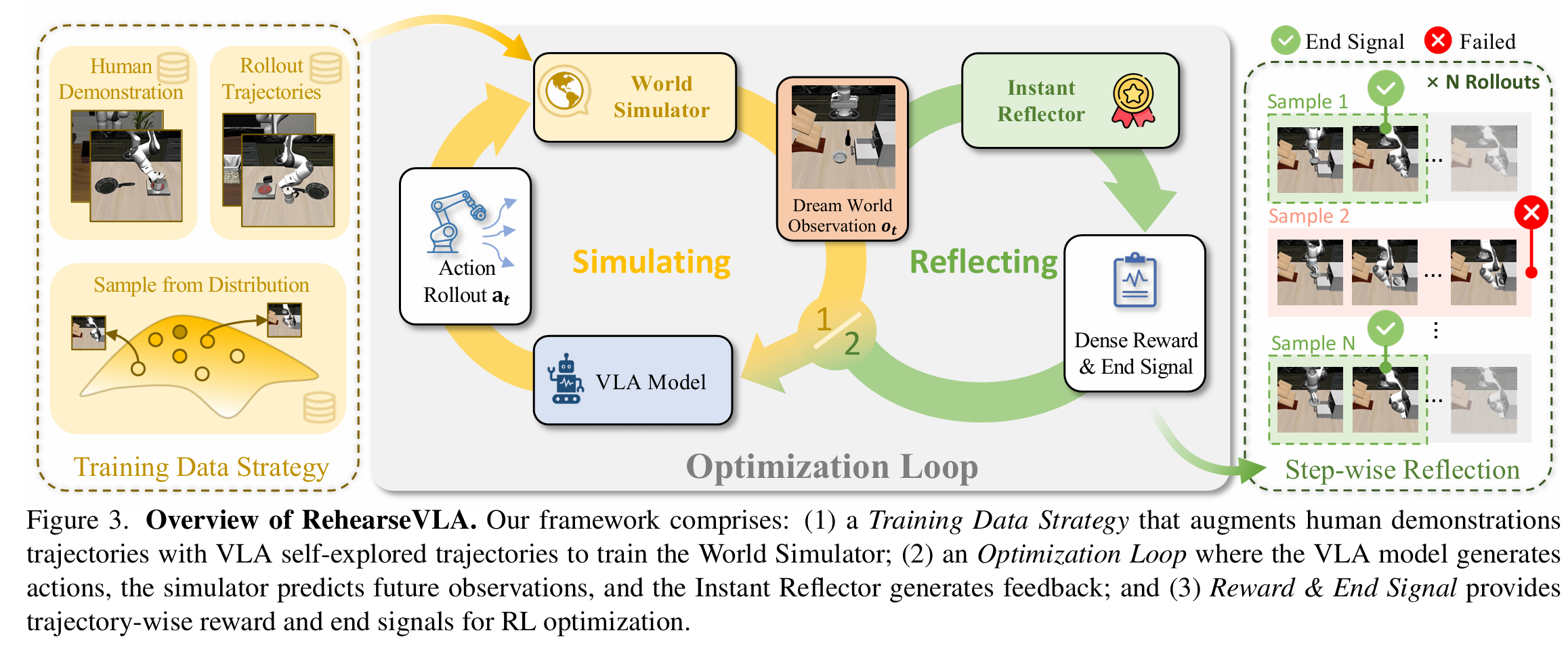
RehearseVLA cvpr 2026
用一个world model来负责模拟仿真环境,它接受action后输出future frame,当作一个simulator来用,做few shot vla。
仿真环境下有一个world model、Instant Reflector(判断vla是否结束,给出稠密的rl奖励,这和pi06的稀疏奖励不太一样)、Scale Head(vla模型判断当前的vla动作的不确定度)。当Scale Head大的时候,会在wm里探索更多的动作。然后再real world环境进行sft。
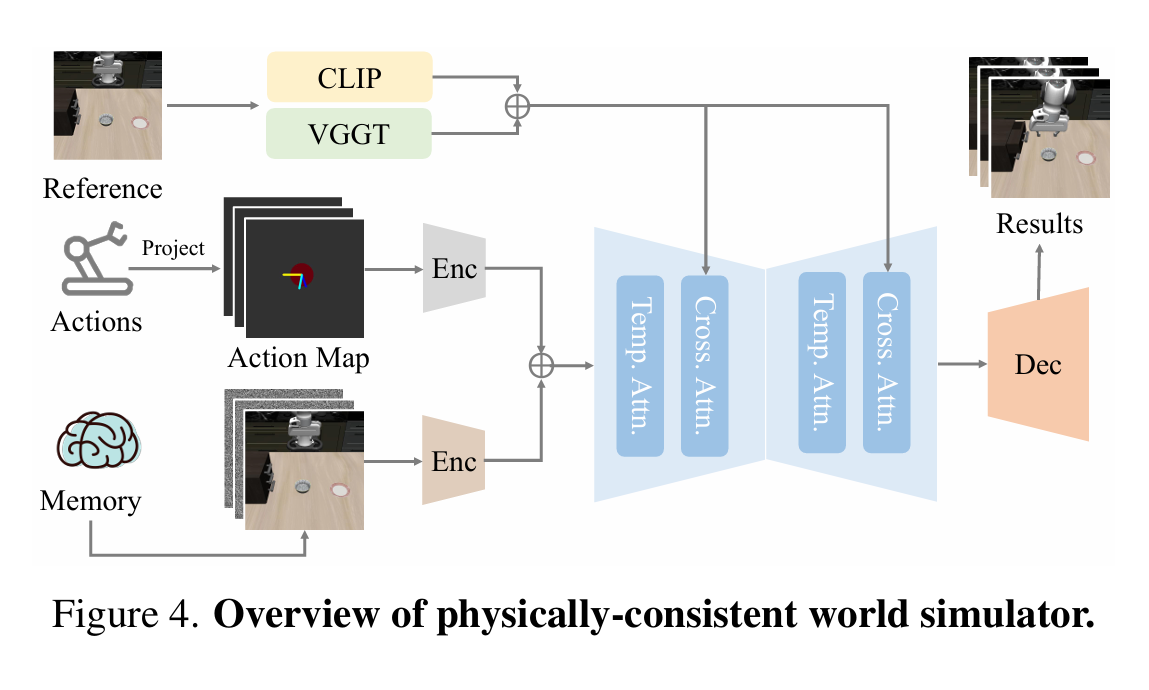
其中world model使用vggt+clip几何约束,就是构建了一个action+x0->x1的映射。
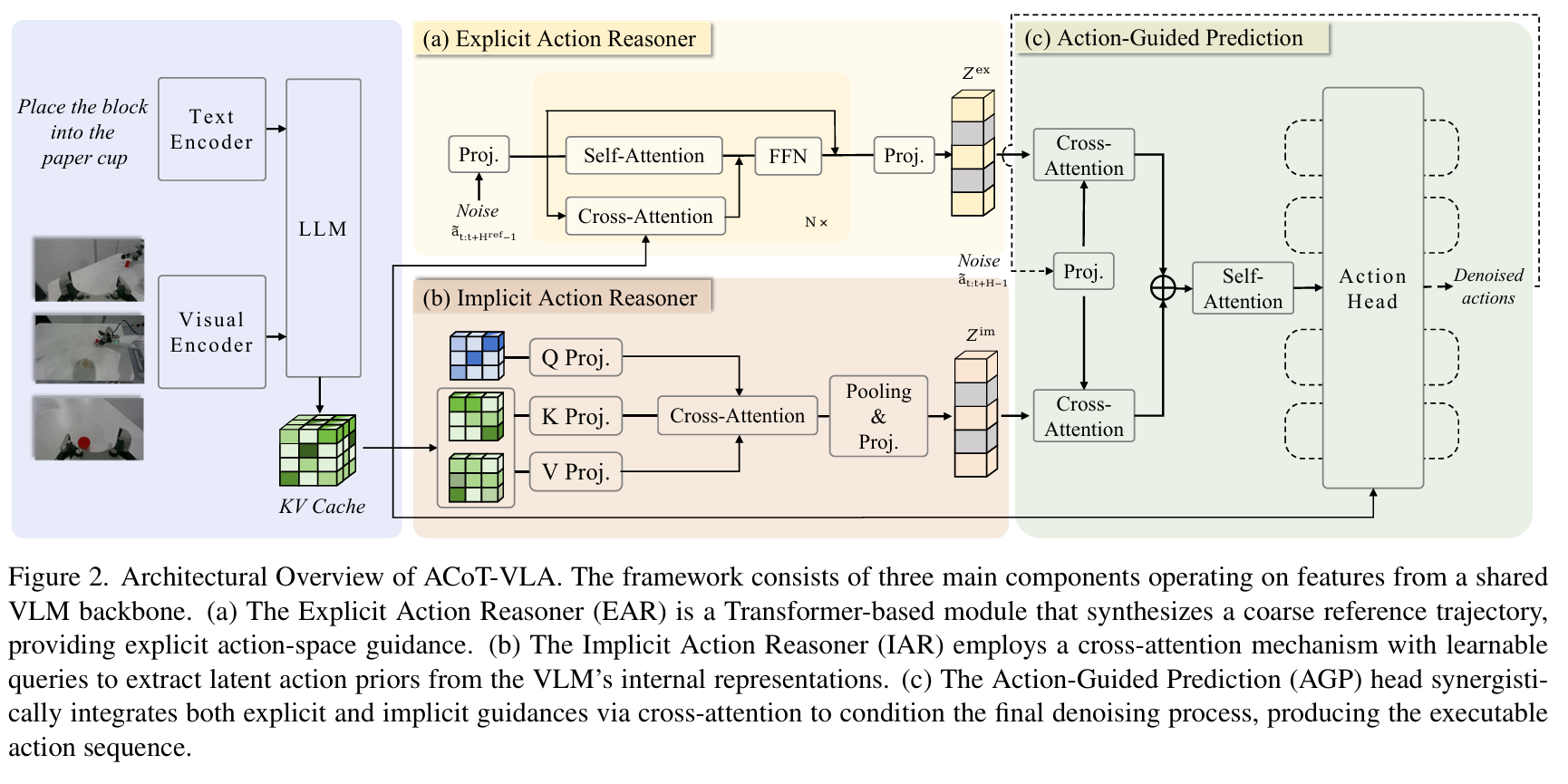
Acot vla cvpr 2026
在action空间进行cot推理,而不是像素空间或者文本空间。
IAR负责从图像文本的kv cache里提取隐式动作先验(类似llm 的hiddent status);EAR是一个带cross attention的dit,生成显示action traj cot(用gt action做监督);AGP融合二者信息出action。
训练的时候EAR因为随机初始化,所以ear的监督信号是独立的,agp用ear的gt作为输入。
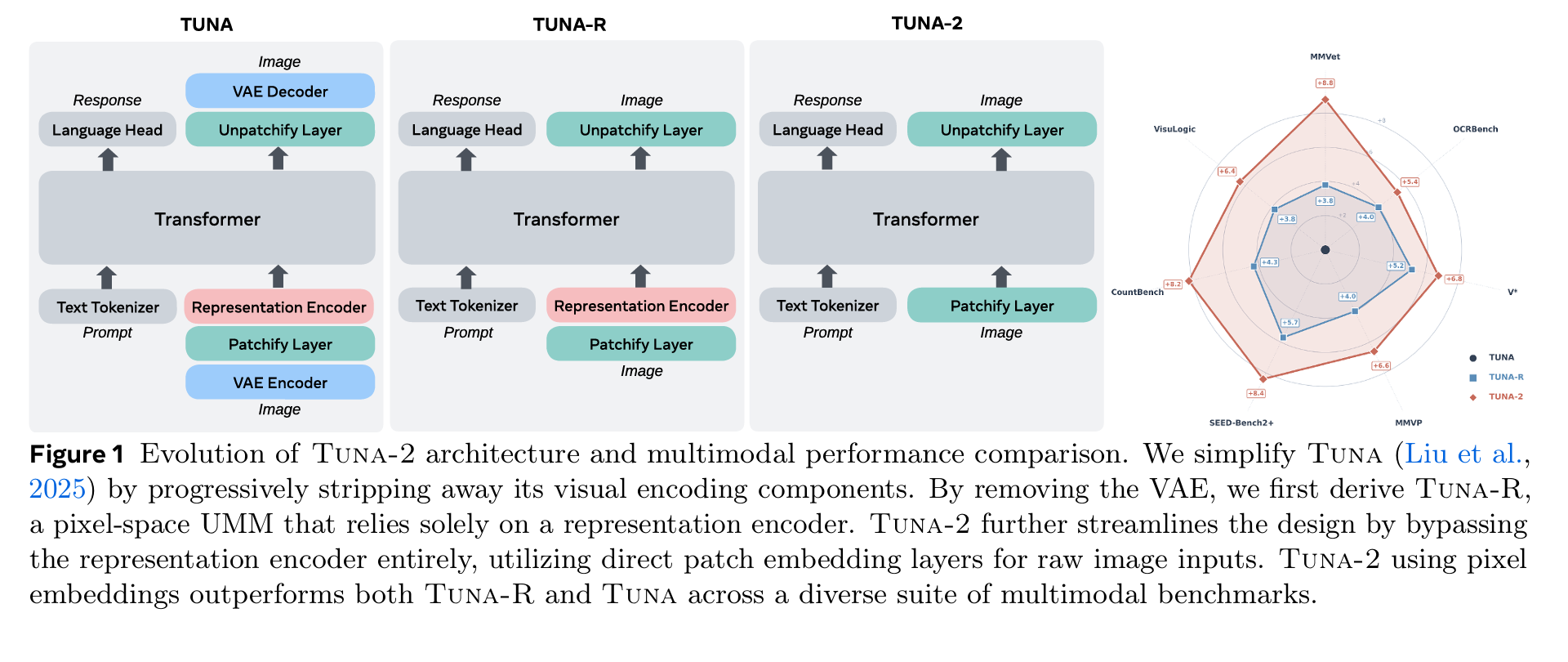
TUNA-2 cvpr 2026
统一多模态大模型,去掉了vae压缩生成和siglip的理解。直接对raw image切分patch编码后送入llm,llm直接通过一个flow matching在pixel space里做生成。
第一步先把vae去掉,raw image切分后用siglip一类编码器编码送入llm,llm也不在vae latent space做diffusion。第二步把siglip去掉,直接切分,然后projective layer进入llm。
这里因为直接在pixel space做diffusion,所以flow matching相关推导沿用jit的。在训练的时候用learnable mask强迫模型学习上下文。